One Click MB iSTFT VITS2
1.0.0
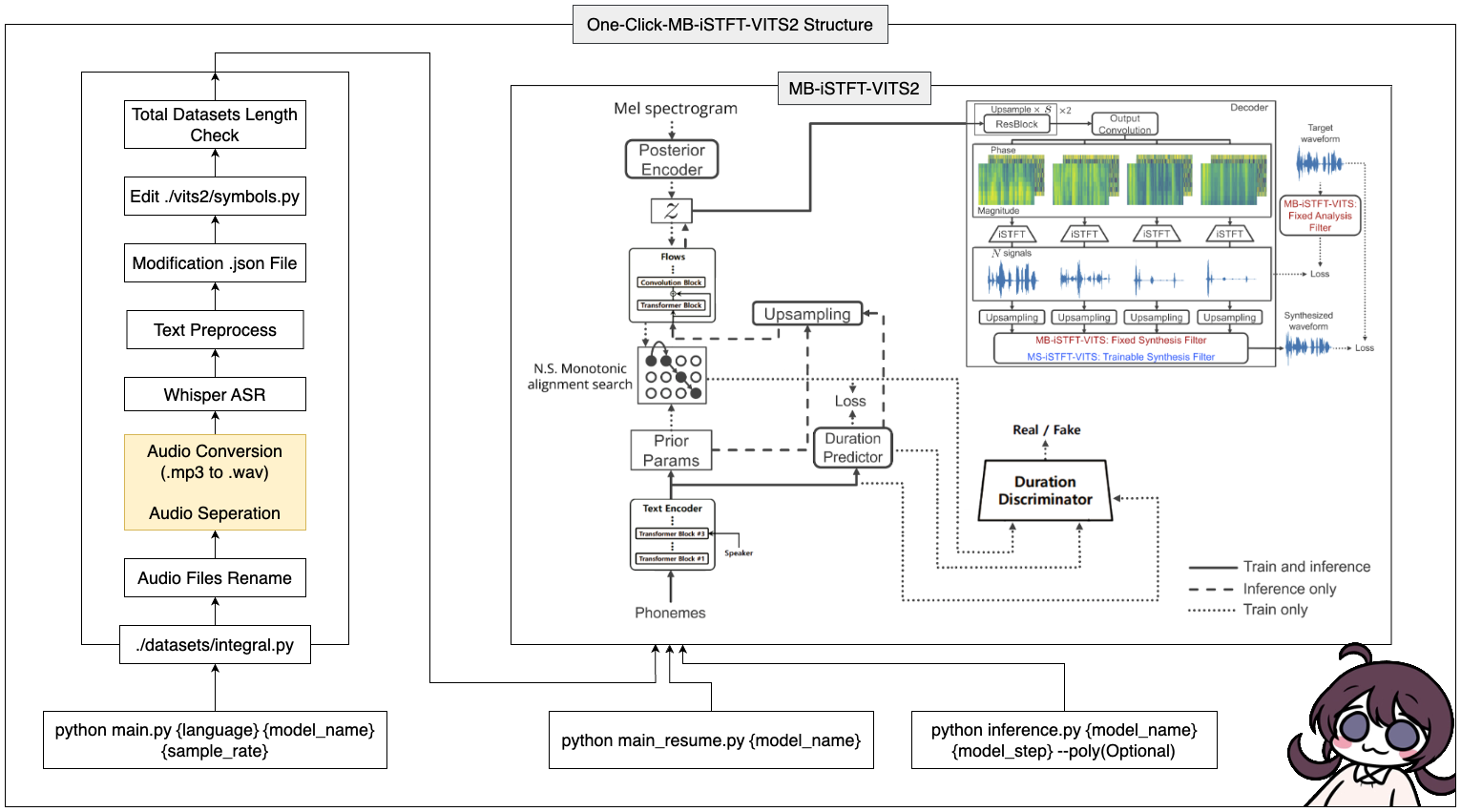
Esta herramienta le permite completar todo el proceso de MB-ESTFT-VITS2 (preprocesamiento de datos + Whisper ASR + Preprocesamiento de texto + modificación Config.json + Training, Inference) con un solo clic!
16GB de RAM.12GB de VRAM.Comando de instalación de Pytorch:
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117 CUDA 11.7 Instalación: https://developer.nvidia.com/cuda-11-7-0-download-archive
Zlib dll Instalar: https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html#install-zlib-windows
Instale PyopenJTalk manualmente: pip install -U pyopenjtalk --no-build-isolation
conda create -n vits2 python=3.8conda activate vits2git clone https://github.com/ORI-Muchim/One-Click-MB-iSTFT-VITS2.git cd One-Click-MB-iSTFT-VITS2pip install -r requirements.txtColoque los archivos de audio de la siguiente manera.
.mp3 o los archivos .wav están bien.
One-Click-MB-iSTFT-VITS2
├────datasets
│ ├───speaker0
│ │ ├────1.mp3
│ │ └────1.wav
│ └───speaker1
│ │ ├───1.mp3
│ │ └───1.wav
│ ├integral.py
│ └integral_low.py
│
├────vits2
├────inference.py
├────main_low.py
├────main_resume.py
├────main.py
├────Readme.md
└────requirements.txt
Este es solo un ejemplo, y está bien agregar más altavoces.
Para iniciar esta herramienta, use el siguiente comando, reemplazando {lenguaje}, {model_name} y {sample_rate} con sus valores respectivos ({lenguaje: ko, ja, en, zh} / {sample_rate: 22050 /44100}):::
python main.py {language} {model_name} {sample_rate}Para aquellos con bajas especificaciones (VRAM <= 16GB), use este código:
python main_low.py {language} {model_name} {sample_rate}Si la configuración de datos está completa y desea reanudar la capacitación, ingrese este código:
python main_resume.py {model_name}Después de que el modelo haya sido entrenado, puede generar predicciones utilizando el siguiente comando, reemplazando {model_name} y {model_step} con sus valores respectivos:
python inference.py {model_name} {model_step} --poly(Optional) Si ha seleccionado CJKE_CLEANERS2 (EN, ZH), ponga la opción --poly en la parte posterior.
Si desea cambiar el texto de ejemplo utilizado en la referencia, modifique ./vits/inference.py Part input .
En el repositorio de Cjangcjengh/Vits, hice algunas modificaciones al método de limpieza de texto coreano. El otro proceso de limpieza es el mismo al publicarlo en el repositorio de Cjangcjengh, pero el archivo limpiador se modificó utilizando la biblioteca TeneBo/G2PK2 como se pronuncia coreano.
Para obtener más información, consulte los siguientes repositorios:


