في الآونة الأخيرة، كانت هناك موجة من المقاومة على وسائل التواصل الاجتماعي ضد استخدام Meta AI لبيانات المستخدم لتدريب النماذج، وقد أعلن العديد من المستخدمين معارضتهم علنًا، مما أثار مناقشات مكثفة حول خصوصية البيانات وتطبيق تكنولوجيا الذكاء الاصطناعي. سيقوم محرر Downcodes بإجراء تحليل متعمق لهذه الظاهرة ومناقشة الأسباب الكامنة وراءها، واستجابة Meta واتجاهات التطوير المستقبلية المحتملة.
في الآونة الأخيرة، كانت هناك موجة من وداع Meta AI على منصات التواصل الاجتماعي. قام العديد من المستخدمين، بما في ذلك المشاهير مثل Tom Brady والموسيقي Cat Power، بنشر بيانات على Instagram في محاولة لمنع Meta من استخدام بياناتهم لتدريب نماذج الذكاء الاصطناعي. وتعكس هذه الظاهرة المخاوف العميقة لدى المستخدمين بشأن خصوصية البيانات وتطبيق تكنولوجيا الذكاء الاصطناعي، كما تطرح تحديات جديدة أمام عمالقة التكنولوجيا في كيفية الموازنة بين الابتكار التكنولوجي وحقوق المستخدم.
على الرغم من أن هذه البيانات ليست ملزمة قانونًا، وقد أوضحت Meta أن هذه النصوص ليس لها أي أثر قانوني، إلا أنه لا يمكننا ببساطة رفض ذلك باعتباره جهلًا أو سذاجة من جانب المستخدم. بل على العكس من ذلك، فإن ما يعكسه هذا السلوك هو مخاوف المستخدمين بشأن التطور السريع لتكنولوجيا الذكاء الاصطناعي وخوفهم من إساءة استخدام البيانات الشخصية.
في الواقع، تستخدم Meta منشورات وصور عامة على Facebook يعود تاريخها إلى عام 2007 لتدريب نموذج الذكاء الاصطناعي الخاص بها. لدى المستخدمين خيارات قليلة لإلغاء الاشتراك ما لم يكونوا في الاتحاد الأوروبي، مما يؤدي بلا شك إلى تفاقم شعور المستخدمين بعدم الأمان. في هذه الحالة، لا يمكن للمستخدمين حماية بياناتهم إلا من خلال جعل المنشورات خاصة، وهو ما لا يعد حلاً مثاليًا.
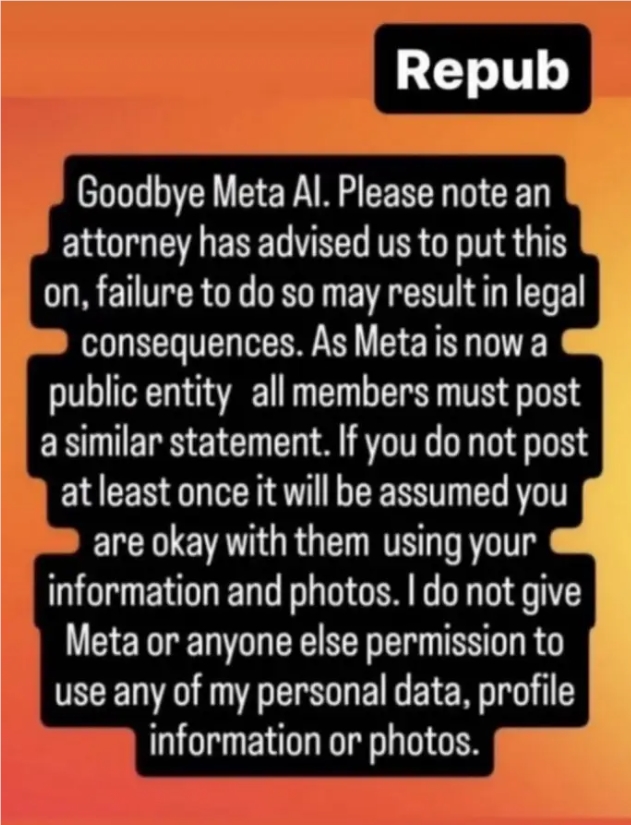
إن مثل هذه التصريحات الحمائية المنتشرة على وسائل التواصل الاجتماعي ليست جديدة. وظهر محتوى مماثل على فيسبوك وإنستغرام على مر السنين، بدعوى حماية المستخدمين من شركات التكنولوجيا. وعلى الرغم من أن هذه الادعاءات غالبًا ما تثبت عدم صحتها، إلا أنها تعكس اختلال توازن القوى الذي يشعر به المستخدمون عند استخدام هذه المنصات. يستمتع المستخدمون بالخدمات المجانية، ولكنهم يشعرون بالقلق من أن بياناتهم سيتم استخدامها بشكل غير صحيح. وينبع هذا التناقض من أخطاء فيسبوك المختلفة في حماية خصوصية المستخدم في الماضي.
عشية حدث Meta Connect القادم، سأل مراسل The Verge Alex Heath مارك زوكربيرج هذا السؤال مباشرة. وبدا رد زوكربيرج غامضا بعض الشيء، حيث ذكر أن أي مجال تكنولوجي جديد سيتضمن قضايا حدودية تتعلق بالاستخدام العادل والتحكم، وقال إن هذه القضايا تحتاج إلى إعادة مناقشتها وفحصها في عصر الذكاء الاصطناعي. تعترف هذه الاستجابة بوجود المشكلة ولكنها لا تقدم حلولاً ملموسة.
بالنسبة لشركة ميتا، فإن كيفية الموازنة بين الابتكار التكنولوجي وحماية حقوق المستخدم ستكون تحديًا شاقًا وطويل الأمد. تحتاج الشركات إلى الاستماع بعناية للمستخدمين وفهم مخاوفهم بشأن البيانات المستخدمة للتدريب على الذكاء الاصطناعي. وفي الوقت نفسه، تحتاج ميتا أيضًا إلى شرح سياسة استخدام البيانات الخاصة بها بشكل أكثر شفافية، حتى يتمكن المستخدمون من فهم كيفية استخدام بياناتهم بوضوح، وتوفير المزيد من الخيارات.
بالإضافة إلى ذلك، قد تحتاج الصناعة إلى إعادة النظر في المعايير الأخلاقية لاستخدام البيانات. في سياق التطور السريع للذكاء الاصطناعي، فإن كيفية استخدام بيانات المستخدم بشكل معقول وكيفية إيجاد توازن بين الابتكار وحماية الخصوصية هي قضايا تحتاج إلى حل عاجل.
وبشكل عام، تعكس هذه الموجة من "وداعا ميتا إيه آي" المخاوف العامة بشأن تطور تكنولوجيا الذكاء الاصطناعي وخصوصية البيانات، وتطرح أيضًا تحديات جديدة لشركات التكنولوجيا. وفي المستقبل، سوف تصبح كيفية تحقيق التوازن بين الابتكار التكنولوجي وحقوق المستخدم عاملاً رئيسياً في تحديد ما إذا كانت تكنولوجيا الذكاء الاصطناعي قادرة على التطور بشكل مستدام.