AutoVocoder
1.0.0
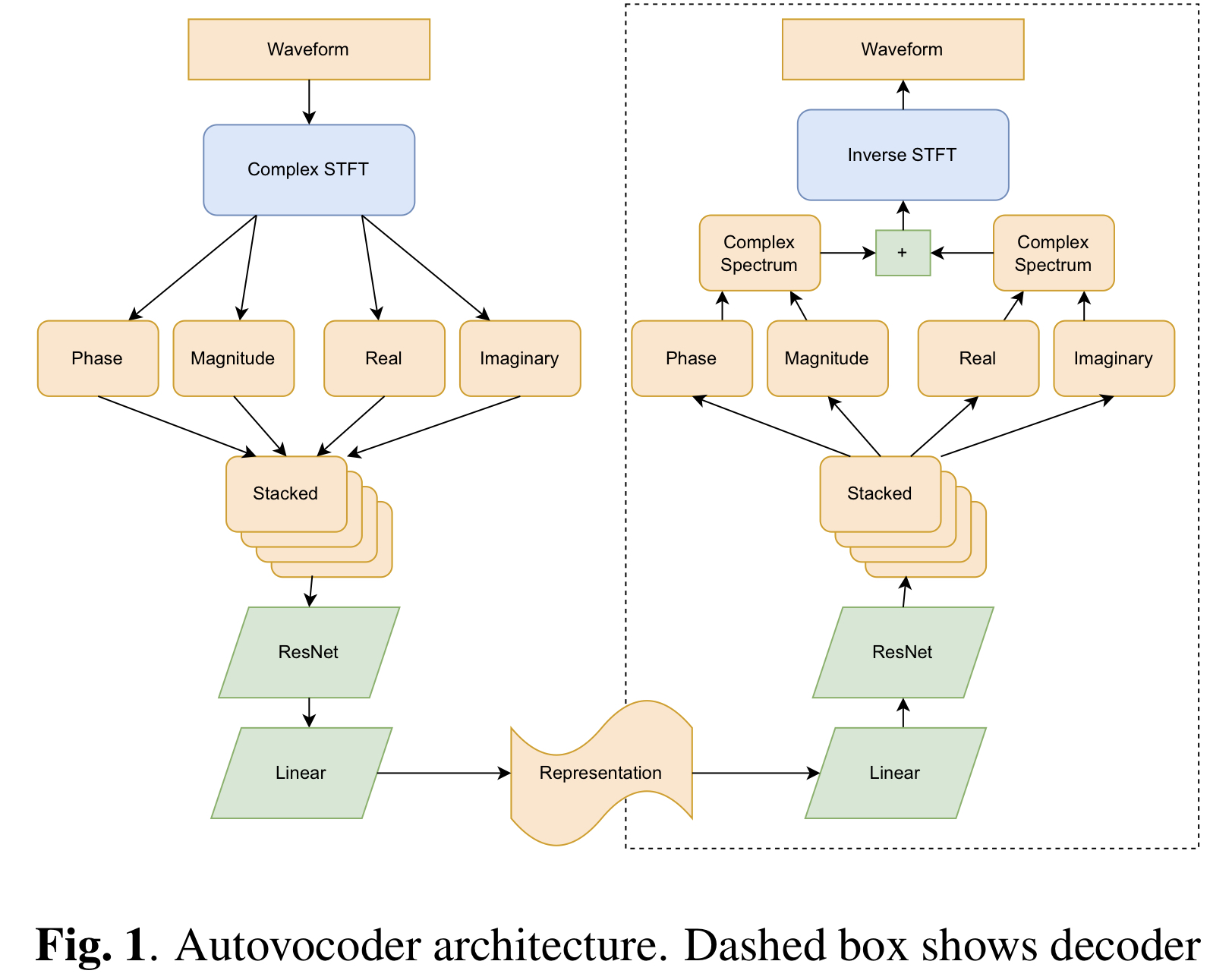
Implémentation non officielle de Pytorch d'AutoVoCoder: génération de forme d'onde rapide à partir d'une représentation de la parole apprise en utilisant un traitement de signal numérique différente. Ce référentiel est basé sur ISTFTNET GitHub (papier) .
Disclaimer : This repo is built for testing purpose.
python train.py --config config.json
Dans train.py , changez --input_wavs_dir au répertoire de LJSpeech-1.1 / Wavs.
Dans config.json , modifiez latent_dim pour AV128 , AV192 et AV256 (par défaut).
Compte tenu de Section 3.3 , vous pouvez sélectionner dec_istft_input entre cartesian (par défaut), polar et both .
Perte de validation de AV256 pendant la formation.
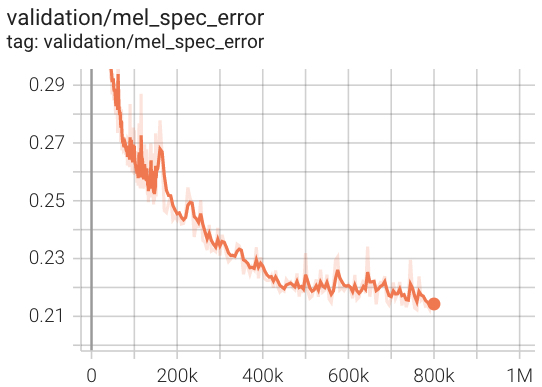
Dans notre test, il converge presque 3x fois plus rapide que HIFI-V1 (se référant au dépôt officiel).
@article{Webber2022AutovocoderFW,
title={Autovocoder: Fast Waveform Generation from a Learned Speech Representation using Differentiable Digital Signal Processing},
author={Jacob J. Webber and Cassia Valentini-Botinhao and Evelyn Williams and Gustav Eje Henter and Simon King},
journal={ArXiv},
year={2022},
volume={abs/2211.06989}
}


