DiscoGAN pytorch
1.0.0
การใช้ Pytorch ของการเรียนรู้เพื่อค้นพบความสัมพันธ์ข้ามโดเมนกับเครือข่ายฝ่ายตรงข้าม
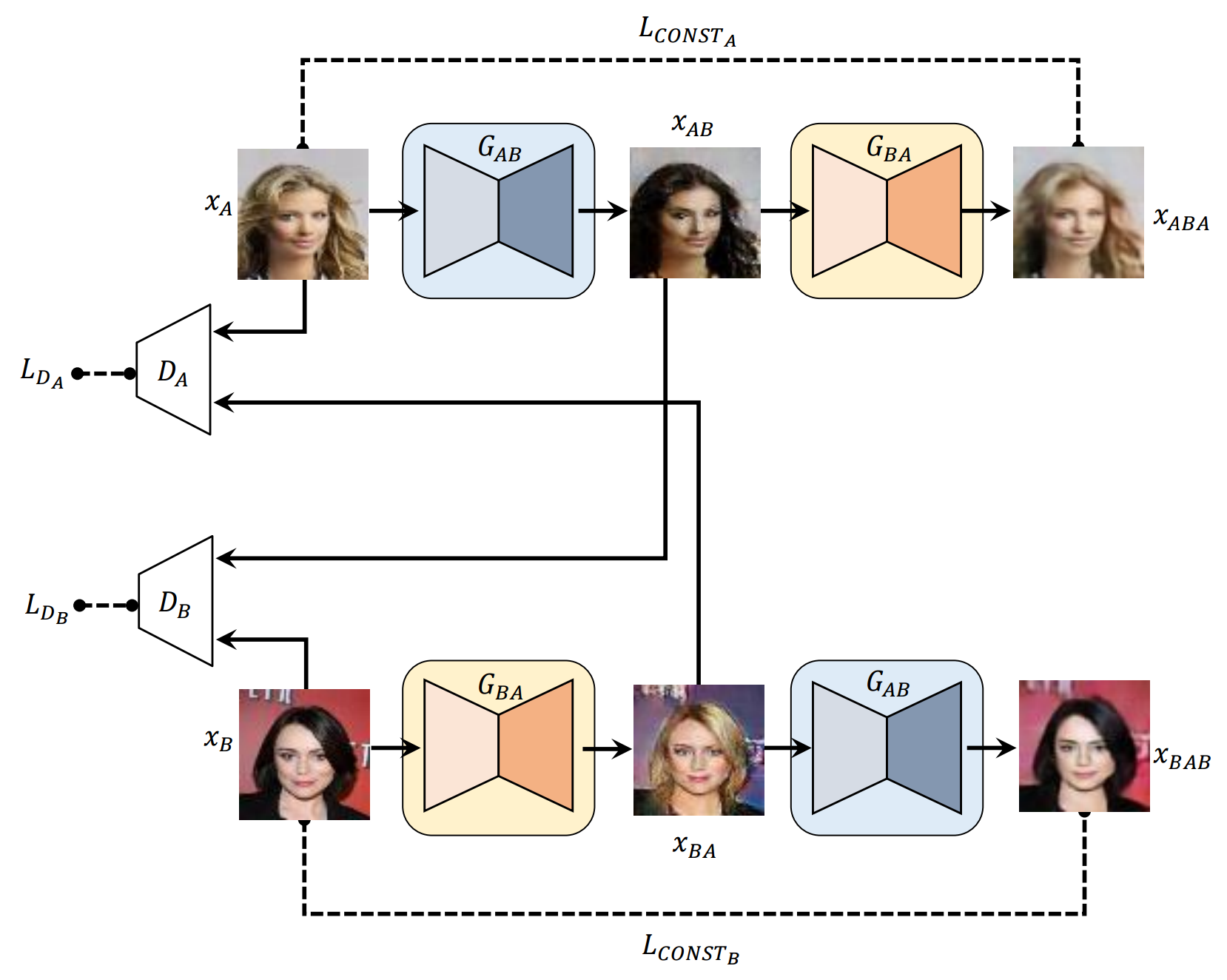
* ตัวอย่างทั้งหมดใน readme.md มีชีวิตชีวาด้วยเครือข่ายประสาทยกเว้นภาพแรกสำหรับแต่ละแถว
* โครงสร้างเครือข่ายแตกต่างกันเล็กน้อย (ที่นี่) จากรหัสของผู้เขียน
ชุดข้อมูลดาวน์โหลดครั้งแรก (จาก Pix2Pix) พร้อม:
$ bash ./data/download_dataset.sh dataset_name
facades : 400 ภาพจากชุดข้อมูล CMP Facadescityscapes : 2975 ภาพจากชุดฝึกซ้อม Cityscapesmaps : 1096 ภาพการฝึกอบรมที่คัดลอกมาจาก Google Mapsedges2shoes : ภาพการฝึกอบรม 50K จากชุดข้อมูล UT ZAPPOS50Kedges2handbags : 137K Amazon Handbag Images จากโครงการ IGANหรือคุณสามารถใช้ชุดข้อมูลของคุณเองได้โดยวางรูปภาพเช่น:
data
├── YOUR_DATASET_NAME
│ ├── A
│ | ├── xxx.jpg (name doesn't matter)
│ | ├── yyy.jpg
│ | └── ...
│ └── B
│ ├── zzz.jpg
│ ├── www.jpg
│ └── ...
└── download_dataset.sh
ภาพทั้งหมดในแต่ละชุดข้อมูลควรมีขนาดเท่ากัน เช่นใช้ ImageMagick:
# for Ubuntu
$ sudo apt-get install imagemagick
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/A/*.jpg
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/B/*.jpg
# for Mac
$ brew install imagemagick
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/A/*.jpg
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/B/*.jpg
# for scale and center crop
$ mogrify -resize 256x256^ -gravity center -crop 256x256+0+0 -quality 100 -path ../A/*.jpg
เพื่อฝึกอบรมแบบจำลอง:
$ python main.py --dataset=edges2shoes --num_gpu=1
$ python main.py --dataset=YOUR_DATASET_NAME --num_gpu=4
เพื่อทดสอบโมเดล (ใช้ load_path ของคุณ):
$ python main.py --dataset=edges2handbags --load_path=logs/edges2handbags_2017-03-18_10-55-37 --num_gpu=0 --is_train=False
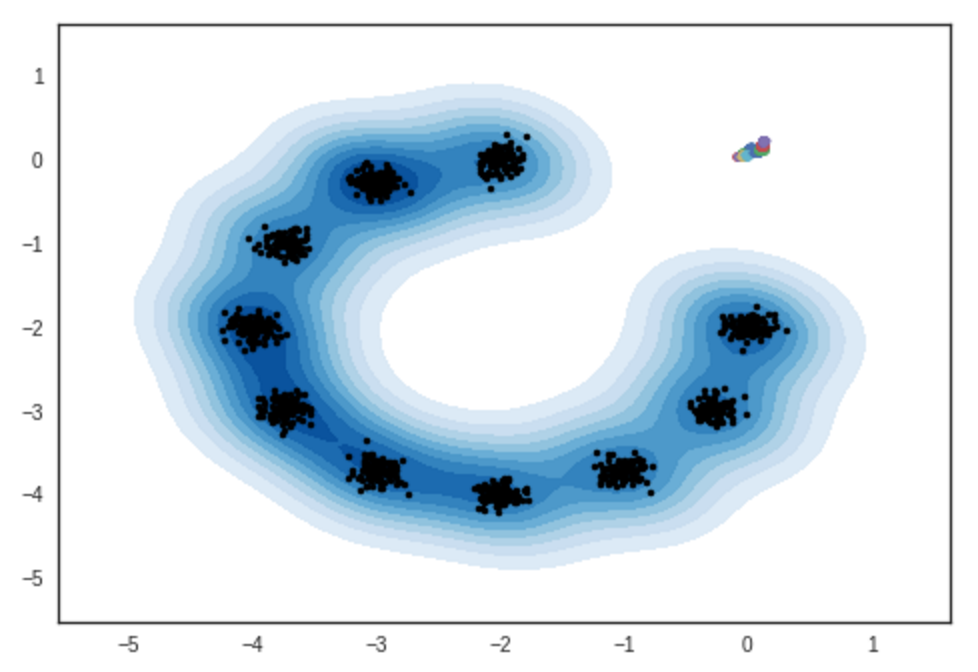
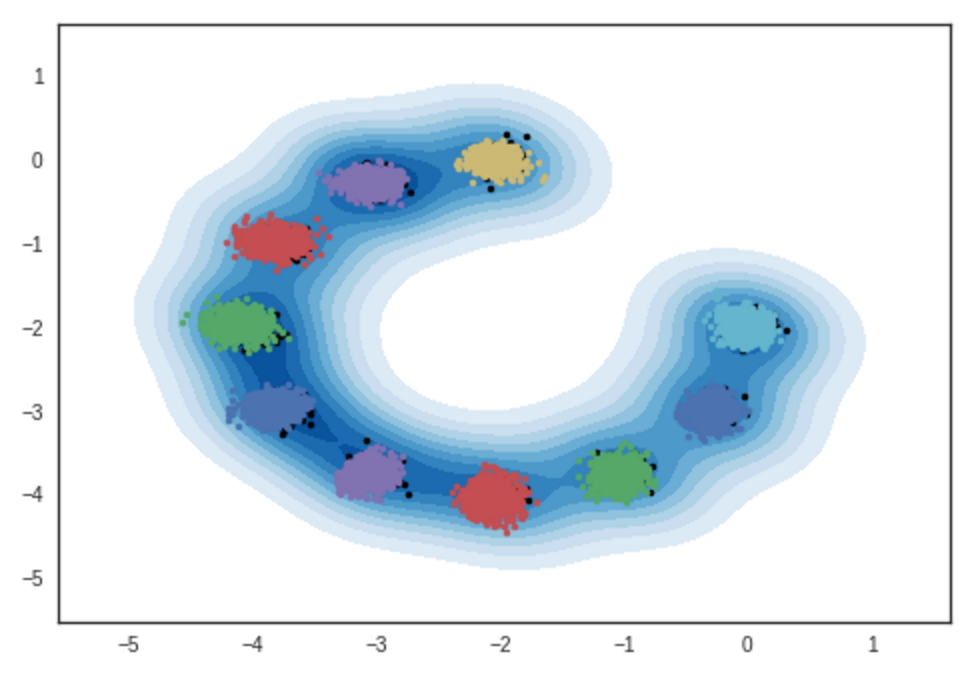
ผลลัพธ์ของตัวอย่างจากแบบจำลองผสมแบบเกาส์ 2 มิติ สมุดบันทึก ipython
# การทำซ้ำ: 0 :
# การทำซ้ำ: 10,000 :
# การทำซ้ำ: 11200 :
x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (รองเท้า -> กระเป๋าถือ -> รองเท้า)



x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (กระเป๋าถือ -> รองเท้า -> กระเป๋าถือ)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) -> G_AB(G_BA(G_AB(x_A))) -> G_BA(G_AB(G_BA(G_AB(x_A)))) -> ...







# การทำซ้ำ: 9600 :
x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (สี -> ร่าง -> สี)



x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (Sketch -> color -> sketch)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) -> G_AB(G_BA(G_AB(x_A))) -> G_BA(G_AB(G_BA(G_AB(x_A)))) -> ...







# การทำซ้ำ: 9500 :
x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (สี -> ร่าง -> สี)


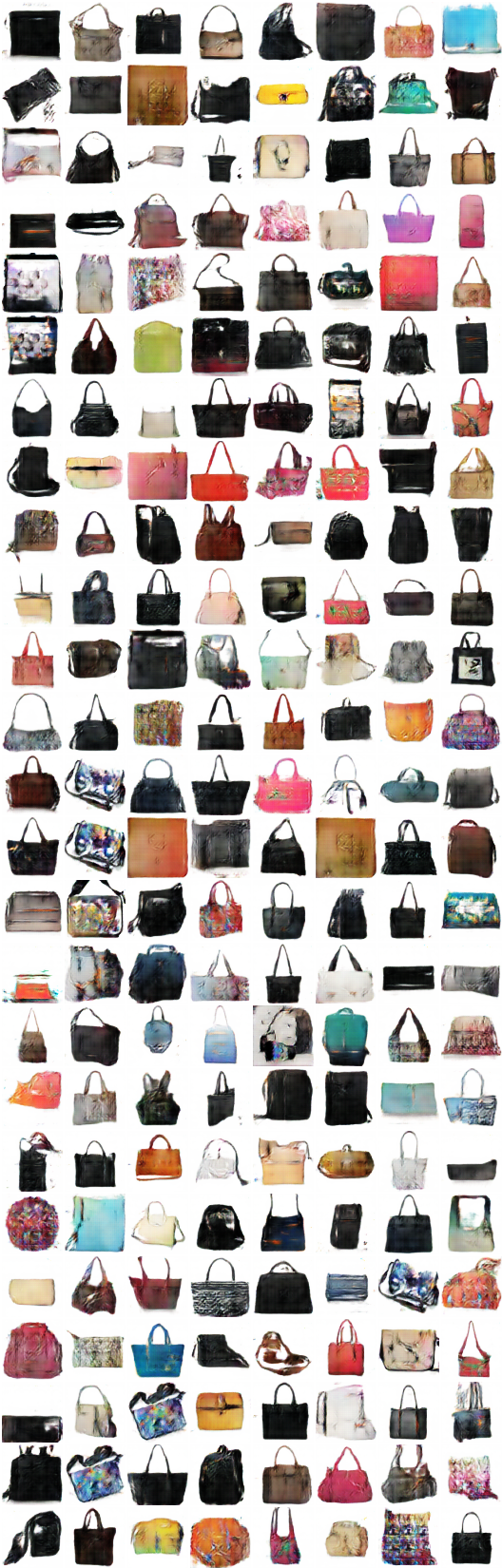
x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (Sketch -> color -> sketch)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) -> G_AB(G_BA(G_AB(x_A))) -> G_BA(G_AB(G_BA(G_AB(x_A)))) -> ...







# การทำซ้ำ: 8350 :
x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (รูปภาพ -> การแบ่งส่วน -> ภาพ)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (การแบ่งส่วน -> ภาพ -> การแบ่งส่วน)



# การทำซ้ำ: 22200 :
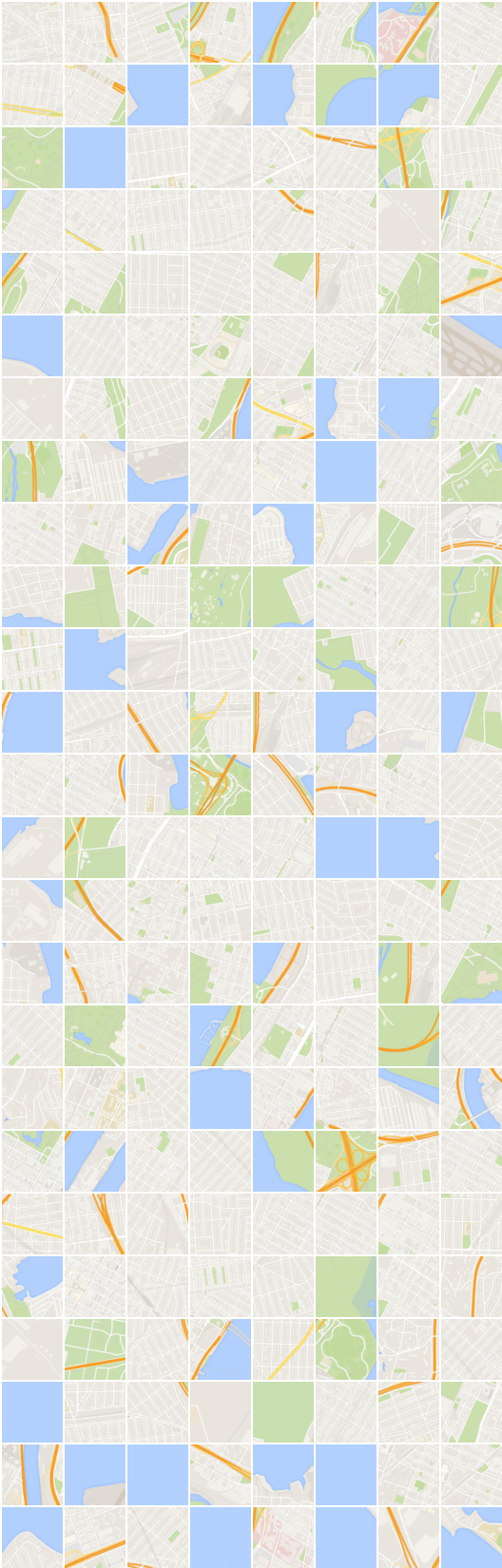
x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (รูปภาพ -> การแบ่งส่วน -> ภาพ)

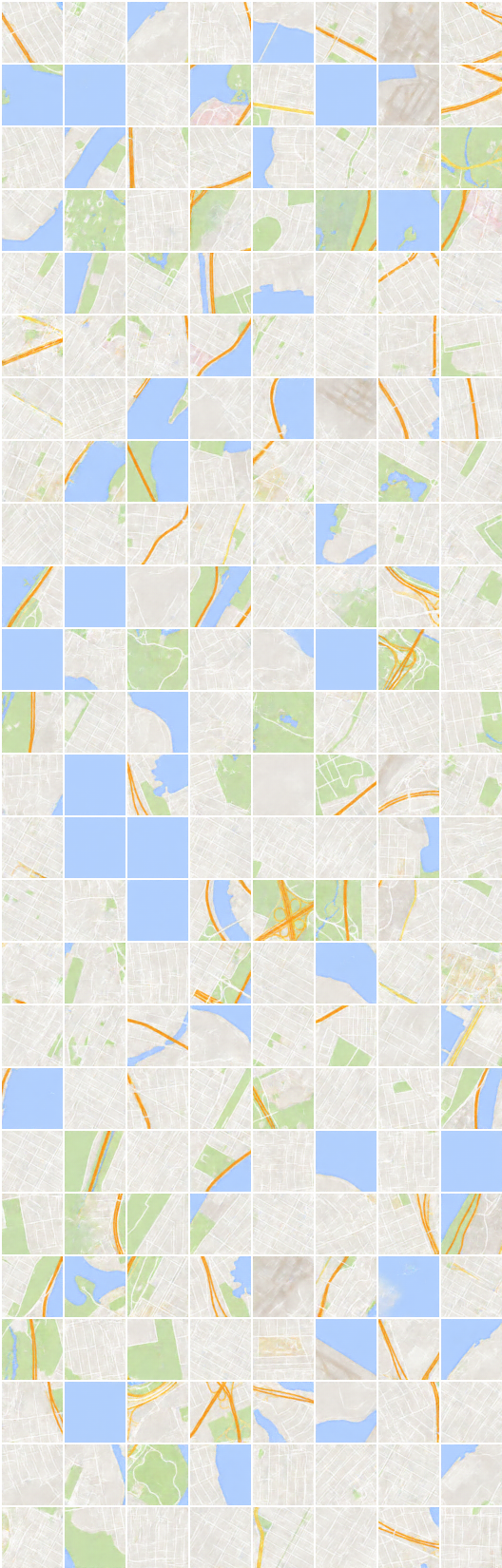

x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (การแบ่งส่วน -> ภาพ -> การแบ่งส่วน)

