One Click MB iSTFT VITS2
1.0.0
Этот инструмент позволяет вам завершить весь процесс MB-ISTFT-Vits2 (предварительная обработка данных + Whisper ASR + Text Preprocessing + Modiation Config.json + Training, вывод) с одним щелчком!
16GB оперативной памяти.12GB VRAM.Команда установки Pytorch:
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117 Cuda 11.7 Установка: https://developer.nvidia.com/cuda-11-7-0-download-archive
Zlib DLL Установка: https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html#install-zlib-windows
Установите Pyopenjtalk вручную: pip install -U pyopenjtalk --no-build-isolation
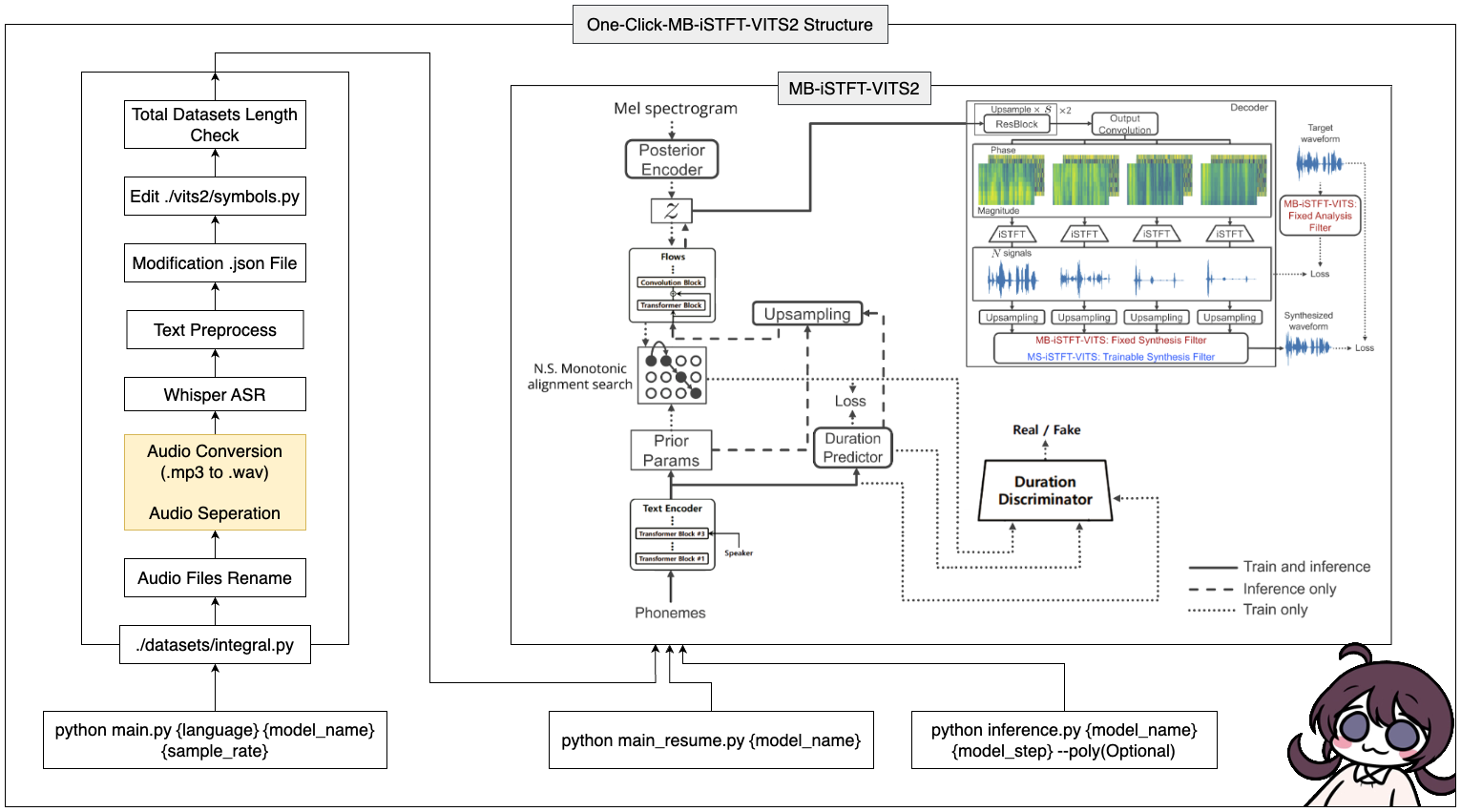
conda create -n vits2 python=3.8conda activate vits2git clone https://github.com/ORI-Muchim/One-Click-MB-iSTFT-VITS2.git cd One-Click-MB-iSTFT-VITS2pip install -r requirements.txtПоместите аудиофайлы следующим образом.
.mp3 или .wav файлы в порядке.
One-Click-MB-iSTFT-VITS2
├────datasets
│ ├───speaker0
│ │ ├────1.mp3
│ │ └────1.wav
│ └───speaker1
│ │ ├───1.mp3
│ │ └───1.wav
│ ├integral.py
│ └integral_low.py
│
├────vits2
├────inference.py
├────main_low.py
├────main_resume.py
├────main.py
├────Readme.md
└────requirements.txt
Это всего лишь пример, и можно добавить больше динамиков.
Чтобы запустить этот инструмент, используйте следующую команду, заменив {language}, {model_name} и {sample_rate} на ваши соответствующие значения ({язык: ko, ja, en, zh} / {sample_rate: 22050 /44100}):
python main.py {language} {model_name} {sample_rate}Для тех, кто имеет низкие характеристики (VRAM <= 16 ГБ), используйте этот код:
python main_low.py {language} {model_name} {sample_rate}Если конфигурация данных завершена, и вы хотите возобновить обучение, введите этот код:
python main_resume.py {model_name}После обучения модели вы можете генерировать прогнозы, используя следующую команду, заменив {model_name} и {model_step} с вашими соответствующими значениями:
python inference.py {model_name} {model_step} --poly(Optional) Если вы выбрали CJKE_CLEANERS2 (en, ZH), положите опцию --poly сзади.
Если вы хотите изменить пример текста, используемый в ссылке, измените ./vits/inference.py input часть.
В репозитории Cjangcjengh/Vits я внес некоторые изменения в корейский метод очистки текста. Другой процесс очистки одинаковы, опубликовав его в репозиторий Cjangcjengh, но файл более чистоты был изменен с использованием библиотеки Tenebo/G2PK2 в качестве корейского.
Для получения дополнительной информации, пожалуйста, обратитесь к следующим репозиториям:


