DiscoGAN pytorch
1.0.0
生成的敵対的ネットワークとのクロスドメイン関係を発見するための学習のPytorchの実装。
* readme.mdのすべてのサンプルは、各行の最初の画像を除いて、ニューラルネットワークに心を込めて心に留めています。
*ネットワーク構造は、著者のコードから(ここで)わずかに異なります。
最初にデータセット(PIX2PIXから)をダウンロードしてください。
$ bash ./data/download_dataset.sh dataset_name
facades :CMP Facades Datasetの400画像。cityscapes :Cityscapesトレーニングセットの2975画像。maps :Googleマップから削り取られた1096のトレーニング画像edges2shoes :ut zappos50kデータセットからの50kのトレーニング画像。edges2handbags :Igan Projectの137k Amazonハンドバッグ画像。または、次のような画像を配置して、独自のデータセットを使用できます。
data
├── YOUR_DATASET_NAME
│ ├── A
│ | ├── xxx.jpg (name doesn't matter)
│ | ├── yyy.jpg
│ | └── ...
│ └── B
│ ├── zzz.jpg
│ ├── www.jpg
│ └── ...
└── download_dataset.sh
各データセットのすべての画像は、ImageMagickを使用するのと同じサイズを持つ必要があります。
# for Ubuntu
$ sudo apt-get install imagemagick
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/A/*.jpg
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/B/*.jpg
# for Mac
$ brew install imagemagick
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/A/*.jpg
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/B/*.jpg
# for scale and center crop
$ mogrify -resize 256x256^ -gravity center -crop 256x256+0+0 -quality 100 -path ../A/*.jpg
モデルをトレーニングするには:
$ python main.py --dataset=edges2shoes --num_gpu=1
$ python main.py --dataset=YOUR_DATASET_NAME --num_gpu=4
モデルをテストするには( load_pathを使用してください):
$ python main.py --dataset=edges2handbags --load_path=logs/edges2handbags_2017-03-18_10-55-37 --num_gpu=0 --is_train=False
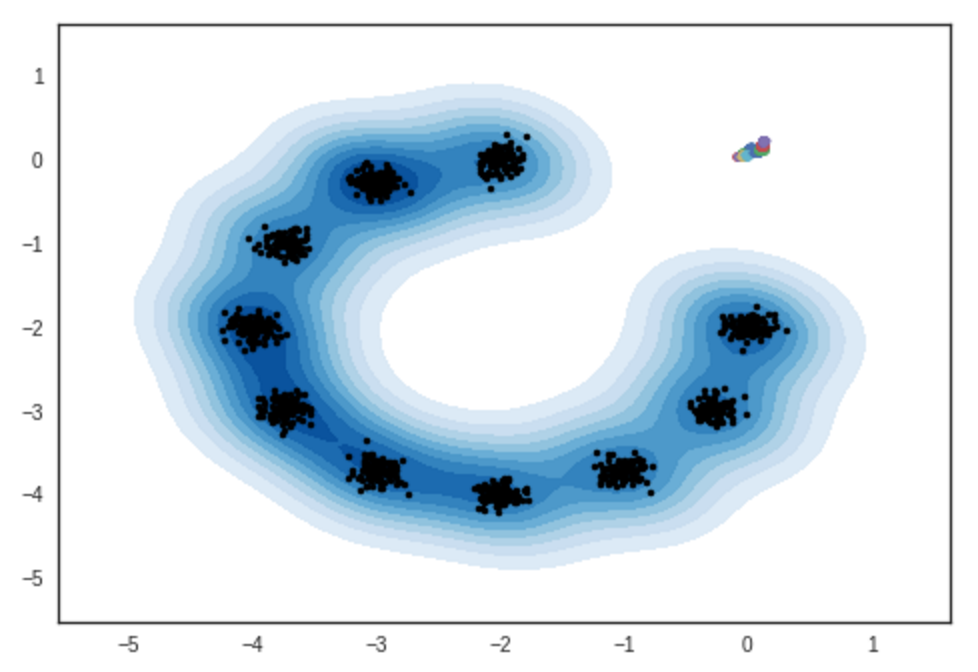
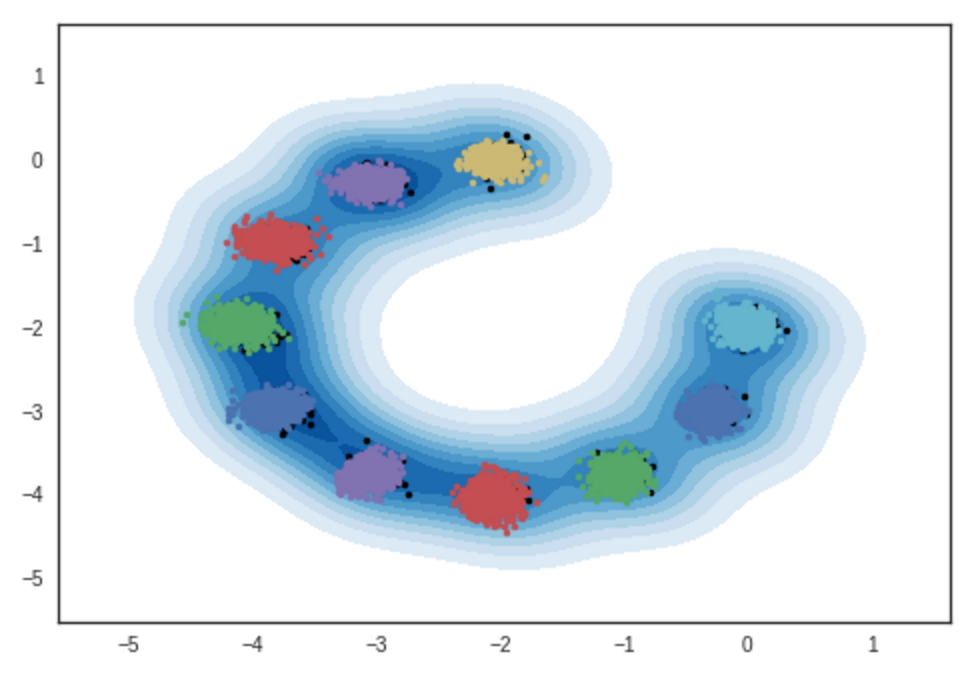
2次元ガウス混合モデルからのサンプルの結果。 IPythonノートブック
#反復:0 :
#反復:10000 :
#反復:11200 :
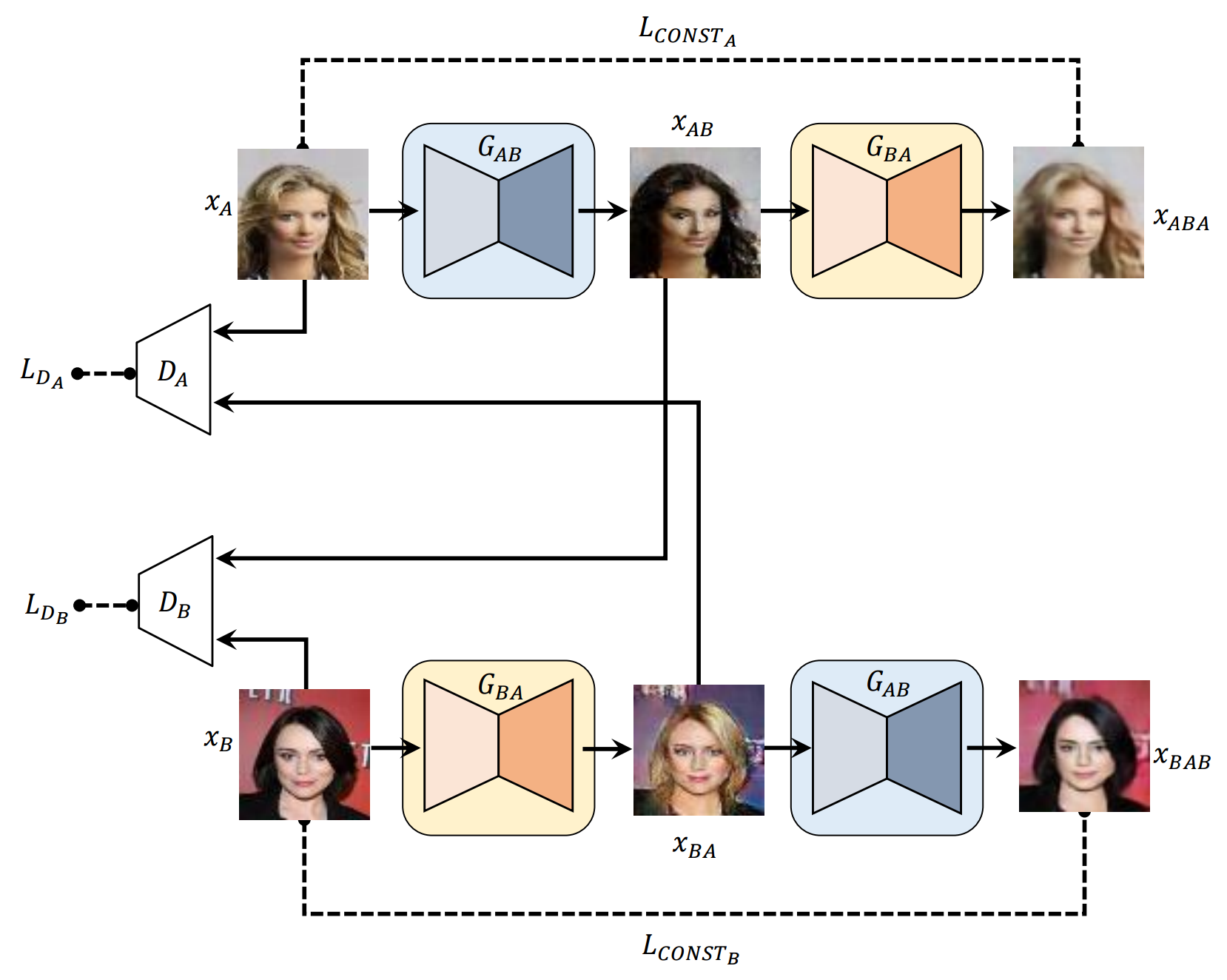
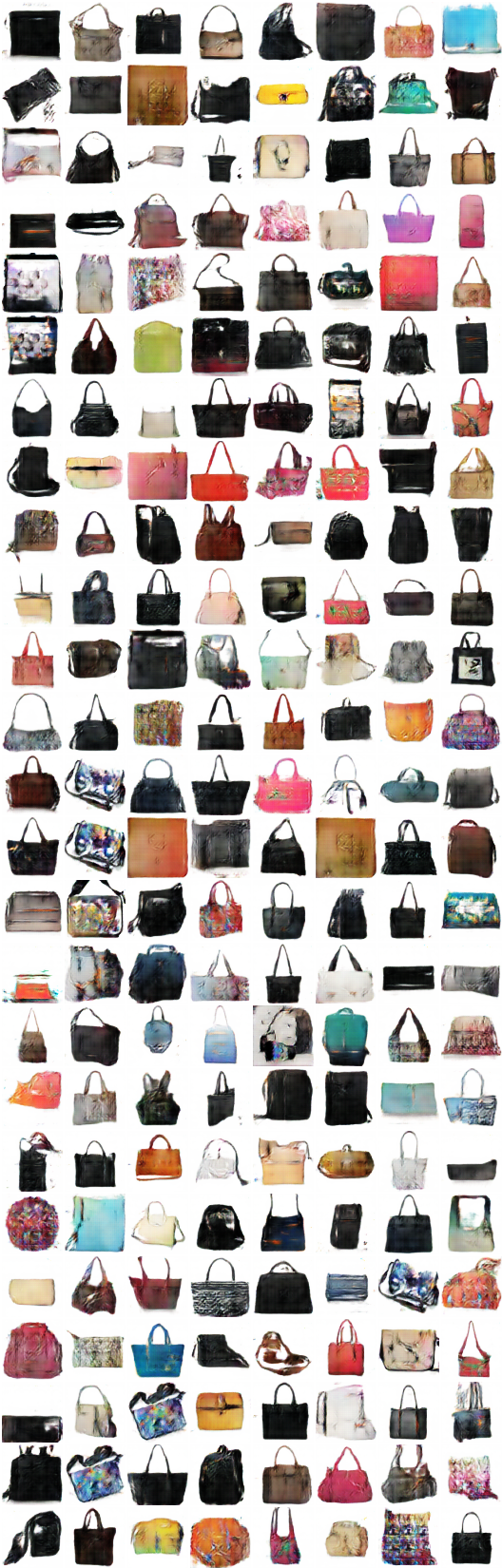
x_A > G_AB(x_A) - > G_BA(G_AB(x_A)) (靴 - >ハンドバッグ - >靴)



