AutoVocoder
1.0.0
Inoffizielle Pytorch -Implementierung von Autovocoder: Erzeugung der schnellen Wellenform aus einer gelernten Sprachdarstellung unter Verwendung einer differenzierbaren digitalen Signalverarbeitung. Dieses Repository basiert auf iStftnet Github (Papier) .
Disclaimer : This repo is built for testing purpose.
python train.py --config config.json
In train.py , ändern Sie --input_wavs_dir in das Verzeichnis von ljspeech-1.1/WAVs.
Ändern Sie in config.json latent_dim für AV128 , AV192 und AV256 (Standard).
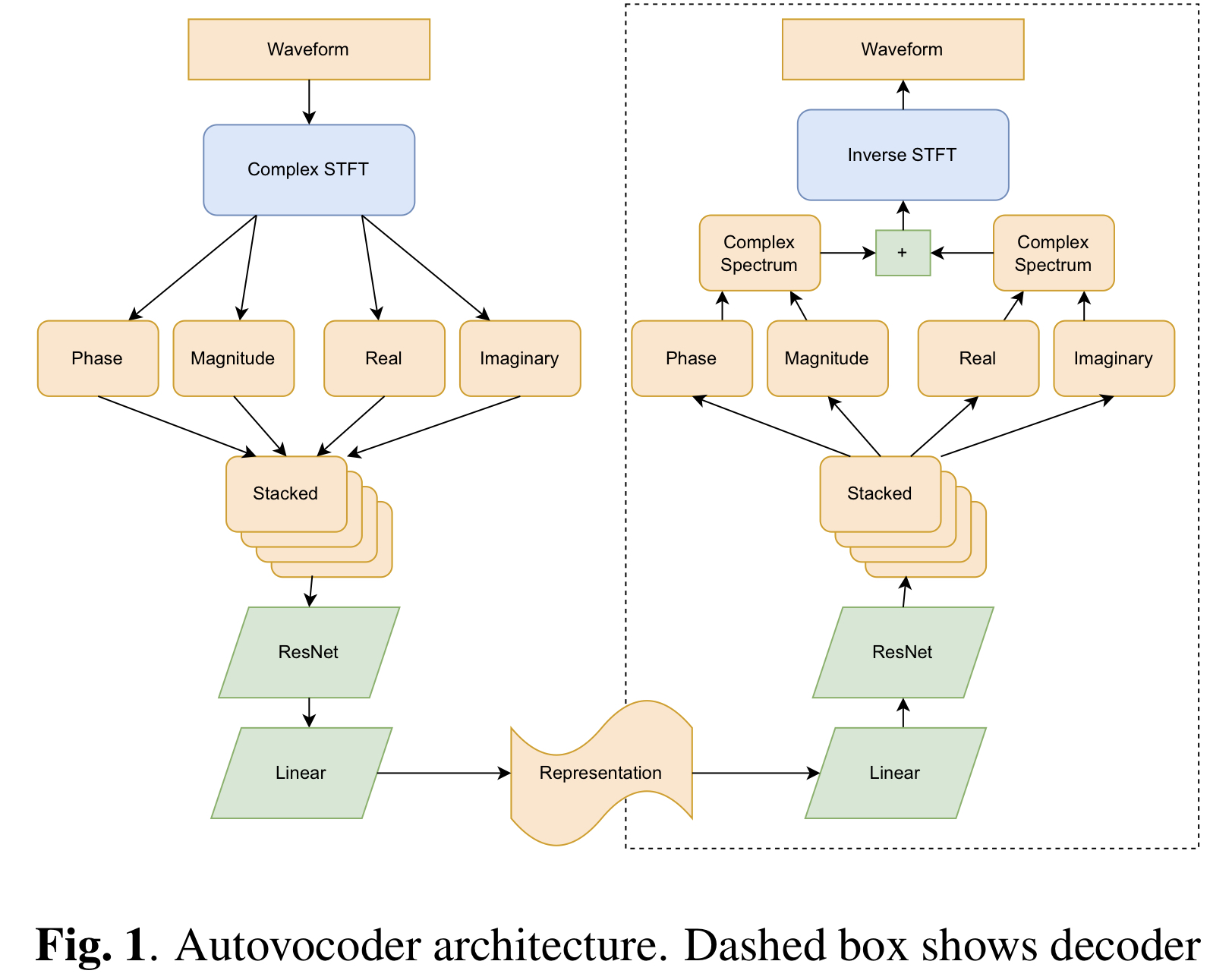
Wenn Sie Section 3.3 berücksichtigen, können Sie zwischen cartesian (Standard), polar und both dec_istft_input .
Validierungsverlust von AV256 während des Trainings.
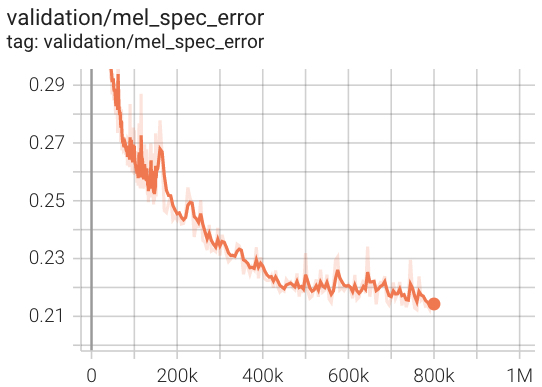
In unserem Test konvergiert es fast dreimal schneller als Hifi-V1 (unter Bezugnahme auf das offizielle Repo).
@article{Webber2022AutovocoderFW,
title={Autovocoder: Fast Waveform Generation from a Learned Speech Representation using Differentiable Digital Signal Processing},
author={Jacob J. Webber and Cassia Valentini-Botinhao and Evelyn Williams and Gustav Eje Henter and Simon King},
journal={ArXiv},
year={2022},
volume={abs/2211.06989}
}