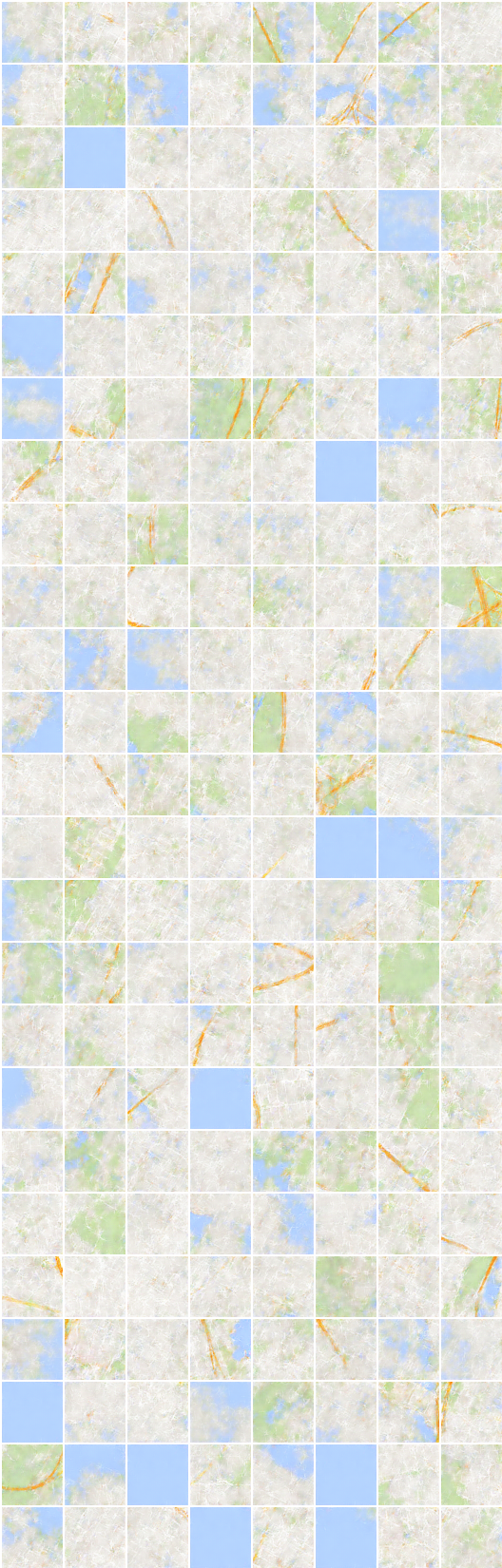
การสร้างและการสร้างใหม่ในชุดข้อมูลการแบ่งส่วนหนาแน่นดูแปลก ๆ ซึ่งไม่รวมอยู่ในกระดาษ
ฉันเดาว่าตัวเลือกที่ไร้เดียงสาของการสูญเสีย mean square error สำหรับการสร้างใหม่จำเป็นต้องมีการเปลี่ยนแปลงบางอย่างในชุดข้อมูลนี้
# การทำซ้ำ: 19450 :
x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (รูปภาพ -> การแบ่งส่วน -> ภาพ)

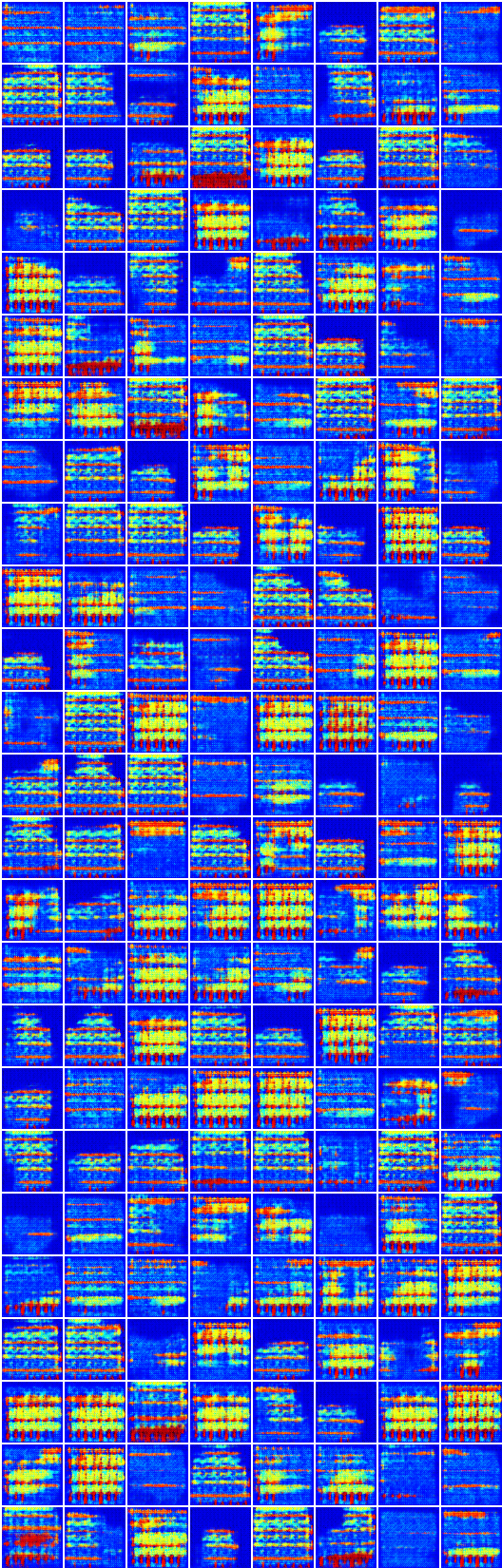

x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (การแบ่งส่วน -> ภาพ -> การแบ่งส่วน)



Taehoon Kim / @carpedm20


