AutoVocoder
1.0.0
การใช้งาน pytorch อย่างไม่เป็นทางการของ autovocoder: การสร้างรูปคลื่นที่รวดเร็วจากการแสดงคำพูดที่เรียนรู้โดยใช้การประมวลผลสัญญาณดิจิตอลที่แตกต่างกัน ที่เก็บนี้ขึ้นอยู่กับ istftnet GitHub (กระดาษ)
Disclaimer : This repo is built for testing purpose.
python train.py --config config.json
ใน train.py , Change --input_wavs_dir ไปยังไดเรกทอรีของ ljspeech-1.1/wavs
ใน config.json ให้เปลี่ยน latent_dim สำหรับ AV128 , AV192 และ AV256 (ค่าเริ่มต้น)
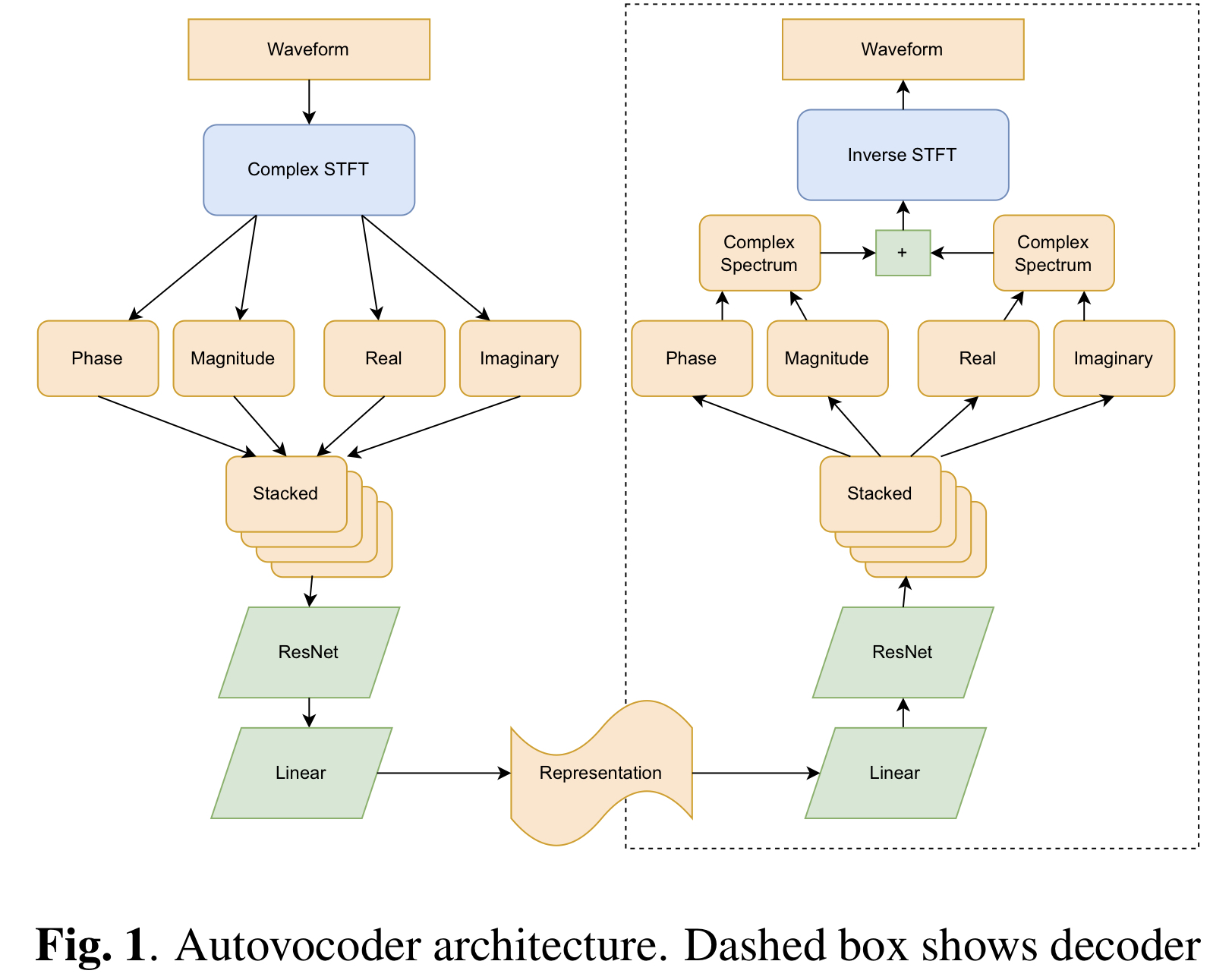
เมื่อพิจารณา Section 3.3 คุณสามารถเลือก dec_istft_input ระหว่าง cartesian (ค่าเริ่มต้น) polar และ both
การตรวจสอบการสูญเสีย AV256 ในระหว่างการฝึกอบรม
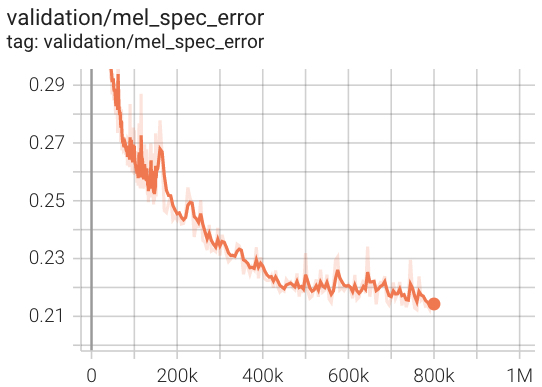
ในการทดสอบของเรามันมาบรรจบกันเร็วกว่า HIFI-V1 เกือบ 3 เท่า (หมายถึง repo อย่างเป็นทางการ)
@article{Webber2022AutovocoderFW,
title={Autovocoder: Fast Waveform Generation from a Learned Speech Representation using Differentiable Digital Signal Processing},
author={Jacob J. Webber and Cassia Valentini-Botinhao and Evelyn Williams and Gustav Eje Henter and Simon King},
journal={ArXiv},
year={2022},
volume={abs/2211.06989}
}


