AutoVocoder
1.0.0
Implementação não oficial de pytorch do autovocoder: geração rápida da forma de onda a partir de uma representação de fala aprendida usando processamento de sinal digital diferenciável. Este repositório é baseado no iStftNet Github (papel) .
Disclaimer : This repo is built for testing purpose.
python train.py --config config.json
Em train.py , altere --input_wavs_dir para o diretório de LJSpeech-1.1/wavs.
Em config.json , altere latent_dim para AV128 , AV192 e AV256 (padrão).
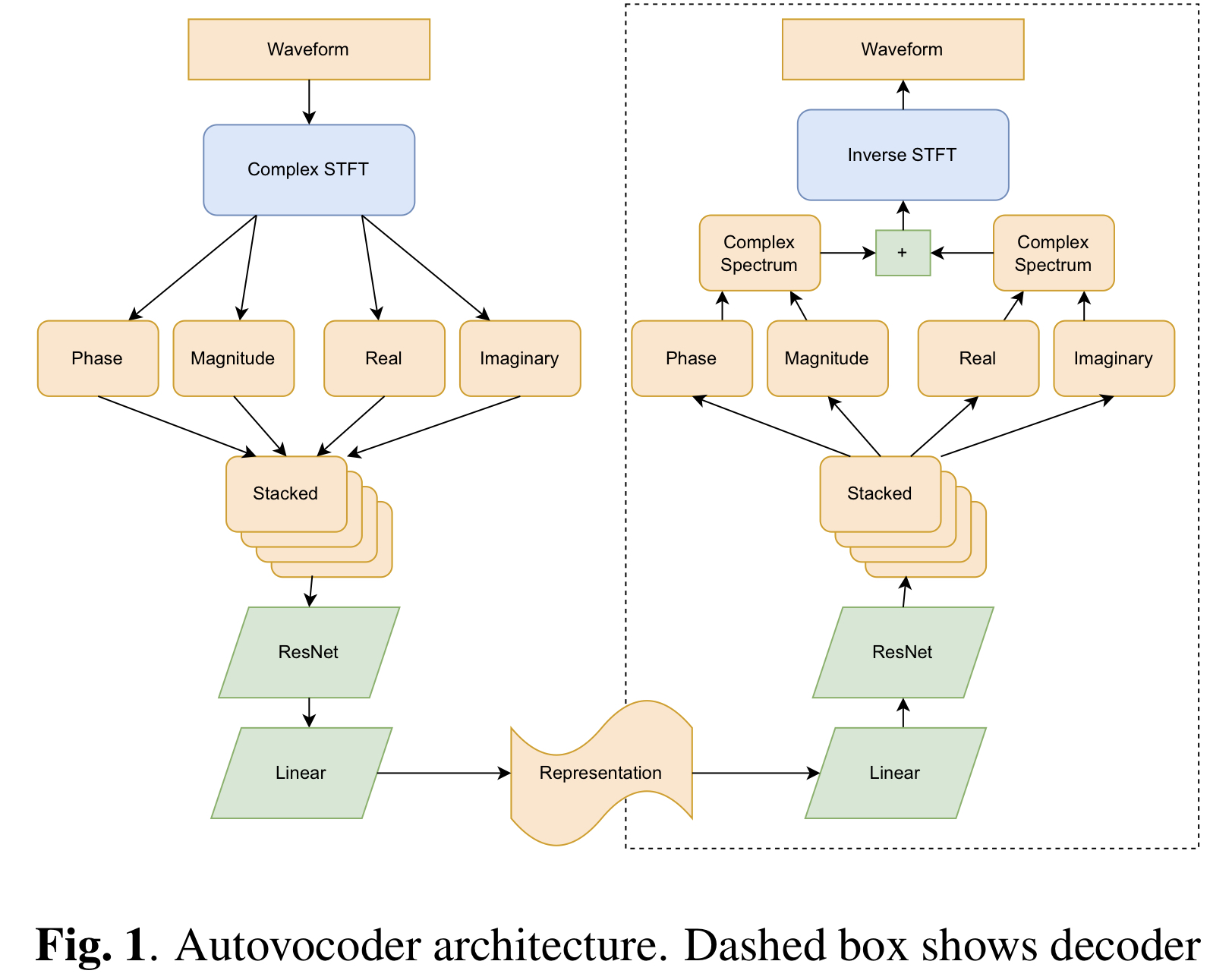
Considerando Section 3.3 , você pode selecionar dec_istft_input entre cartesian (padrão), polar e both .
Perda de validação do AV256 durante o treinamento.
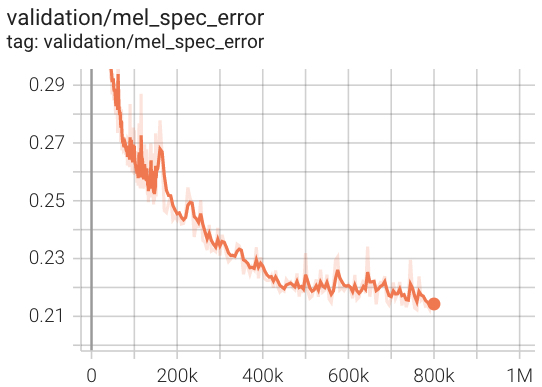
Em nosso teste, ele converge quase 3x vezes mais rápido que o HIFI-V1 (referindo-se ao repositório oficial).
@article{Webber2022AutovocoderFW,
title={Autovocoder: Fast Waveform Generation from a Learned Speech Representation using Differentiable Digital Signal Processing},
author={Jacob J. Webber and Cassia Valentini-Botinhao and Evelyn Williams and Gustav Eje Henter and Simon King},
journal={ArXiv},
year={2022},
volume={abs/2211.06989}
}


