AutoVocoder
1.0.0
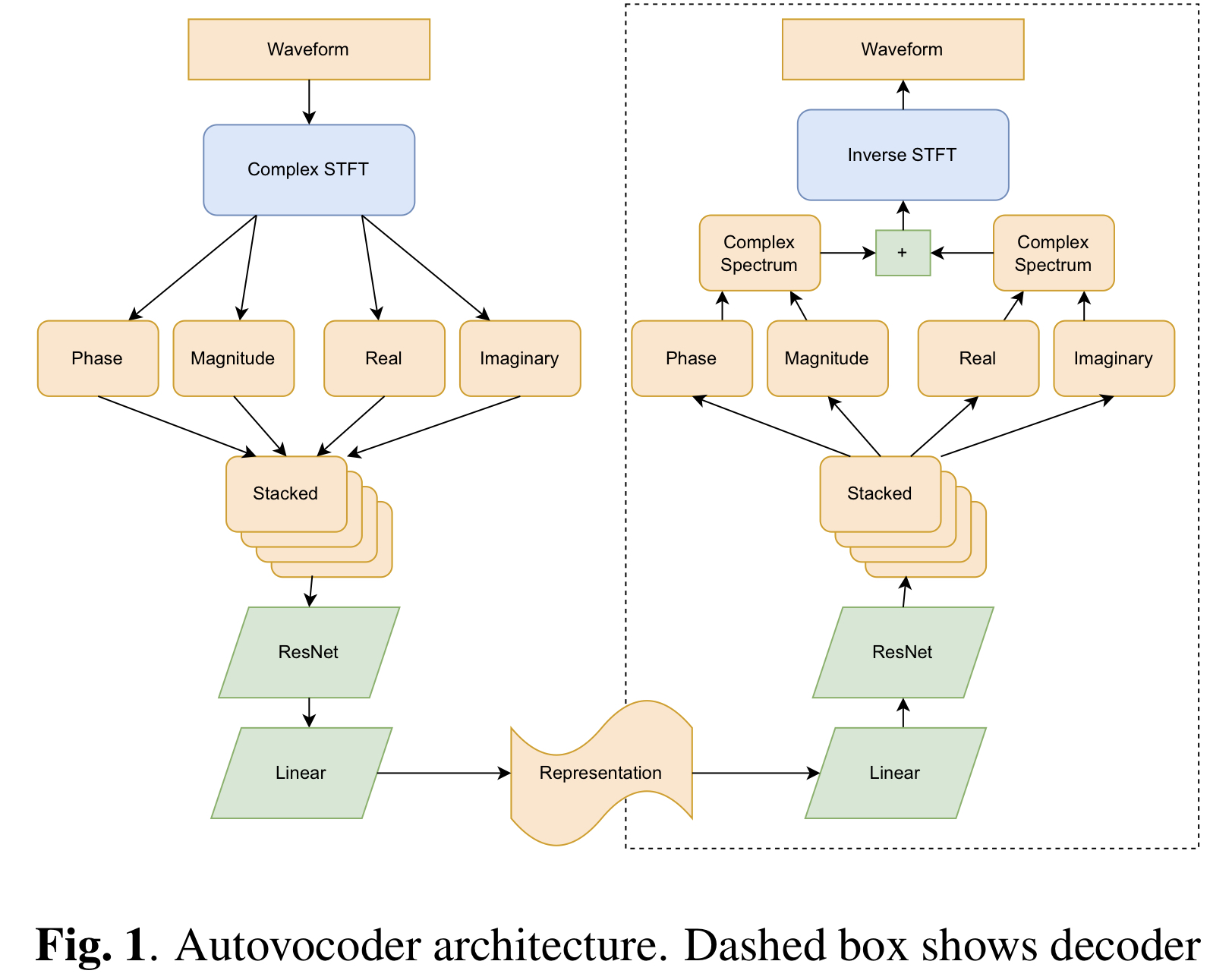
Autovocoder의 비공식 Pytorch 구현 : 차별화 가능한 디지털 신호 처리를 사용한 학습 된 음성 표현에서 빠른 파형 생성. 이 저장소는 istftnet github (종이)을 기반으로합니다.
Disclaimer : This repo is built for testing purpose.
python train.py --config config.json
train.py 에서는 change --input_wavs_dir ljspeech-1.1/wavs 디렉토리로.
config.json 에서 AV128 , AV192 및 AV256 의 latent_dim (기본값)을 변경하십시오.
Section 3.3 고려하면 cartesian (기본값), polar 및 both 사이에서 dec_istft_input 선택할 수 있습니다.
훈련 중 AV256 의 검증 손실.
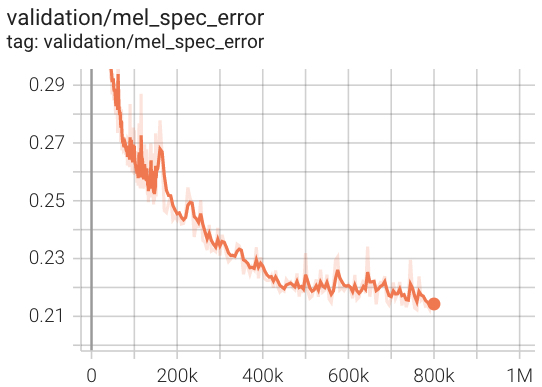
우리의 시험에서, 그것은 Hifi-V1보다 거의 3 배 빠르게 수렴합니다 (공식 리포를 참조).
@article{Webber2022AutovocoderFW,
title={Autovocoder: Fast Waveform Generation from a Learned Speech Representation using Differentiable Digital Signal Processing},
author={Jacob J. Webber and Cassia Valentini-Botinhao and Evelyn Williams and Gustav Eje Henter and Simon King},
journal={ArXiv},
year={2022},
volume={abs/2211.06989}
}


