DiscoGAN pytorch
1.0.0
Pytorch는 생성 적대성 네트워크와의 교차 도메인 관계를 발견하기위한 학습의 구현.
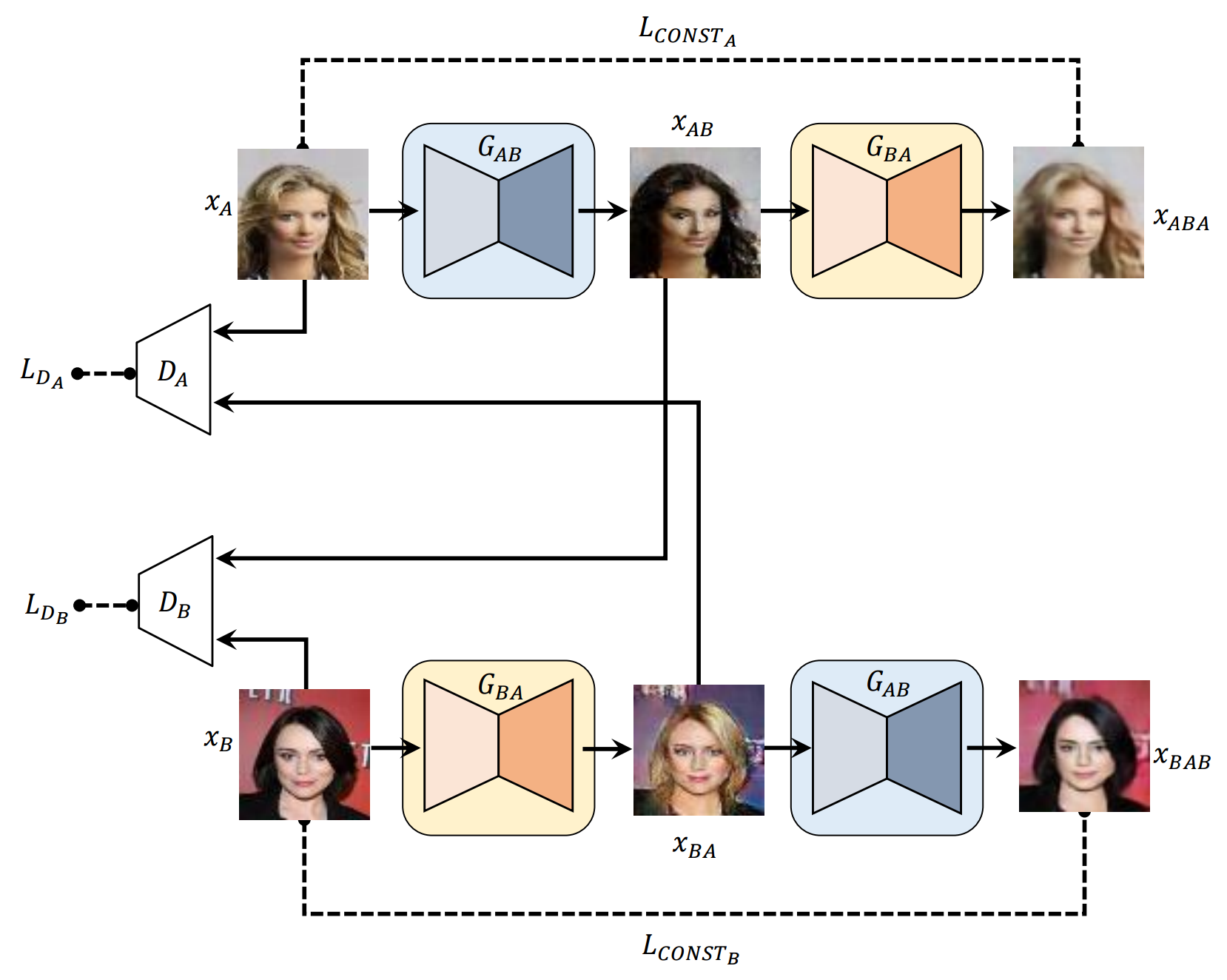
* readme.md의 모든 샘플은 각 행의 첫 번째 이미지를 제외하고 신경망에 의해 마음이 있습니다.
* 네트워크 구조는 저자의 코드와 약간 다른 (여기)입니다.
첫 번째 다운로드 데이터 세트 (pix2pix) :
$ bash ./data/download_dataset.sh dataset_name
facades : CMP Facades 데이터 세트의 400 개의 이미지.cityscapes : CityScapes Training 세트의 2975 이미지.maps : 1096 교육 이미지는 Google지도에서 긁혔습니다edges2shoes : UT Zappos50k 데이터 세트의 50k 교육 이미지.edges2handbags : 137k Amazon 핸드백 Igan 프로젝트의 이미지.또는 다음과 같은 이미지를 배치하여 자신의 데이터 세트를 사용할 수 있습니다.
data
├── YOUR_DATASET_NAME
│ ├── A
│ | ├── xxx.jpg (name doesn't matter)
│ | ├── yyy.jpg
│ | └── ...
│ └── B
│ ├── zzz.jpg
│ ├── www.jpg
│ └── ...
└── download_dataset.sh
각 데이터 세트의 모든 이미지는 imageMagick 사용과 같은 크기를 가져야합니다 .
# for Ubuntu
$ sudo apt-get install imagemagick
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/A/*.jpg
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/B/*.jpg
# for Mac
$ brew install imagemagick
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/A/*.jpg
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/B/*.jpg
# for scale and center crop
$ mogrify -resize 256x256^ -gravity center -crop 256x256+0+0 -quality 100 -path ../A/*.jpg
모델을 훈련하려면 :
$ python main.py --dataset=edges2shoes --num_gpu=1
$ python main.py --dataset=YOUR_DATASET_NAME --num_gpu=4
모델을 테스트하려면 ( load_path 사용) :
$ python main.py --dataset=edges2handbags --load_path=logs/edges2handbags_2017-03-18_10-55-37 --num_gpu=0 --is_train=False
2 차원 가우스 혼합물 모델의 샘플 결과. Ipython 노트북
# 반복 : 0 :
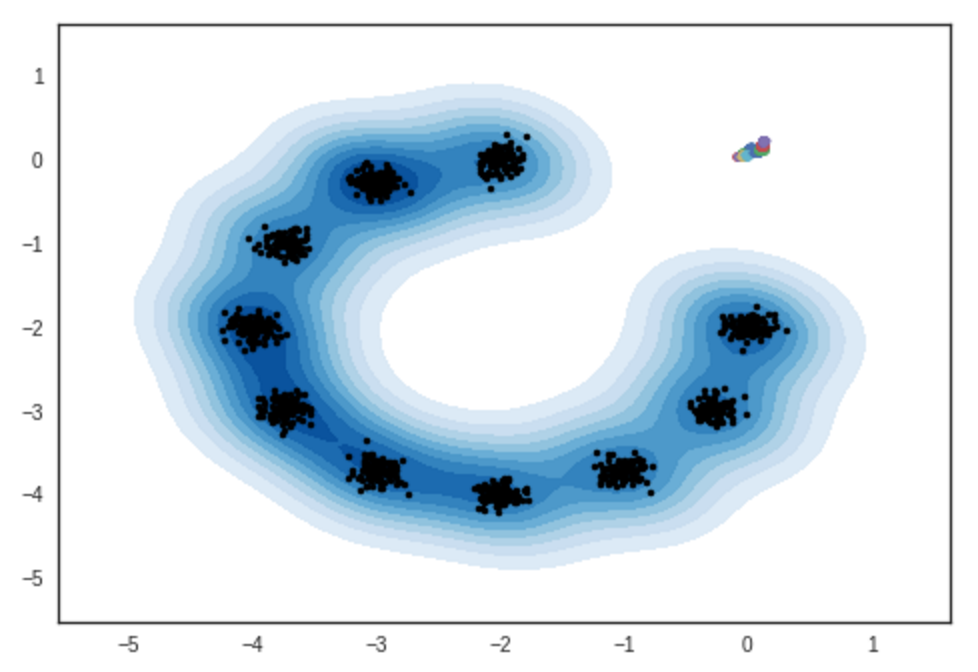
# 반복 : 10000 :
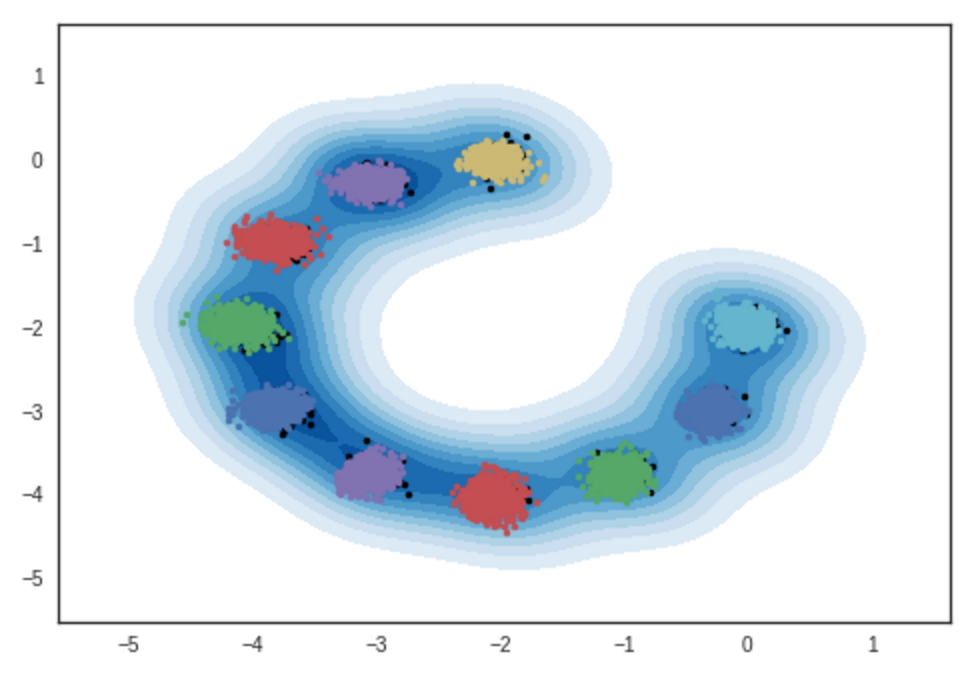
# 반복 : 11200 :
x_A > G_AB(x_A) -> G_BA(G_AB(x_A)) (신발 -> 핸드백 -> 신발)



x_B > G_BA(x_B) -> G_AB(G_BA(x_B)) (핸드백 -> 신발 -> 핸드백)



x_A > G_AB(x_A) -> G_BA(G_AB(x_A)) -> G_AB(G_BA(G_AB(x_A))) -> G_BA(G_AB(G_BA(G_AB(x_A)))) -> ...







# 반복 : 9600 :
x_A > G_AB(x_A) -> G_BA(G_AB(x_A)) (color -> sketch -> color)



x_B > G_BA(x_B) -> G_AB(G_BA(x_B)) (스케치 -> 색상 -> 스케치)



x_A > G_AB(x_A) -> G_BA(G_AB(x_A)) -> G_AB(G_BA(G_AB(x_A))) -> G_BA(G_AB(G_BA(G_AB(x_A)))) -> ...







# 반복 : 9500 :
x_A > G_AB(x_A) -> G_BA(G_AB(x_A)) (color -> sketch -> color)


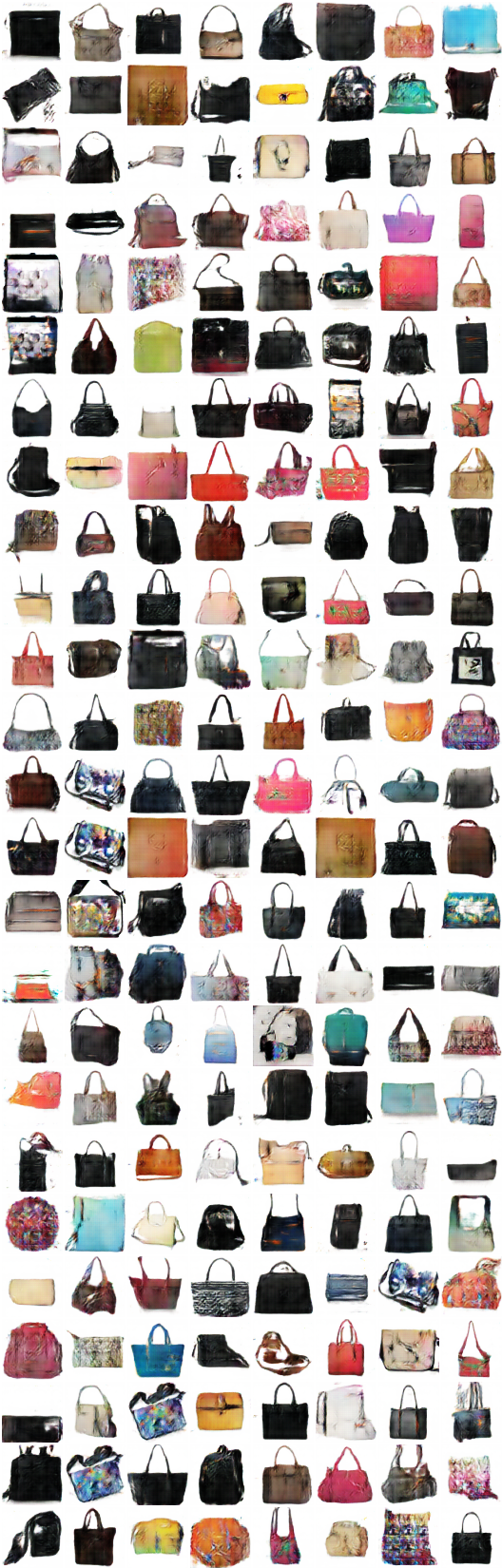
x_B > G_BA(x_B) -> G_AB(G_BA(x_B)) (스케치 -> 색상 -> 스케치)



x_A > G_AB(x_A) -> G_BA(G_AB(x_A)) -> G_AB(G_BA(G_AB(x_A))) -> G_BA(G_AB(G_BA(G_AB(x_A)))) -> ...







# 반복 : 8350 :
x_B > G_BA(x_B) -> G_AB(G_BA(x_B)) (이미지 -> 세분화 -> 이미지)



x_A > G_AB(x_A) -> G_BA(G_AB(x_A)) (세그먼트 화 -> 이미지 -> 세그먼트)



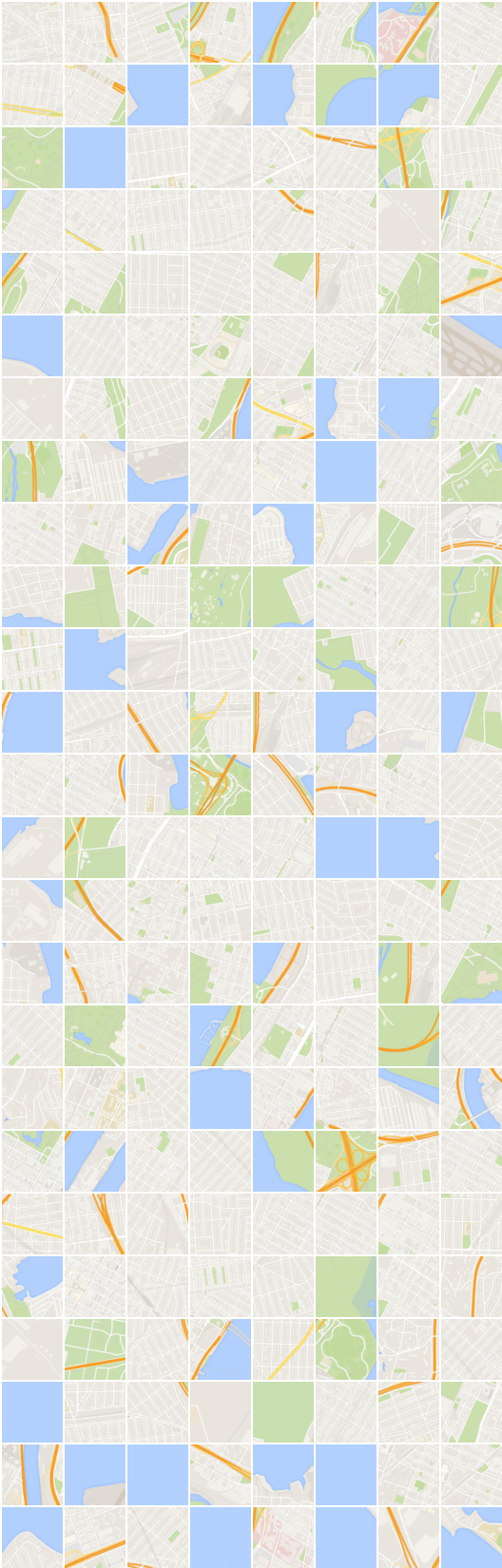
# 반복 : 22200 :
x_B > G_BA(x_B) -> G_AB(G_BA(x_B)) (이미지 -> 세분화 -> 이미지)