x_B > G_BA(x_B) - > G_AB(G_BA(x_B)) (handbag-> shoe-> handbag)



x_A > G_AB(x_A) - > G_BA(G_AB(x_A)) - > G_AB(G_BA(G_AB(x_A))) - > G_BA(G_AB(G_BA(G_AB(x_A)))) - > ...







#iteration:9600 :
x_A > G_AB(x_A) - > G_BA(G_AB(x_A)) (color-> sketch-> color)



x_B > G_BA(x_B) - > G_AB(G_BA(x_B)) (sketch-> color-> sketch)



x_A > G_AB(x_A) - > G_BA(G_AB(x_A)) - > G_AB(G_BA(G_AB(x_A))) - > G_BA(G_AB(G_BA(G_AB(x_A)))) - > ...







#イテレーション:9500 :
x_A > G_AB(x_A) - > G_BA(G_AB(x_A)) (color-> sketch-> color)


x_B > G_BA(x_B) - > G_AB(G_BA(x_B)) (sketch-> color-> sketch)



x_A > G_AB(x_A) - > G_BA(G_AB(x_A)) - > G_AB(G_BA(G_AB(x_A))) - > G_BA(G_AB(G_BA(G_AB(x_A)))) - > ...







#反復:8350 :
x_B > G_BA(x_B) - > G_AB(G_BA(x_B)) (画像 - >セグメンテーション - >画像)



x_A > G_AB(x_A) - > G_BA(G_AB(x_A)) (segmentation-> image-> segmentation)



#iteration:22200 :
x_B > G_BA(x_B) - > G_AB(G_BA(x_B)) (画像 - >セグメンテーション - >画像)

