DiscoGAN pytorch
1.0.0
Pytorch Implémentation de l'apprentissage pour découvrir les relations entre les domaines et les réseaux adversaires génératifs.
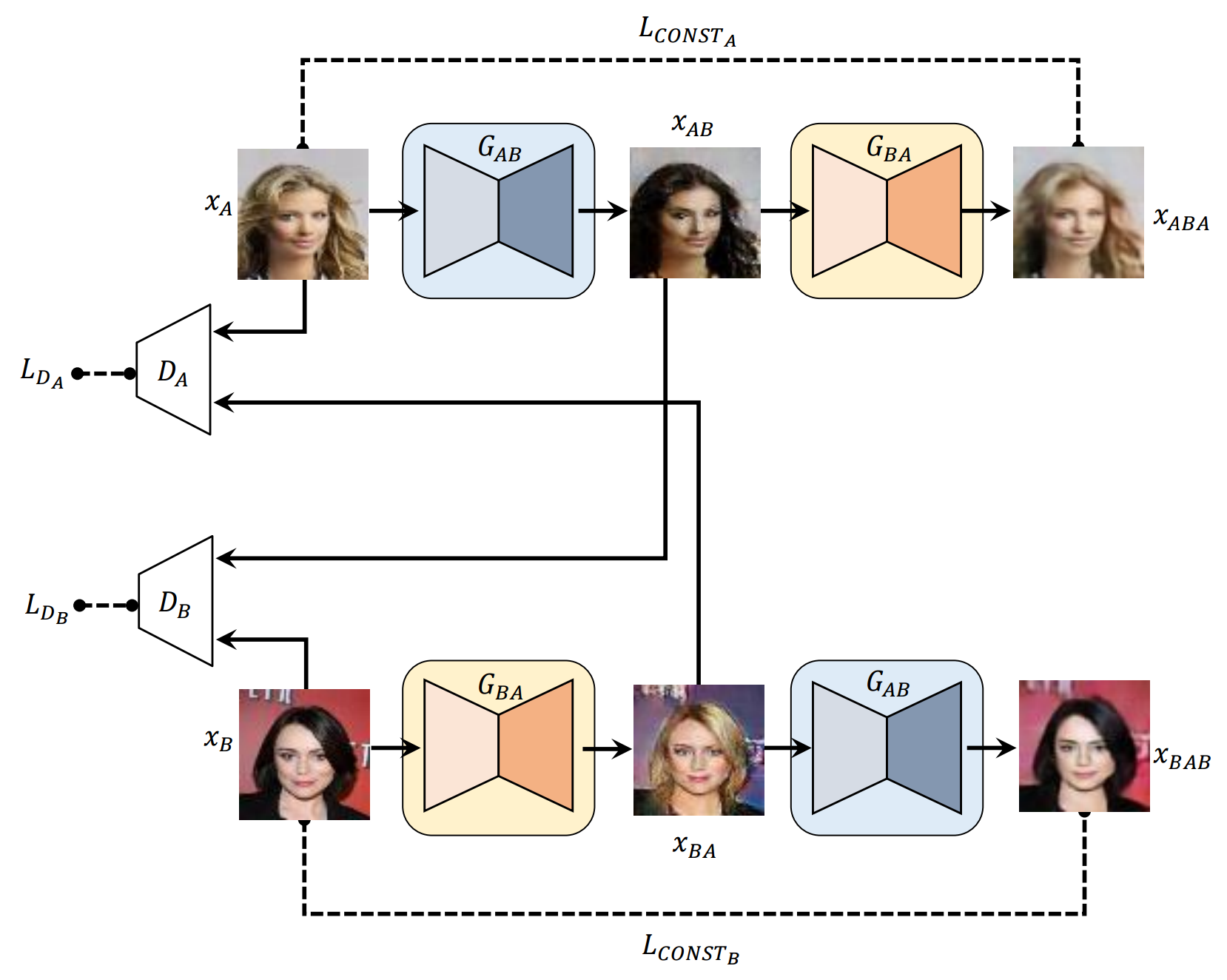
* Tous les échantillons dans Readme.md sont générés par le réseau neuronal à l'exception de la première image pour chaque ligne.
* La structure du réseau est légèrement différente (ici) du code de l'auteur.
Téléchargez d'abord les ensembles de données (à partir de pix2pix) avec:
$ bash ./data/download_dataset.sh dataset_name
facades : 400 images de l'ensemble de données CMP FACADES.cityscapes : 2975 Images de l'ensemble de formation des paysages urbains.maps : 1096 Images de formation Arrottées de Google Mapsedges2shoes : Images de formation 50K de l'ensemble de données UT Zapos50k.edges2handbags : 137k Images de sac à main Amazon de Igan Project.Ou vous pouvez utiliser votre propre ensemble de données en plaçant des images comme:
data
├── YOUR_DATASET_NAME
│ ├── A
│ | ├── xxx.jpg (name doesn't matter)
│ | ├── yyy.jpg
│ | └── ...
│ └── B
│ ├── zzz.jpg
│ ├── www.jpg
│ └── ...
└── download_dataset.sh
Toutes les images de chaque ensemble de données doivent avoir la même taille que l'utilisation d'imageMagick:
# for Ubuntu
$ sudo apt-get install imagemagick
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/A/*.jpg
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/B/*.jpg
# for Mac
$ brew install imagemagick
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/A/*.jpg
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/B/*.jpg
# for scale and center crop
$ mogrify -resize 256x256^ -gravity center -crop 256x256+0+0 -quality 100 -path ../A/*.jpg
Pour former un modèle:
$ python main.py --dataset=edges2shoes --num_gpu=1
$ python main.py --dataset=YOUR_DATASET_NAME --num_gpu=4
Pour tester un modèle (utilisez votre load_path ):
$ python main.py --dataset=edges2handbags --load_path=logs/edges2handbags_2017-03-18_10-55-37 --num_gpu=0 --is_train=False
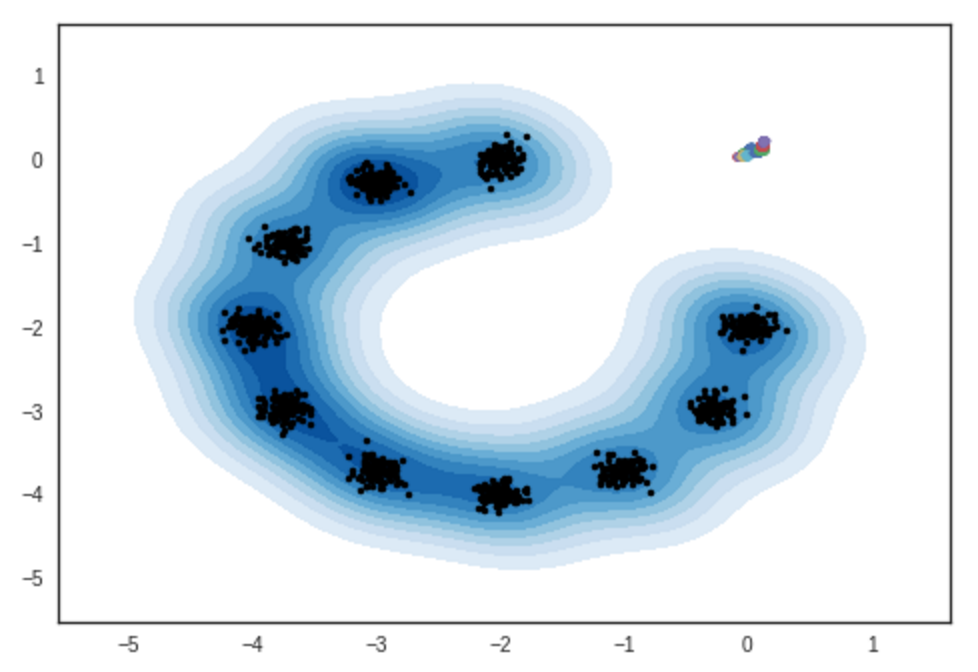
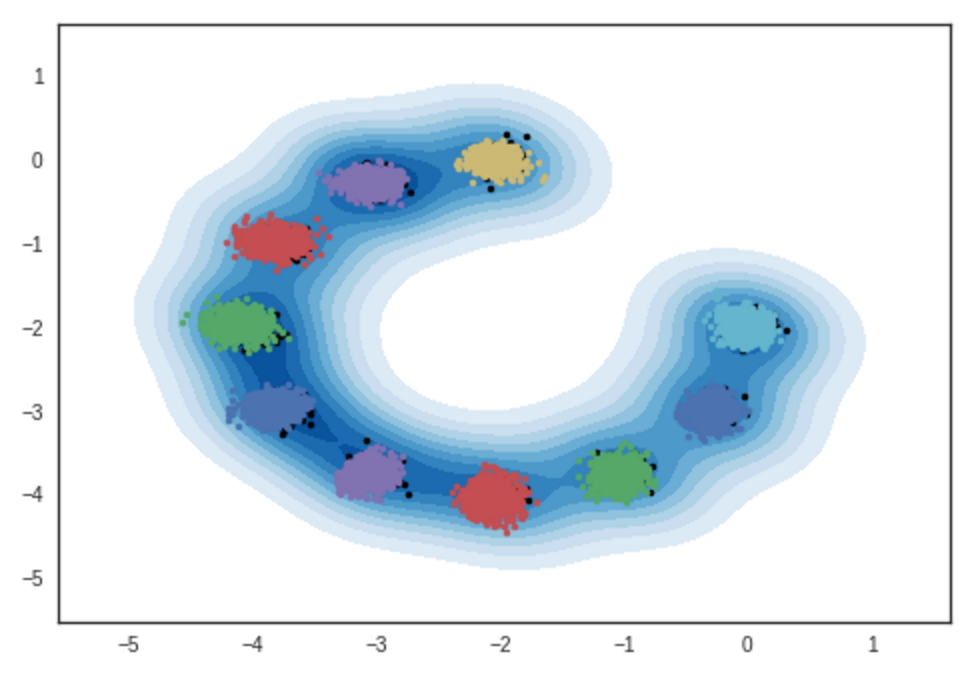
Résultat d'échantillons de modèles de mélange gaussien bidimensionnel. Cahier ipython
# itération: 0 :
# itération: 10000 :
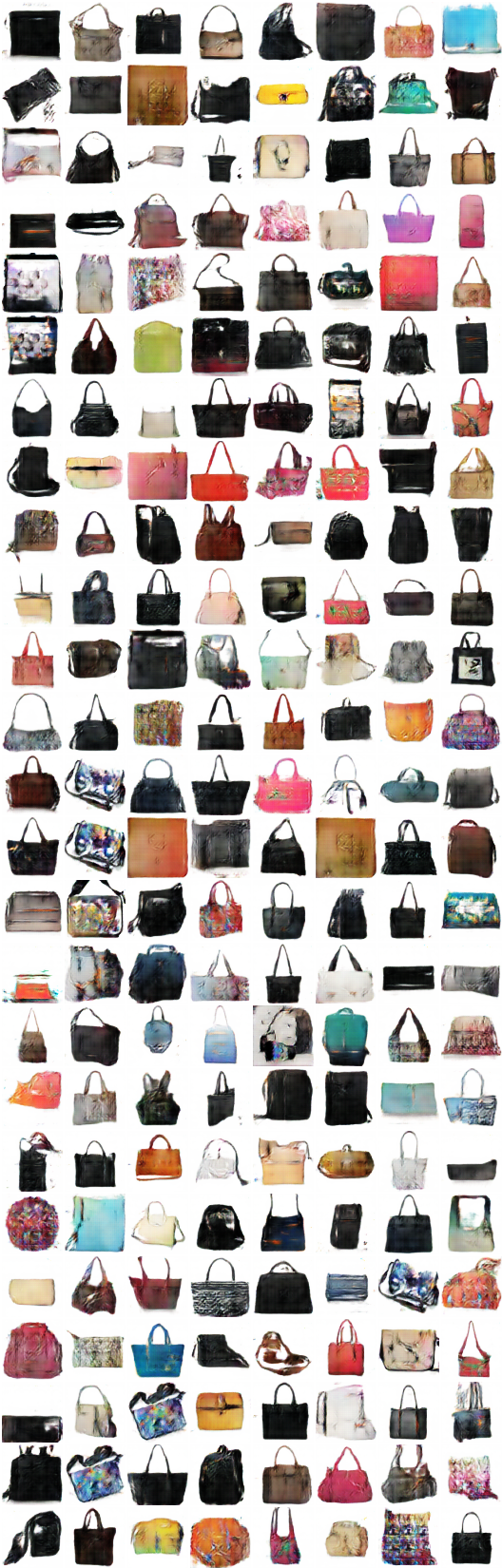
# itération: 11200 :
x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (chaussure -> sac à main -> chaussure)



x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (sac à main -> chaussure -> sac à main)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) -> G_AB(G_BA(G_AB(x_A))) -> G_BA(G_AB(G_BA(G_AB(x_A)))) -> ... ...







# itération: 9600 :
x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (couleur -> sketch -> couleur)



x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (sketch -> couleur -> sketch)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) -> G_AB(G_BA(G_AB(x_A))) -> G_BA(G_AB(G_BA(G_AB(x_A)))) -> ... ...







# itération: 9500 :
x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (couleur -> sketch -> couleur)


x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (sketch -> couleur -> sketch)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) -> G_AB(G_BA(G_AB(x_A))) -> G_BA(G_AB(G_BA(G_AB(x_A)))) -> ... ...







# itération: 8350 :
x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (image -> segmentation -> image)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (segmentation -> image -> segmentation)



# itération: 22200 :
x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (image -> segmentation -> image)

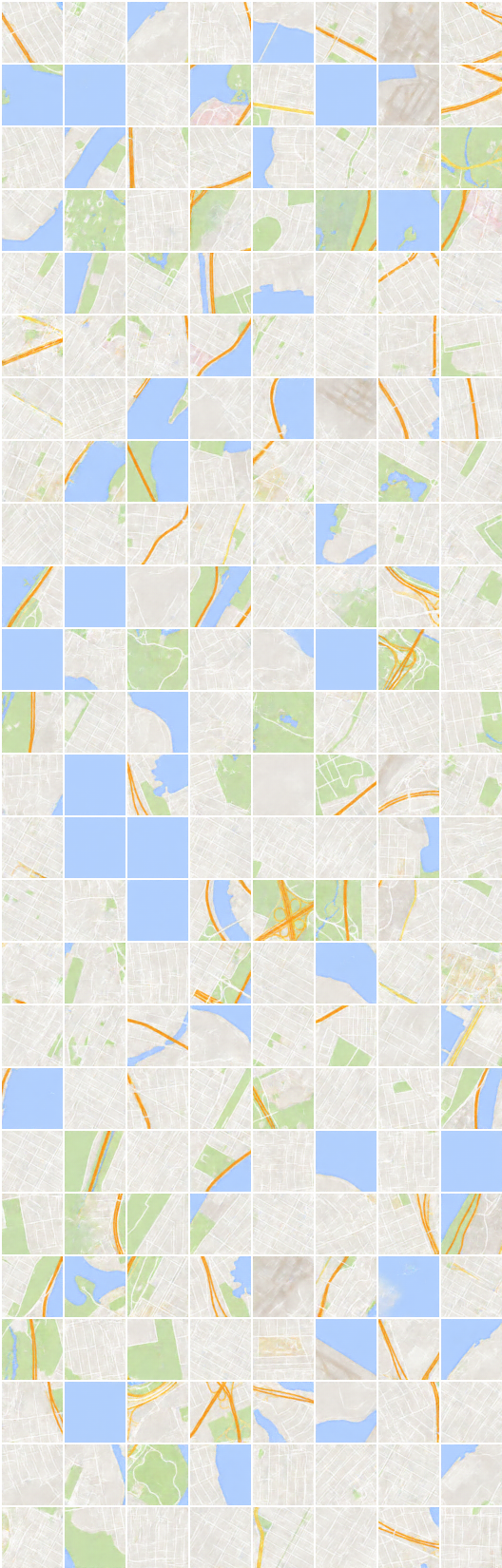

x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (segmentation -> image -> segmentation)

La génération et la reconstruction sur l'ensemble de données de segmentation dense semble bizarre qui ne sont pas incluses dans le document.
Je suppose qu'un choix naïf de perte mean square error pour la reconstruction nécessite un changement sur cet ensemble de données.
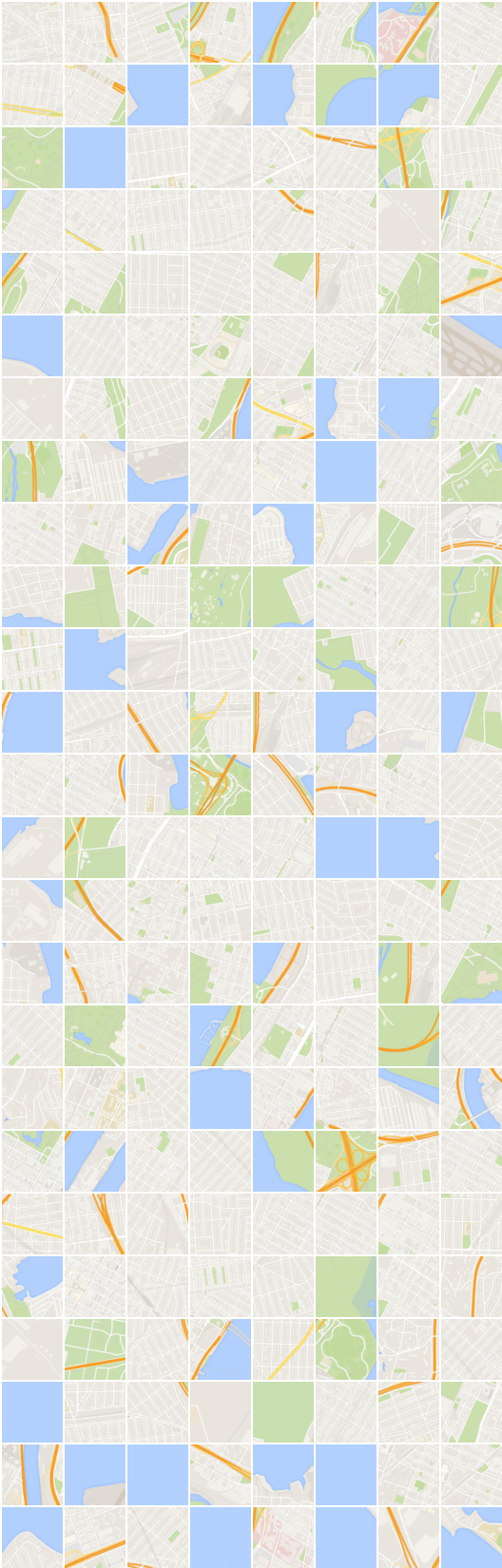
# itération: 19450 :
x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (image -> segmentation -> image)


x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (segmentation -> image -> segmentation)



Taehoon Kim / @ CARPEDM20


