One Click MB iSTFT VITS2
1.0.0
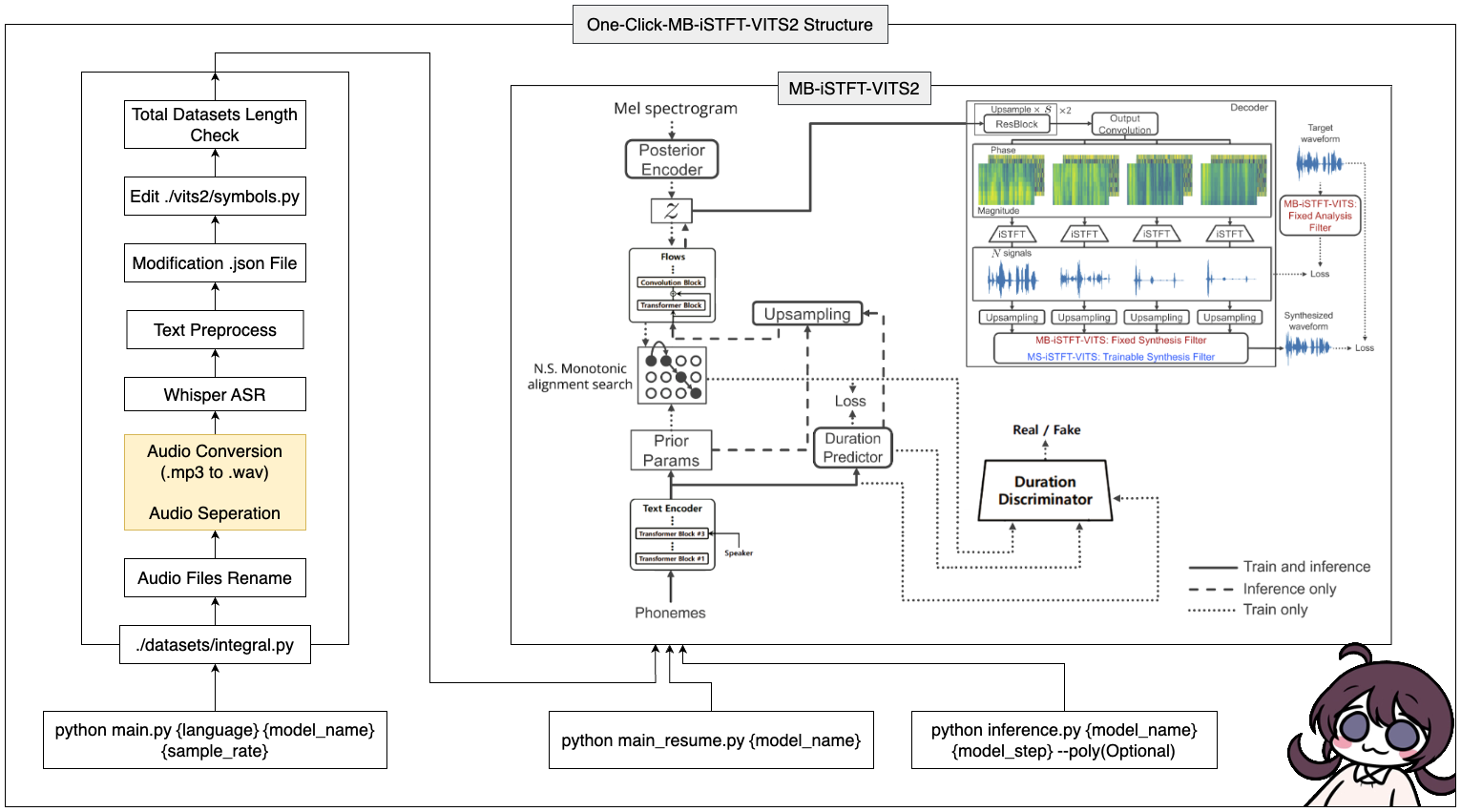
이 도구는 원 클릭을 사용한 MB-ISTFT-VITS2 (데이터 전처리 + Whisper ASR + 텍스트 전처리 + 수정 구성)의 전체 프로세스를 완료 할 수 있습니다!
16GB RAM의 Windows/Linux 시스템.12GB 이상의 VRAM을 가진 GPU.Pytorch 설치 명령 :
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117 CUDA 11.7 설치 : https://developer.nvidia.com/cuda-11-7-0-download-archive
Zlib DLL 설치 : https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html#install-zlib-windows
pyopenjtalk를 수동으로 설치하십시오 : pip install -U pyopenjtalk --no-build-isolation
conda create -n vits2 python=3.8conda activate vits2git clone https://github.com/ORI-Muchim/One-Click-MB-iSTFT-VITS2.git cd One-Click-MB-iSTFT-VITS2pip install -r requirements.txt오디오 파일을 다음과 같이 배치하십시오.
.mp3 또는 .wav 파일은 괜찮습니다.
One-Click-MB-iSTFT-VITS2
├────datasets
│ ├───speaker0
│ │ ├────1.mp3
│ │ └────1.wav
│ └───speaker1
│ │ ├───1.mp3
│ │ └───1.wav
│ ├integral.py
│ └integral_low.py
│
├────vits2
├────inference.py
├────main_low.py
├────main_resume.py
├────main.py
├────Readme.md
└────requirements.txt
이것은 단지 예일 뿐이며 더 많은 스피커를 추가해도 괜찮습니다.
이 도구를 시작하려면 다음 명령을 사용하여 {language}, {model_name} 및 {sample_rate}를 각각의 값 ({language : ko, ja, en, zh} / {sample_rate : 22050 / 44100})로 바꿉니다.
python main.py {language} {model_name} {sample_rate}사양이 낮은 사람 (VRAM <= 16GB)의 경우이 코드를 사용하십시오.
python main_low.py {language} {model_name} {sample_rate}데이터 구성이 완료되고 교육을 재개하려면이 코드를 입력하십시오.
python main_resume.py {model_name}모델이 교육을받은 후 다음 명령을 사용하여 {model_name} 및 {model_step}을 각각의 값으로 대체하여 예측을 생성 할 수 있습니다.
python inference.py {model_name} {model_step} --poly(Optional) CJKE_CLEANERS2 (en, ZH)를 선택한 경우 --poly 옵션을 뒷면에 넣으십시오.
참조에 사용 된 예제 텍스트를 변경하려면 ./vits/inference.py input 부분을 수정하십시오.
cjangcjengh/vits의 저장소에서 한국 텍스트 청소 방법을 수정했습니다. 다른 청소 과정은 Cjangcjengh 저장소에 게시하여 동일하지만 클리너 파일은 한국인으로 Tenebo/G2PK2 라이브러리를 사용하여 수정되었습니다.
자세한 내용은 다음 저장소를 참조하십시오.


