Recentemente, tem havido uma onda de resistência nas redes sociais contra o uso de dados de usuários pela Meta AI para treinar modelos. Muitos usuários declararam publicamente sua oposição, desencadeando extensas discussões sobre privacidade de dados e a aplicação da tecnologia de IA. O editor do Downcodes conduzirá uma análise aprofundada deste fenômeno e discutirá as razões por trás dele, a resposta do Meta e possíveis direções de desenvolvimento futuro.
Recentemente, houve uma onda de adeus ao Meta AI nas plataformas de mídia social. Vários usuários, incluindo celebridades como Tom Brady e o músico Cat Power, postaram declarações no Instagram na tentativa de impedir que Meta usasse seus dados para treinar modelos de IA. Este fenómeno reflecte as profundas preocupações dos utilizadores sobre a privacidade dos dados e a aplicação da tecnologia de IA, e também coloca novos desafios aos gigantes tecnológicos na forma de equilibrar a inovação tecnológica e os direitos dos utilizadores.
Embora estas declarações não sejam juridicamente vinculativas, e a Meta tenha deixado claro que estes textos não têm efeito jurídico, não podemos simplesmente descartar isto como ignorância ou ingenuidade por parte do utilizador. Pelo contrário, o que este comportamento reflecte são as preocupações dos utilizadores sobre o rápido desenvolvimento da tecnologia de IA e o seu medo da utilização indevida de dados pessoais.
Na verdade, o Meta usa postagens e fotos públicas do Facebook que datam de 2007 para treinar seu modelo de IA. Os utilizadores têm poucas opções de exclusão, a menos que estejam na UE, o que sem dúvida agrava as inseguranças dos utilizadores. Neste caso, os utilizadores só podem proteger os seus dados tornando as publicações privadas, o que obviamente não é a solução ideal.
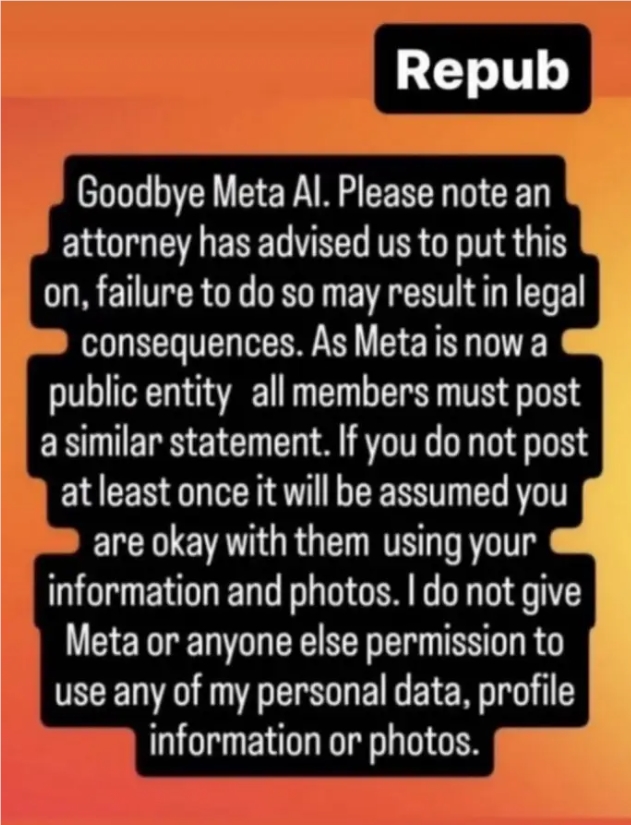
Tais declarações protetoras espalhadas nas redes sociais não são novidade. Conteúdo semelhante apareceu no Facebook e no Instagram ao longo dos anos, alegando proteger os usuários de empresas de tecnologia. Embora estas alegações muitas vezes se revelem inválidas, elas reflectem o desequilíbrio de poder que os utilizadores sentem quando utilizam estas plataformas. Os usuários desfrutam de serviços gratuitos, mas temem que seus dados sejam usados indevidamente. Essa ambivalência decorre de vários erros do Facebook na proteção da privacidade do usuário no passado.
Na véspera do próximo evento Meta Connect, o repórter do The Verge, Alex Heath, fez essa pergunta diretamente a Mark Zuckerberg. A resposta de Zuckerberg pareceu um pouco vaga. Ele mencionou que qualquer novo campo tecnológico envolverá questões de limites de uso justo e controle, e disse que essas questões precisam ser rediscutidas e examinadas na era da IA. Esta resposta reconhece a existência do problema, mas não oferece soluções concretas.
Para Meta, como equilibrar a inovação tecnológica e a protecção dos direitos dos utilizadores será um desafio árduo e de longo prazo. As empresas precisam ouvir atentamente os usuários e compreender suas preocupações sobre os dados usados para treinamento em IA. Ao mesmo tempo, Meta também precisa explicar sua política de uso de dados de forma mais transparente, para que os usuários possam entender claramente como seus dados serão usados e fornecer mais opções.
Além disso, a indústria pode precisar rever os padrões éticos para o uso de dados. No contexto do rápido desenvolvimento da IA, como utilizar razoavelmente os dados dos utilizadores e como encontrar um equilíbrio entre inovação e protecção da privacidade são questões que precisam de ser resolvidas urgentemente.
Em suma, esta onda de “Adeus, Meta AI” reflete as preocupações públicas sobre o desenvolvimento da tecnologia de IA e da privacidade de dados, e também apresenta novos desafios para as empresas de tecnologia. No futuro, a forma de encontrar um equilíbrio entre a inovação tecnológica e os direitos dos utilizadores tornar-se-á um factor-chave para determinar se a tecnologia de IA pode desenvolver-se de forma sustentável.