One Click MB iSTFT VITS2
1.0.0
เครื่องมือนี้ช่วยให้คุณสามารถทำกระบวนการทั้งหมดของ MB-ISTFT-VITS2 (การประมวลผลข้อมูลล่วงหน้า + Whisper ASR + TEXT Preprocessing + Modification Config.json + การฝึกอบรมการอนุมาน) ด้วยคลิกเดียว!
16GB12GBคำสั่งการติดตั้ง Pytorch:
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117 CUDA 11.7 ติดตั้ง: https://developer.nvidia.com/cuda-11-7-0-download-archive
zlib dll ติดตั้ง: https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html#install-zlib-windows
ติดตั้ง pyopenjtalk ด้วยตนเอง: pip install -U pyopenjtalk --no-build-isolation
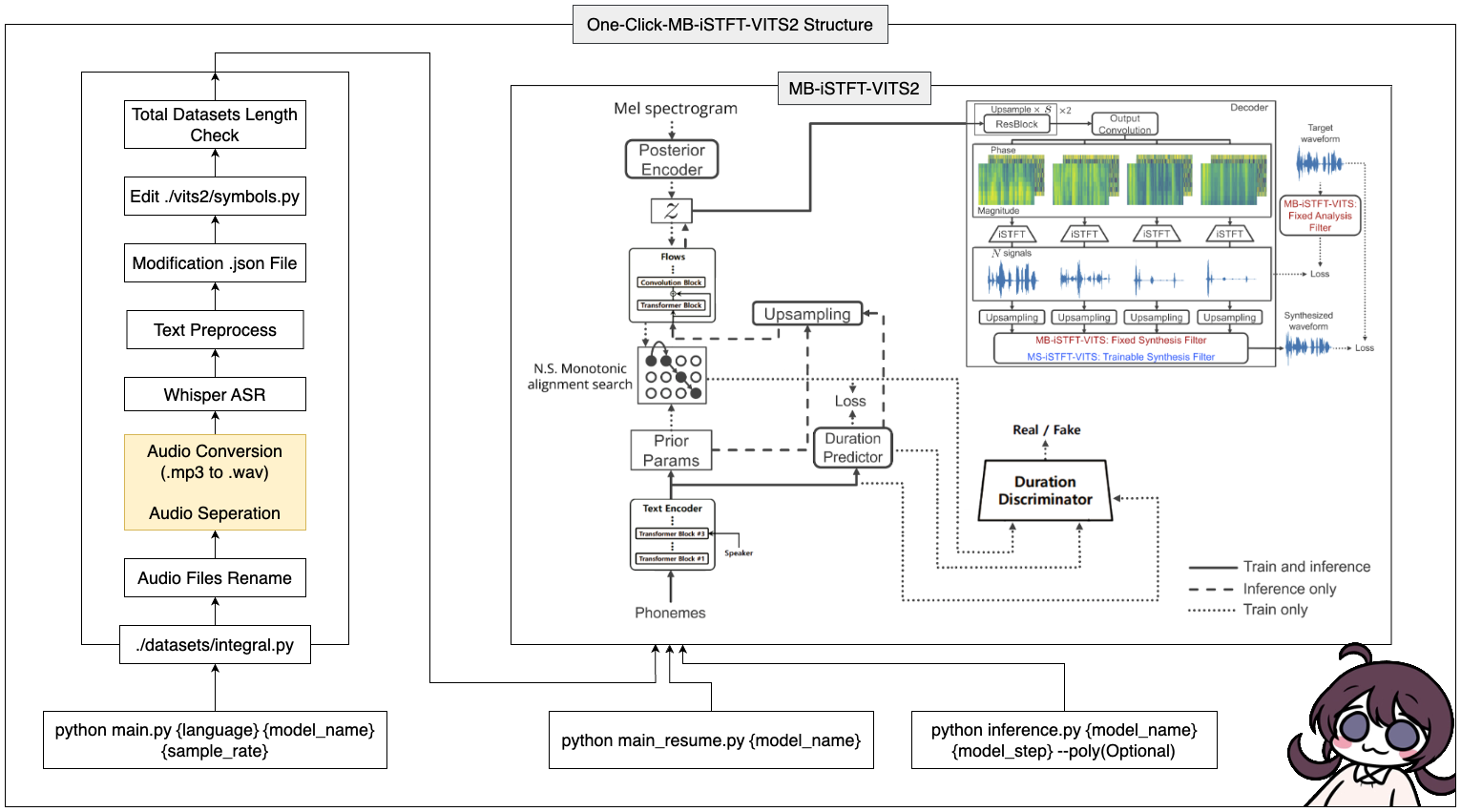
conda create -n vits2 python=3.8conda activate vits2git clone https://github.com/ORI-Muchim/One-Click-MB-iSTFT-VITS2.git cd One-Click-MB-iSTFT-VITS2pip install -r requirements.txtวางไฟล์เสียงดังนี้
.mp3 หรือ. wav ไฟล์ก็โอเค
One-Click-MB-iSTFT-VITS2
├────datasets
│ ├───speaker0
│ │ ├────1.mp3
│ │ └────1.wav
│ └───speaker1
│ │ ├───1.mp3
│ │ └───1.wav
│ ├integral.py
│ └integral_low.py
│
├────vits2
├────inference.py
├────main_low.py
├────main_resume.py
├────main.py
├────Readme.md
└────requirements.txt
นี่เป็นเพียงตัวอย่างและมันก็โอเคที่จะเพิ่มลำโพงมากขึ้น
ในการเริ่มต้นเครื่องมือนี้ให้ใช้คำสั่งต่อไปนี้แทนที่ {ภาษา}, {model_name} และ {sample_rate} ด้วยค่าที่เกี่ยวข้องของคุณ ({ภาษา: ko, ja, en, zh} / {sample_rate: 22050 /44100}):
python main.py {language} {model_name} {sample_rate}สำหรับผู้ที่มีข้อกำหนดต่ำ (VRAM <= 16GB) โปรดใช้รหัสนี้:
python main_low.py {language} {model_name} {sample_rate}หากการกำหนดค่าข้อมูลเสร็จสมบูรณ์และคุณต้องการฝึกอบรมต่อให้ป้อนรหัสนี้:
python main_resume.py {model_name}หลังจากได้รับการฝึกอบรมแบบจำลองแล้วคุณสามารถสร้างการคาดการณ์ได้โดยใช้คำสั่งต่อไปนี้แทนที่ {model_name} และ {model_step} ด้วยค่าที่เกี่ยวข้องของคุณ:
python inference.py {model_name} {model_step} --poly(Optional) หากคุณเลือก cjke_cleaners2 (en, zh) ให้ใส่ -ตัวเลือก --poly ที่ด้านหลัง
หากคุณต้องการเปลี่ยนข้อความตัวอย่างที่ใช้ในการอ้างอิงให้แก้ไข ./vits/inference.py ส่วน input
ในที่เก็บของ Cjangcjengh/Vits ฉันได้ทำการปรับเปลี่ยนวิธีการทำความสะอาดข้อความเกาหลี กระบวนการทำความสะอาดอื่น ๆ นั้นเหมือนกันโดยโพสต์ลงในที่เก็บ Cjangcjengh แต่ไฟล์ทำความสะอาดได้รับการแก้ไขโดยใช้ไลบรารี Tenebo/G2PK2 เป็นภาษาเกาหลี
สำหรับข้อมูลเพิ่มเติมโปรดดูที่เก็บต่อไปนี้:


