DiscoGAN pytorch
1.0.0
A implementação de Pytorch do aprendizado para descobrir as relações entre domínios com redes adversárias generativas.
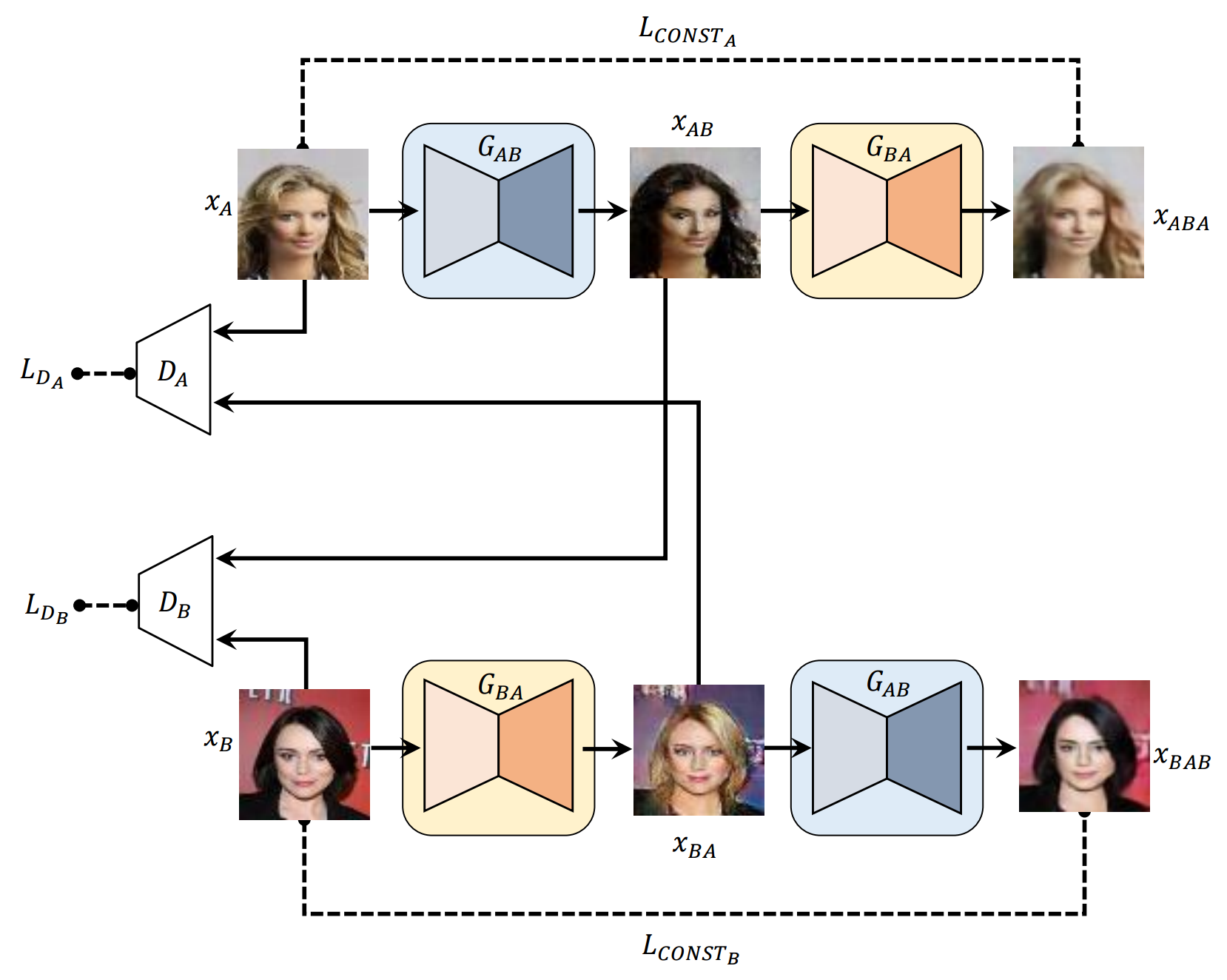
* Todas as amostras no readme.md são genilantes pela rede neural, exceto a primeira imagem para cada linha.
* A estrutura da rede é um pouco diferente (aqui) do código do autor.
Primeiro download de conjuntos de dados (de Pix2pix) com:
$ bash ./data/download_dataset.sh dataset_name
facades : 400 imagens do conjunto de dados do CMP Facades.cityscapes : 2975 imagens do conjunto de treinamento da Cityscapes.maps : 1096 Imagens de treinamento raspadas do Google Mapsedges2shoes : imagens de treinamento de 50k do conjunto de dados UT Zappos50k.edges2handbags : 137K Imagens de bolsas da Amazon do projeto IGAN.Ou você pode usar seu próprio conjunto de dados colocando imagens como:
data
├── YOUR_DATASET_NAME
│ ├── A
│ | ├── xxx.jpg (name doesn't matter)
│ | ├── yyy.jpg
│ | └── ...
│ └── B
│ ├── zzz.jpg
│ ├── www.jpg
│ └── ...
└── download_dataset.sh
Todas as imagens em cada conjunto de dados devem ter o mesmo tamanho , como usar o ImageMagick:
# for Ubuntu
$ sudo apt-get install imagemagick
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/A/*.jpg
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/B/*.jpg
# for Mac
$ brew install imagemagick
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/A/*.jpg
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/B/*.jpg
# for scale and center crop
$ mogrify -resize 256x256^ -gravity center -crop 256x256+0+0 -quality 100 -path ../A/*.jpg
Para treinar um modelo:
$ python main.py --dataset=edges2shoes --num_gpu=1
$ python main.py --dataset=YOUR_DATASET_NAME --num_gpu=4
Para testar um modelo (use seu load_path ):
$ python main.py --dataset=edges2handbags --load_path=logs/edges2handbags_2017-03-18_10-55-37 --num_gpu=0 --is_train=False
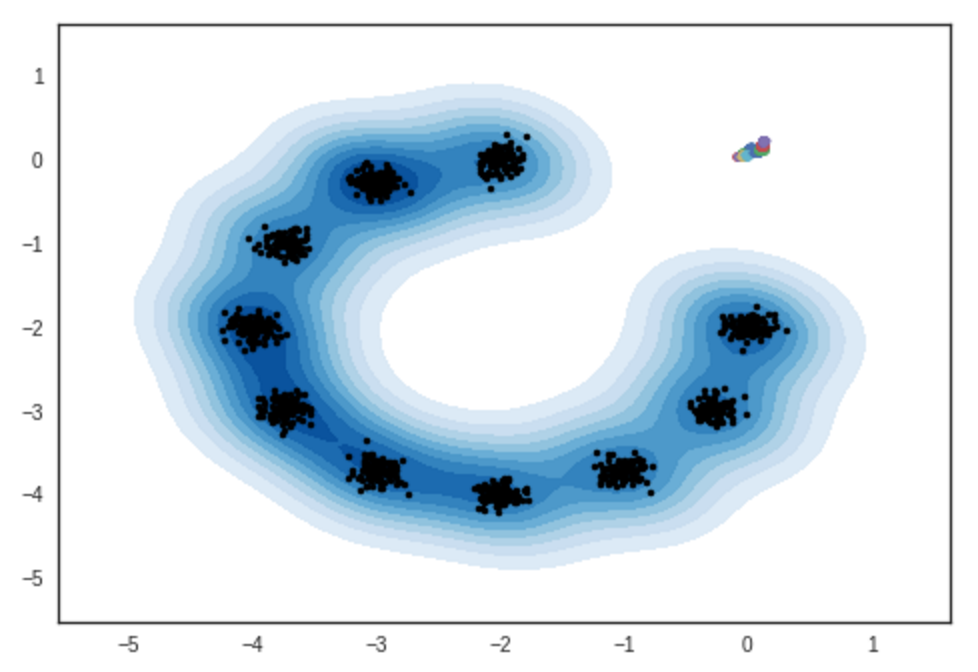
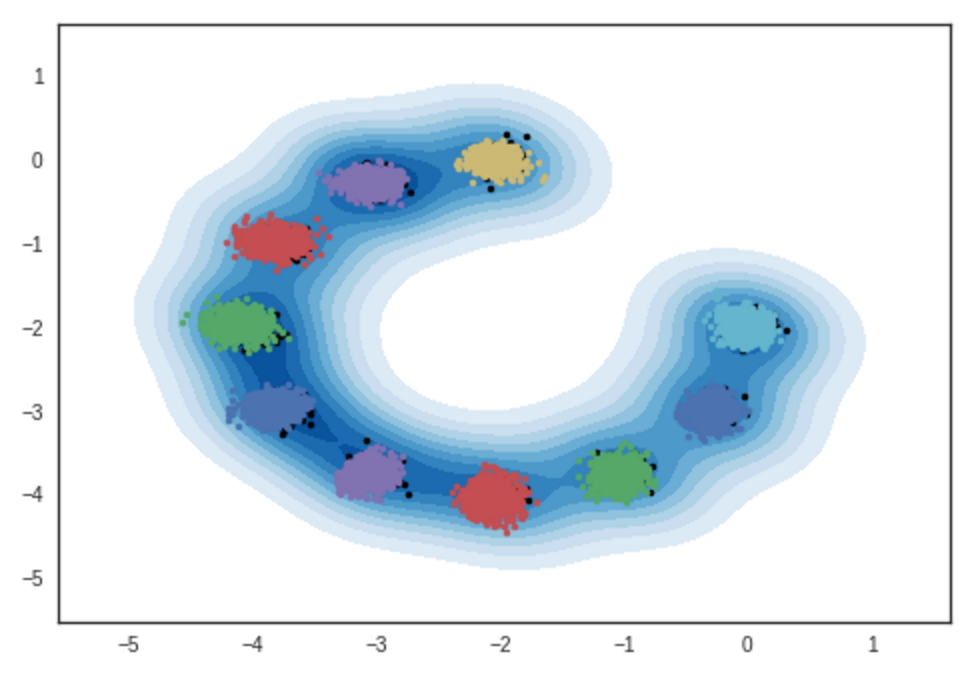
Resultado de amostras de modelos bidimensionais de mistura gaussiana. Notebook Ipython
# iteração: 0 :
# iteração: 10000 :
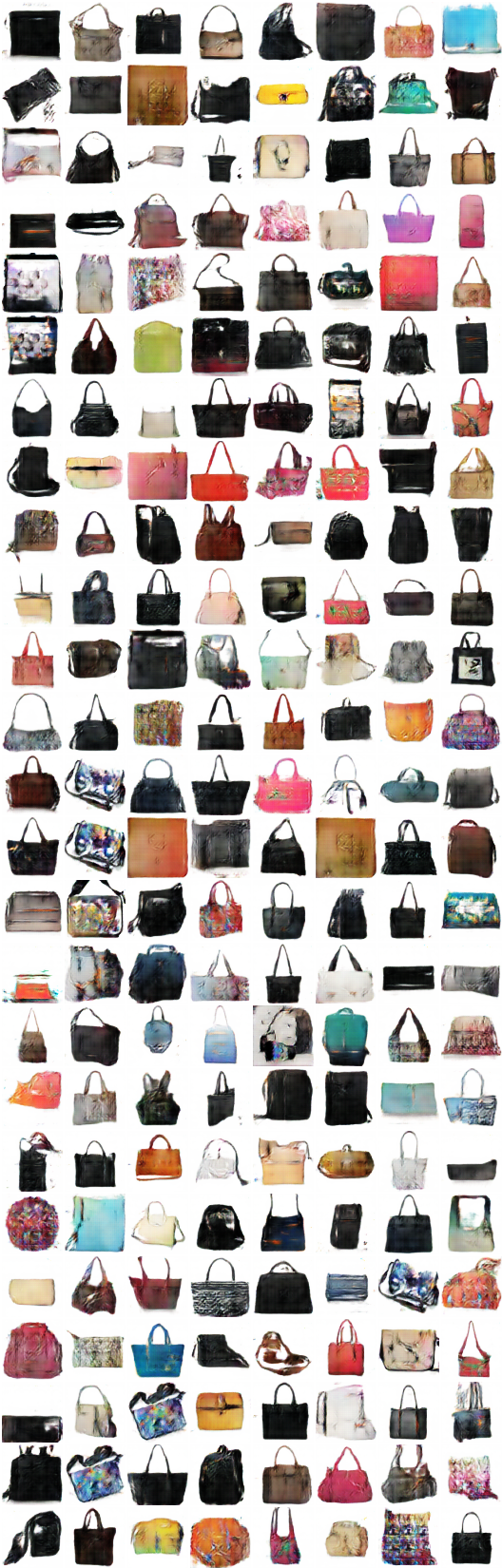
# iteração: 11200 :
x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (sapato -> bolsa -> sapato)



x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (bolsa -> sapato -> bolsa)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) -> G_AB(G_BA(G_AB(x_A))) -> G_BA(G_AB(G_BA(G_AB(x_A)))) -> ...







# iteração: 9600 :
x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (cor -> esboço -> cor)



x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (esboço -> cor -> esboço)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) -> G_AB(G_BA(G_AB(x_A))) -> G_BA(G_AB(G_BA(G_AB(x_A)))) -> ...







# iteração: 9500 :
x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (cor -> esboço -> cor)


x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (esboço -> cor -> esboço)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) -> G_AB(G_BA(G_AB(x_A))) -> G_BA(G_AB(G_BA(G_AB(x_A)))) -> ...







# iteração: 8350 :
x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (imagem -> segmentação -> imagem)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (segmentação -> imagem -> segmentação)



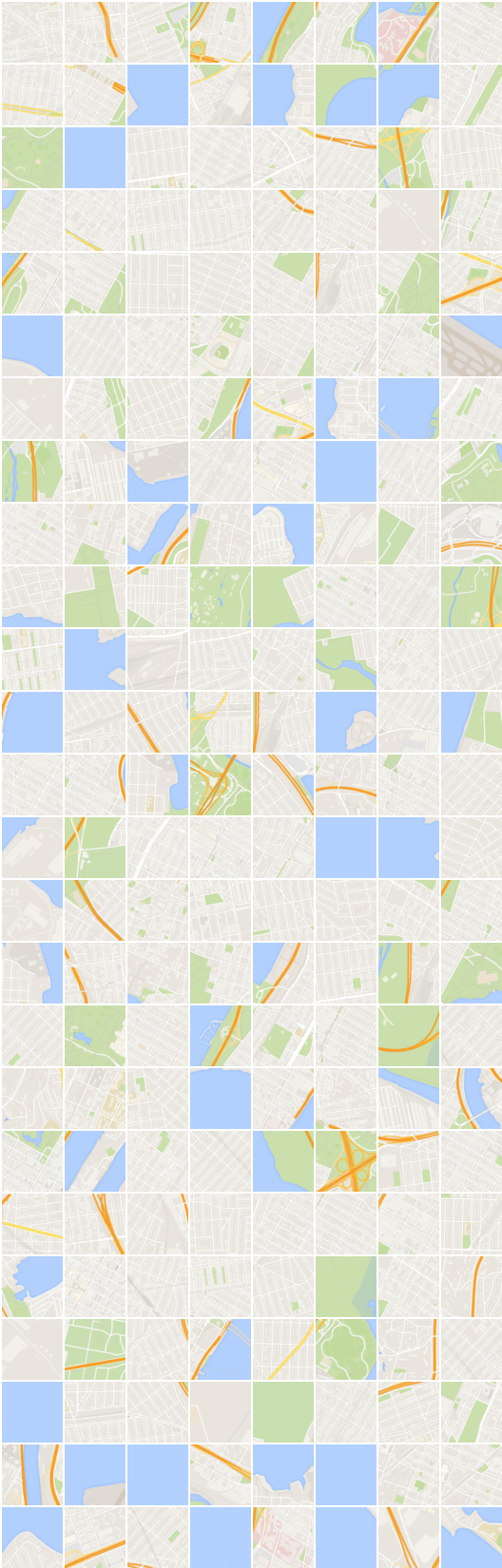
# iteração: 22200 :
x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (imagem -> segmentação -> imagem)

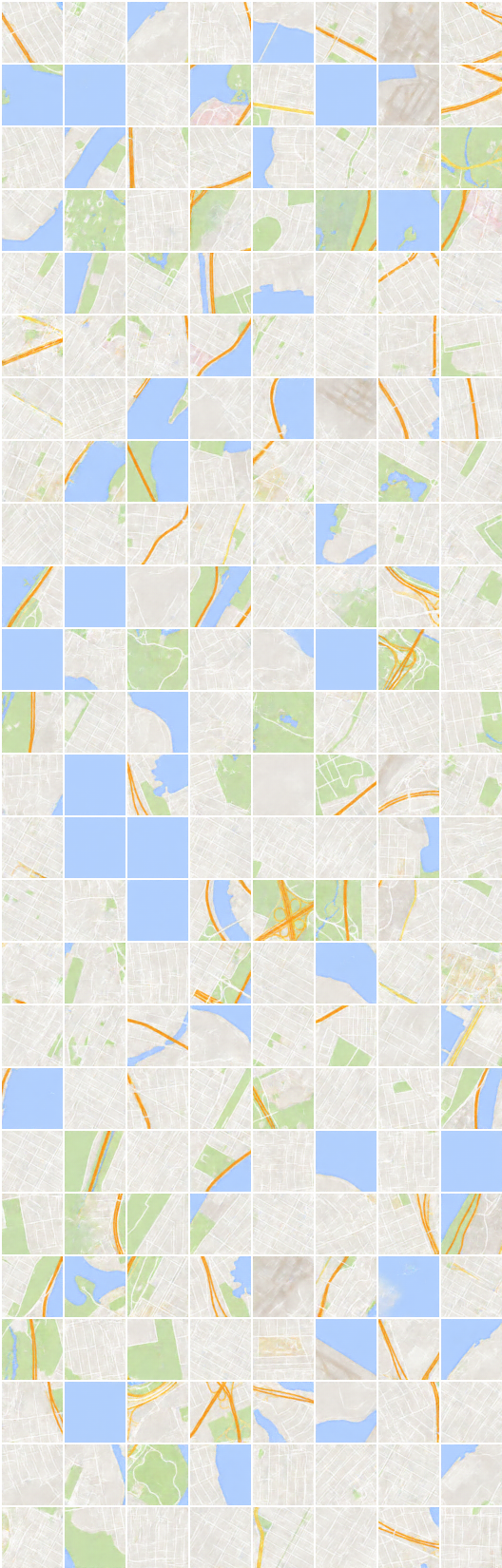

x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (segmentação -> imagem -> segmentação)

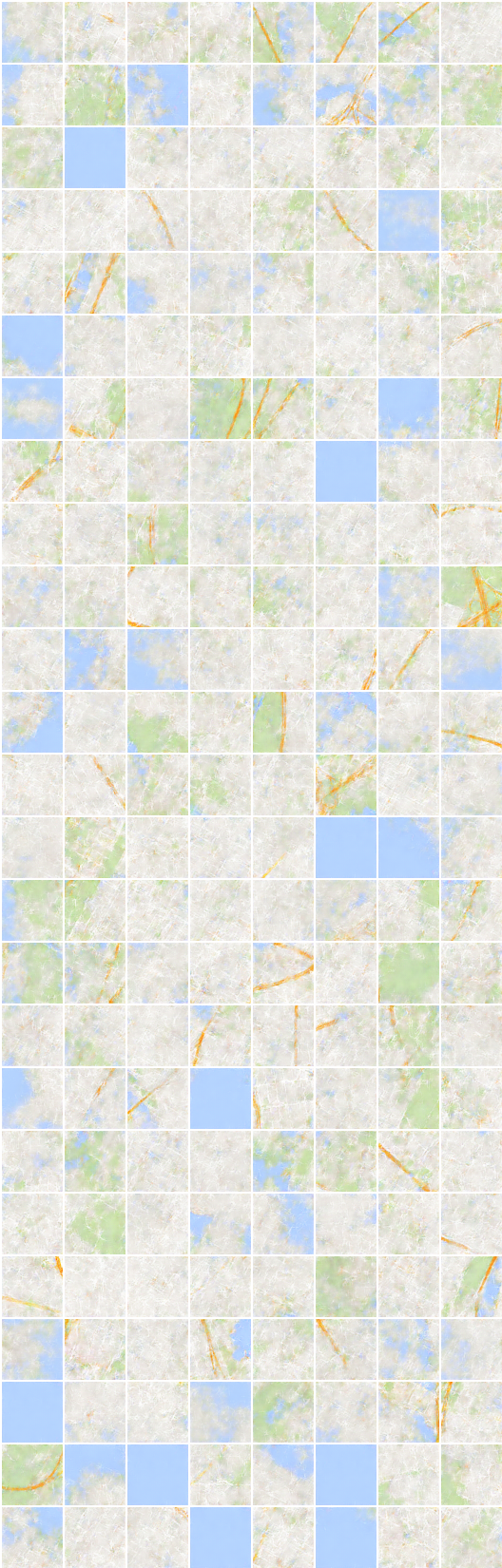
A geração e a reconstrução no conjunto de dados de segmentação densa parece estranho, que não estão incluídas no artigo.
Eu acho que uma escolha ingênua de perda mean square error para reconstrução precisa de alguma alteração nesse conjunto de dados.
# iteração: 19450 :
x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (imagem -> segmentação -> imagem)

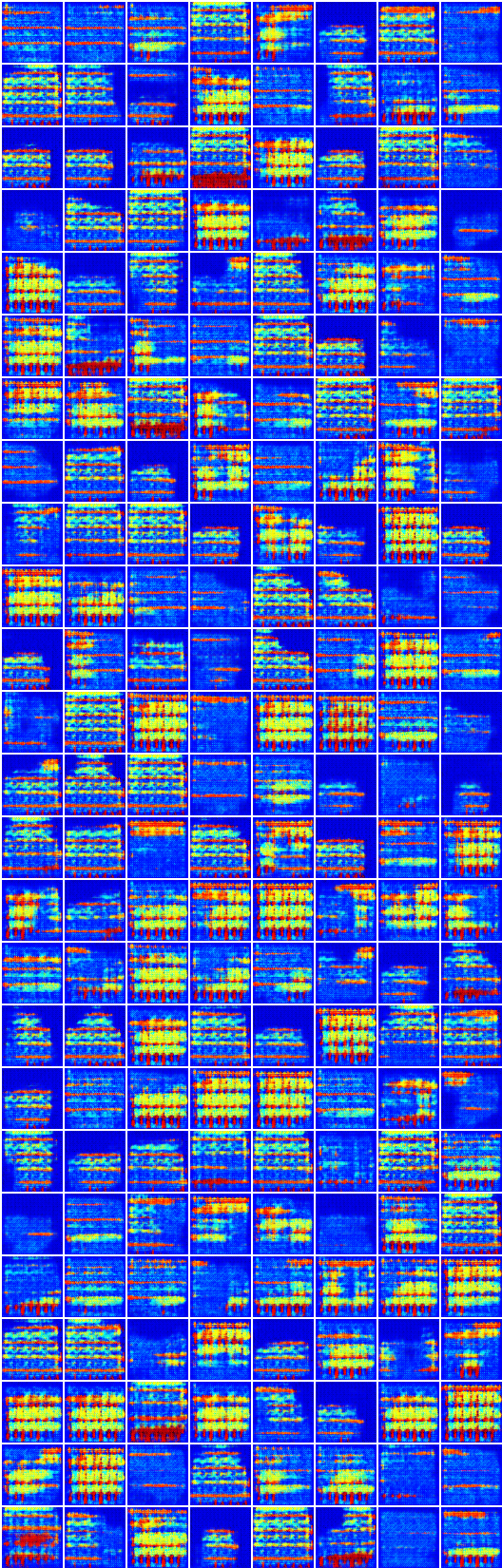

x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (segmentação -> imagem -> segmentação)



Taehoon kim / @carpedm20


