One Click MB iSTFT VITS2
1.0.0
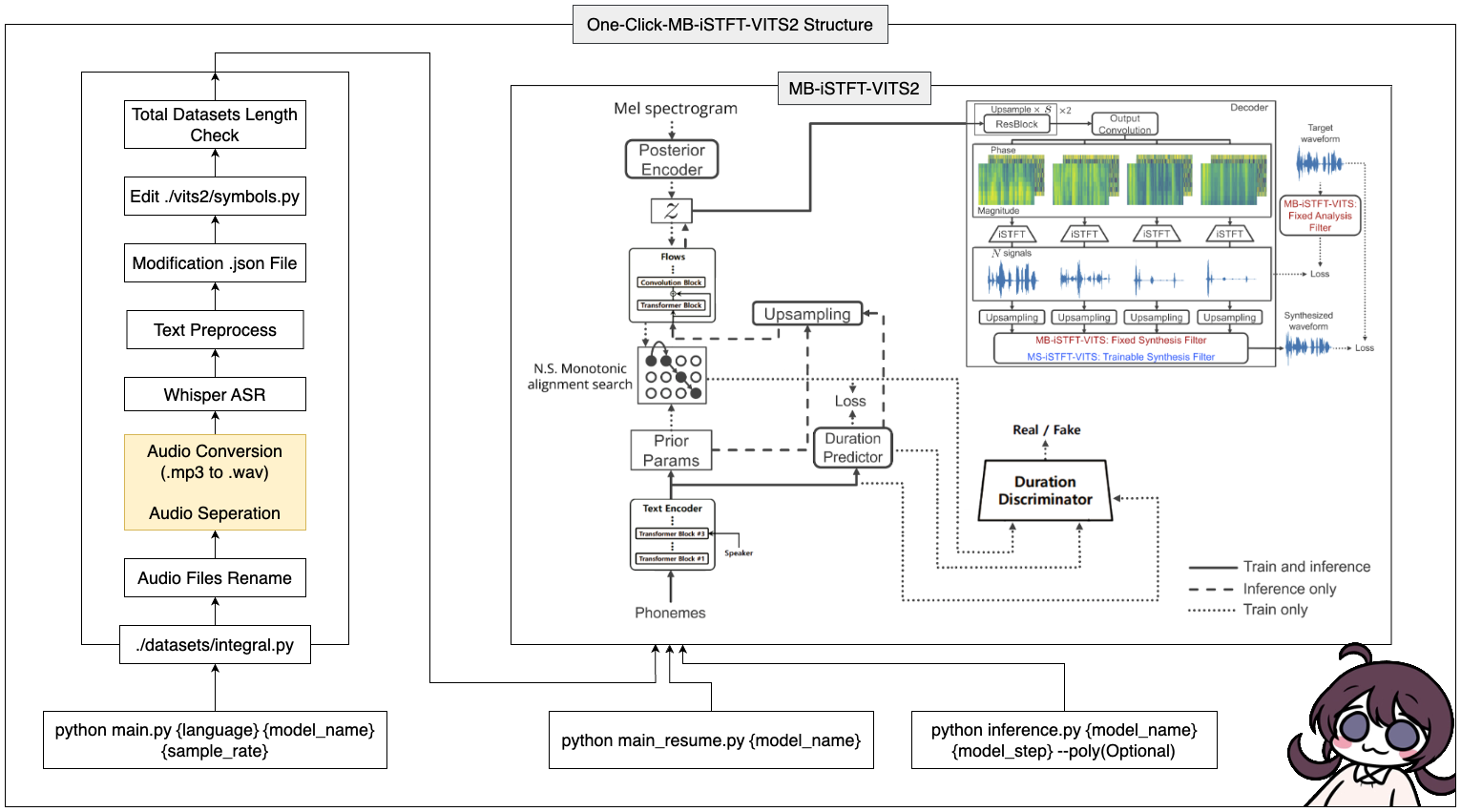
このツールを使用すると、MB-Istft-vits2のプロセス全体(データプリプロセッシング +ささやき +テキストプレプロセッシング +修正config.json +トレーニング、推論、推論、推論)のプロセス全体を完了できます!
16GB RAMを備えたWindows/Linuxシステム。12GBのVRAMを持つGPU。Pytorchインストールコマンド:
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117 CUDA 11.7インストール: https://developer.nvidia.com/cuda-11-7-0-download-archive
ZLIB DLLインストール: https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html#install-zlib-windows
Pyopenjtalkを手動でインストールする: pip install -U pyopenjtalk --no-build-isolation
conda create -n vits2 python=3.8conda activate vits2git clone https://github.com/ORI-Muchim/One-Click-MB-iSTFT-VITS2.git cd One-Click-MB-iSTFT-VITS2pip install -r requirements.txt次のようにオーディオファイルを配置します。
.mp3または.wavファイルは大丈夫です。
One-Click-MB-iSTFT-VITS2
├────datasets
│ ├───speaker0
│ │ ├────1.mp3
│ │ └────1.wav
│ └───speaker1
│ │ ├───1.mp3
│ │ └───1.wav
│ ├integral.py
│ └integral_low.py
│
├────vits2
├────inference.py
├────main_low.py
├────main_resume.py
├────main.py
├────Readme.md
└────requirements.txt
これは単なる例であり、スピーカーを追加しても大丈夫です。
このツールを開始するには、次のコマンドを使用して、{言語}、{model_name}、および{sample_rate}をそれぞれの値に置き換えます({言語:ko、ja、en、zh} / {sample_rate:22050 /44100}):
python main.py {language} {model_name} {sample_rate}仕様が低い人(VRAM <= 16GB)については、このコードを使用してください。
python main_low.py {language} {model_name} {sample_rate}データ構成が完了し、トレーニングを再開する場合は、このコードを入力してください。
python main_resume.py {model_name}モデルがトレーニングされた後、次のコマンドを使用して予測を生成し、{model_name}と{model_step}をそれぞれの値に置き換えることができます。
python inference.py {model_name} {model_step} --poly(Optional) CJKE_CLEANERS2(EN、ZH)を選択した場合は、後ろに--polyオプションを配置します。
参照で使用されているテキストのサンプルを変更する場合は、 ./vits/inference.py inputパーツを変更します。
Cjangcjengh/vitsのリポジトリでは、韓国のテキストクリーニング方法にいくつかの変更を加えました。他のクリーニングプロセスは、Cjangcjenghリポジトリに投稿することで同じですが、クリーナーファイルは韓国語のTenebo/G2PK2ライブラリを使用して変更されました。
詳細については、次のリポジトリを参照してください。