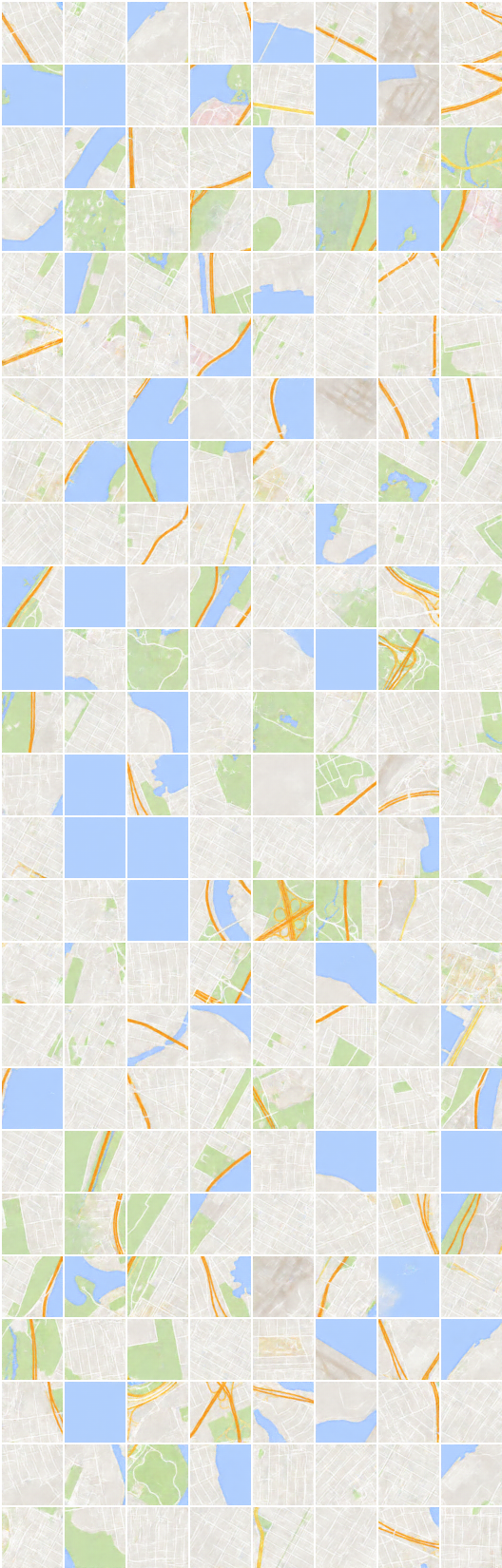

x_A > G_AB(x_A) - > G_BA(G_AB(x_A)) (segmentation-> image-> segmentation)
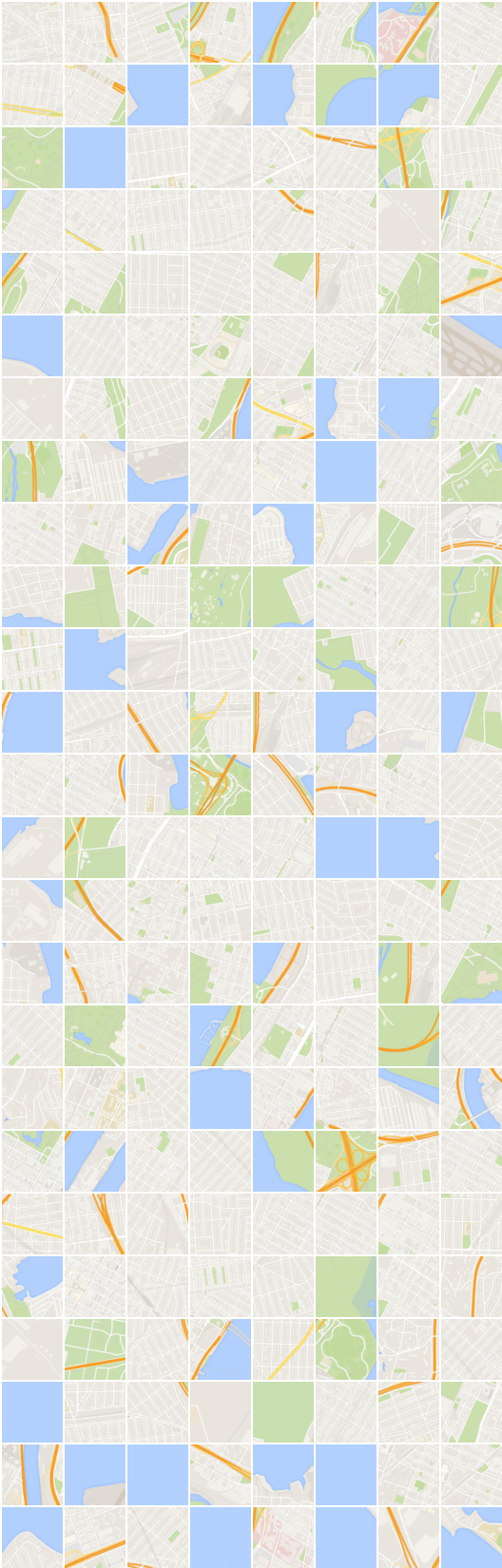

密なセグメンテーションデータセットの生成と再構築は、論文に含まれていない奇妙に見えます。
再構築のためのmean square error損失の素朴な選択には、このデータセットで何らかの変更が必要だと思います。
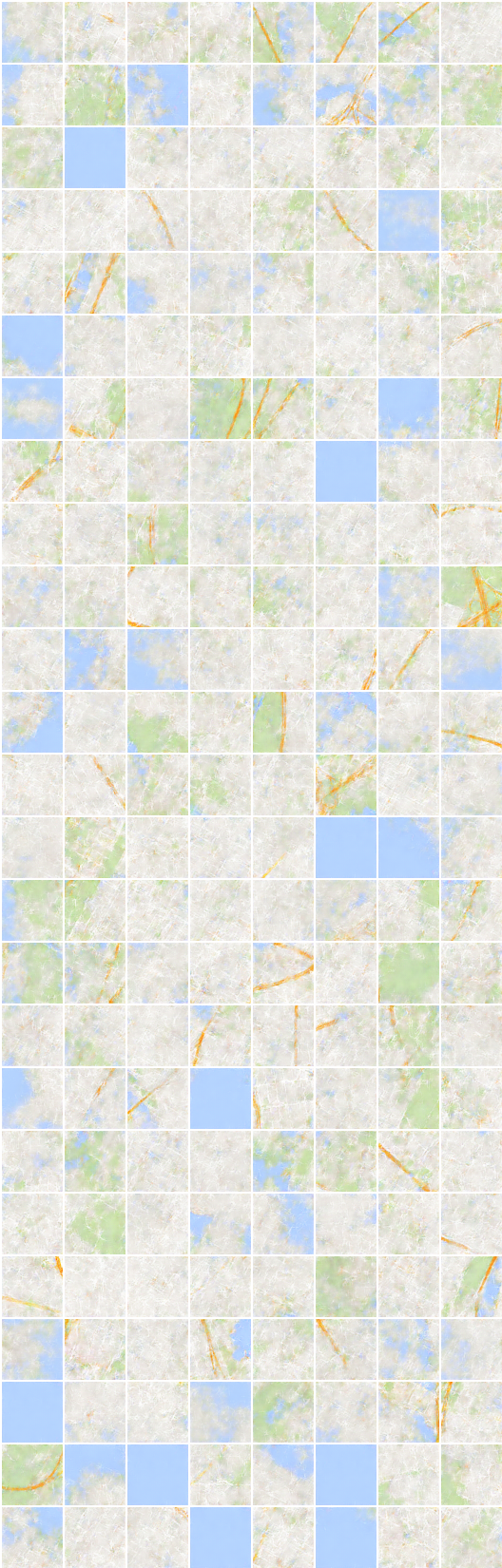
#反復:19450 :
x_B > G_BA(x_B) - > G_AB(G_BA(x_B)) (画像 - >セグメンテーション - >画像)


x_A > G_AB(x_A) - > G_BA(G_AB(x_A)) (segmentation-> image-> segmentation)



Taehoon Kim / @carpedm20