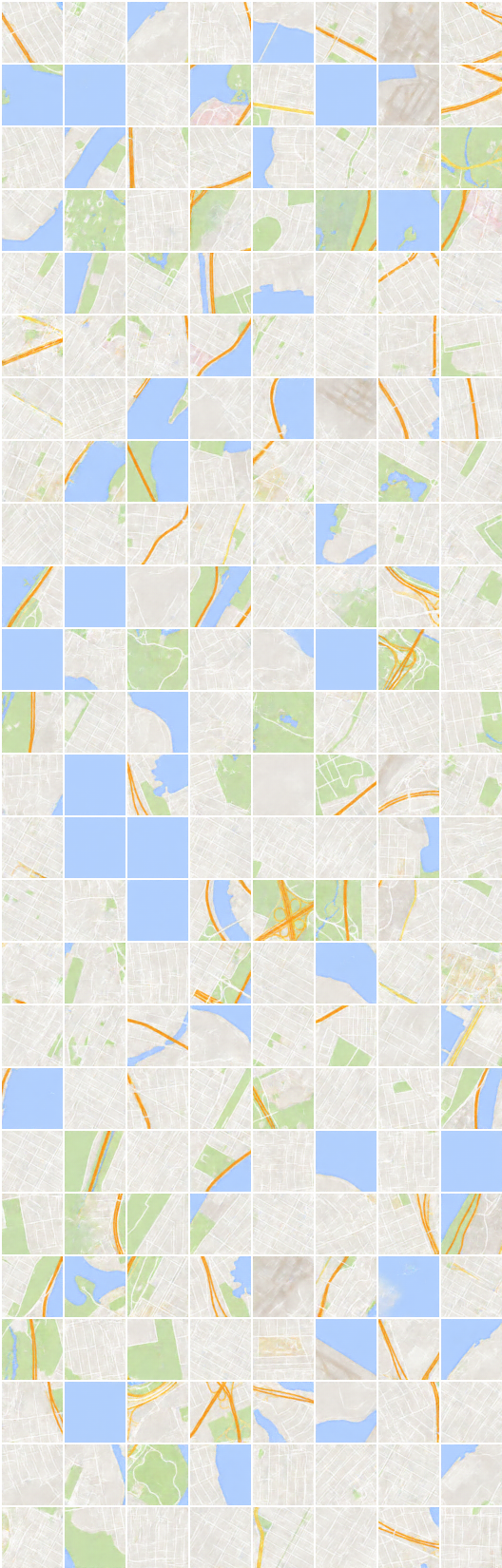

x_A > G_AB(x_A) -> G_BA(G_AB(x_A)) (세그먼트 화 -> 이미지 -> 세그먼트)

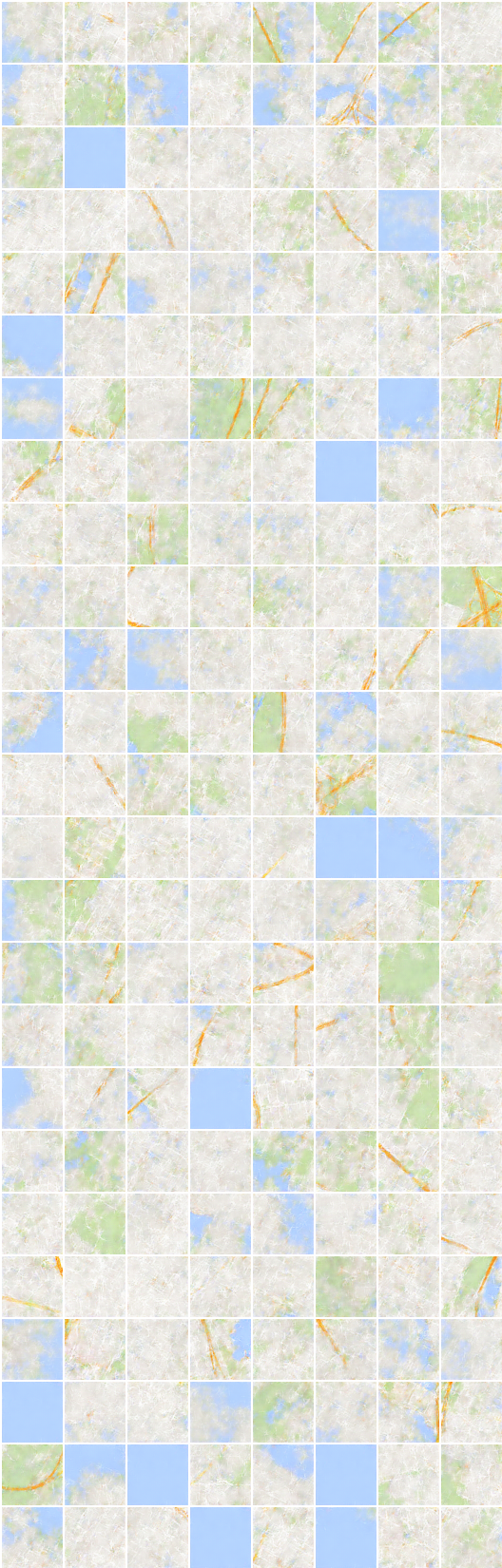
고밀도 세분화 데이터 세트의 생성 및 재구성은 논문에 포함되지 않은 이상하게 보입니다.
재건에 대한 mean square error 손실의 순진한 선택은이 데이터 세트에서 약간의 변경이 필요하다고 생각합니다.
# 반복 : 19450 :
x_B > G_BA(x_B) -> G_AB(G_BA(x_B)) (이미지 -> 세분화 -> 이미지)


x_A > G_AB(x_A) -> G_BA(G_AB(x_A)) (세그먼트 화 -> 이미지 -> 세그먼트)



Taehoon kim / @carpedm20


