DiscoGAN pytorch
1.0.0
Implementación de Pytorch del aprendizaje para descubrir relaciones entre dominios con redes adversas generativas.
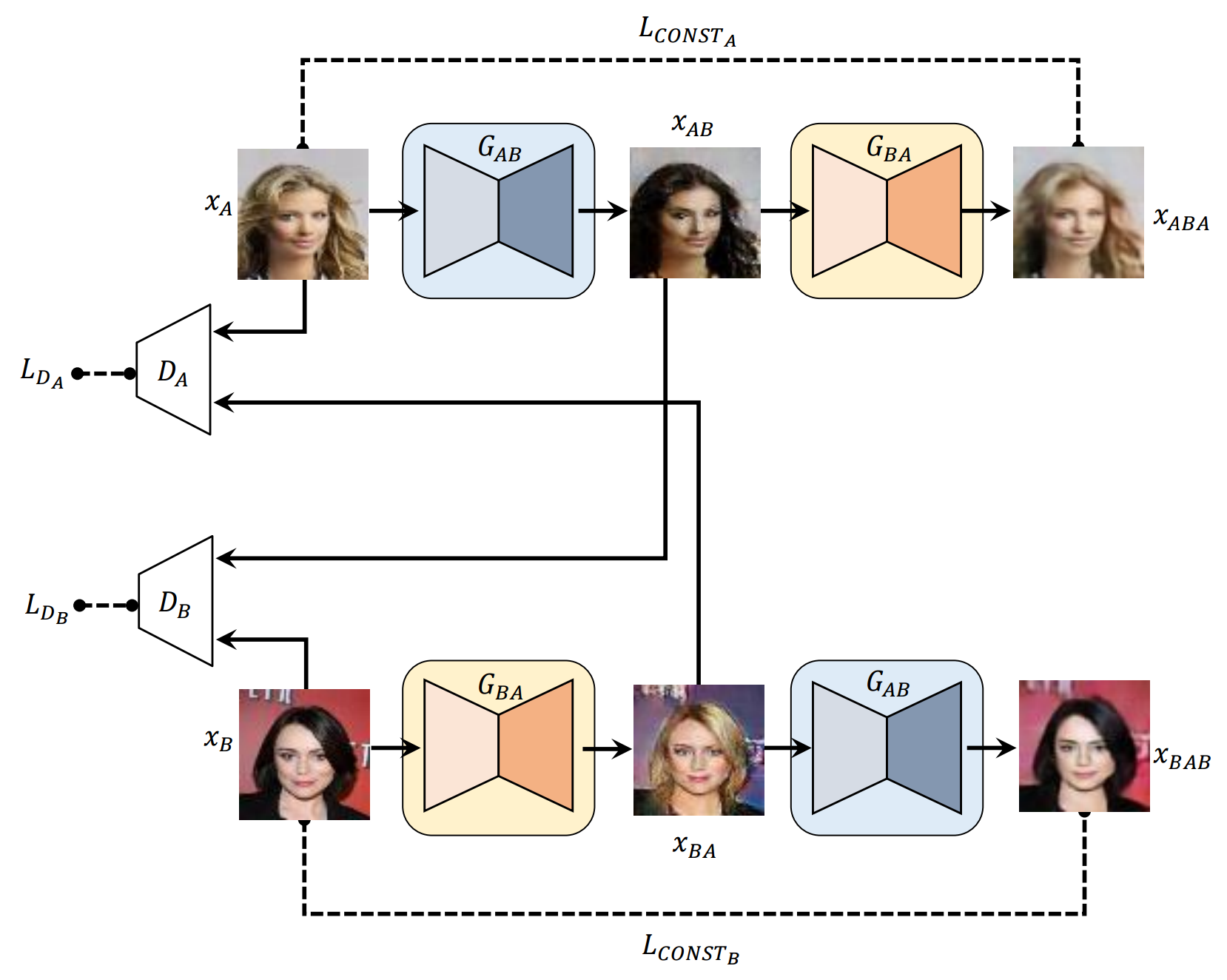
* Todas las muestras en ReadMe.md son geniales por la red neuronal, excepto la primera imagen para cada fila.
* La estructura de la red es ligeramente diferente (aquí) del código del autor.
Primero descargue los conjuntos de datos (de Pix2pix) con:
$ bash ./data/download_dataset.sh dataset_name
facades : 400 imágenes del conjunto de datos CMP Facades.cityscapes : 2975 imágenes del conjunto de entrenamiento de paisajes urbanos.maps : 1096 imágenes de entrenamiento raspadas de Google Mapsedges2shoes : 50k Imágenes de entrenamiento del conjunto de datos UT Zappos50k.edges2handbags : 137k imágenes de bolsos de Amazon del proyecto IGAN.O puede usar su propio conjunto de datos colocando imágenes como:
data
├── YOUR_DATASET_NAME
│ ├── A
│ | ├── xxx.jpg (name doesn't matter)
│ | ├── yyy.jpg
│ | └── ...
│ └── B
│ ├── zzz.jpg
│ ├── www.jpg
│ └── ...
└── download_dataset.sh
Todas las imágenes en cada conjunto de datos deben tener el mismo tamaño como usar ImageMagick:
# for Ubuntu
$ sudo apt-get install imagemagick
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/A/*.jpg
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/B/*.jpg
# for Mac
$ brew install imagemagick
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/A/*.jpg
$ mogrify -resize 256x256! -quality 100 -path YOUR_DATASET_NAME/B/*.jpg
# for scale and center crop
$ mogrify -resize 256x256^ -gravity center -crop 256x256+0+0 -quality 100 -path ../A/*.jpg
Para entrenar un modelo:
$ python main.py --dataset=edges2shoes --num_gpu=1
$ python main.py --dataset=YOUR_DATASET_NAME --num_gpu=4
Para probar un modelo (use su load_path ):
$ python main.py --dataset=edges2handbags --load_path=logs/edges2handbags_2017-03-18_10-55-37 --num_gpu=0 --is_train=False
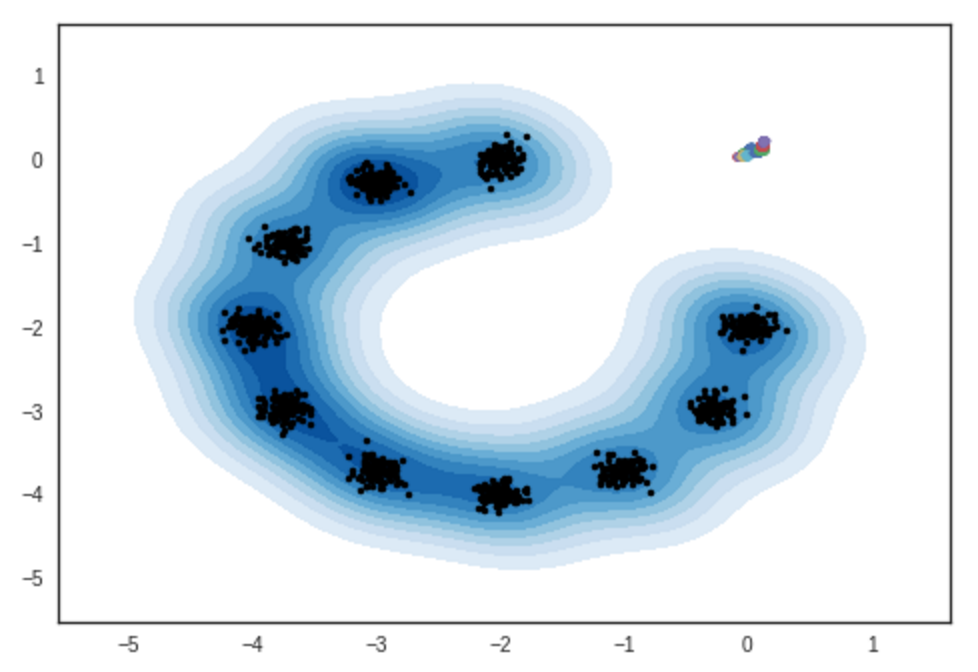
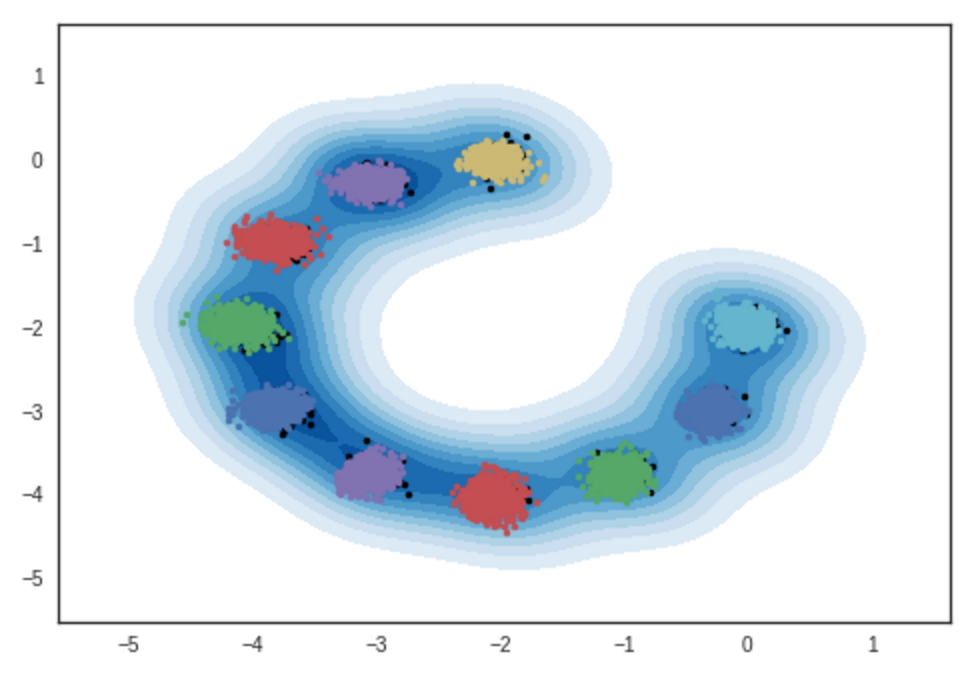
Resultado de muestras de modelos de mezcla gaussianas bidimensionales. Cuaderno de ipython
# iteración: 0 :
# iteración: 10000 :
# iteración: 11200 :
x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (zapato -> bolso -> zapato)



x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (bolso -> zapato -> bolso)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) -> G_AB(G_BA(G_AB(x_A))) -> G_BA(G_AB(G_BA(G_AB(x_A)))) -> ... ...







# iteración: 9600 :
x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (color -> boceto -> color)



x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (Sketch -> Color -> Sketch)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) -> G_AB(G_BA(G_AB(x_A))) -> G_BA(G_AB(G_BA(G_AB(x_A)))) -> ... ...







# iteración: 9500 :
x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (color -> boceto -> color)


x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (Sketch -> Color -> Sketch)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) -> G_AB(G_BA(G_AB(x_A))) -> G_BA(G_AB(G_BA(G_AB(x_A)))) -> ... ...







# iteración: 8350 :
x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (imagen -> segmentación -> imagen)



x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (segmentación -> imagen -> segmentación)



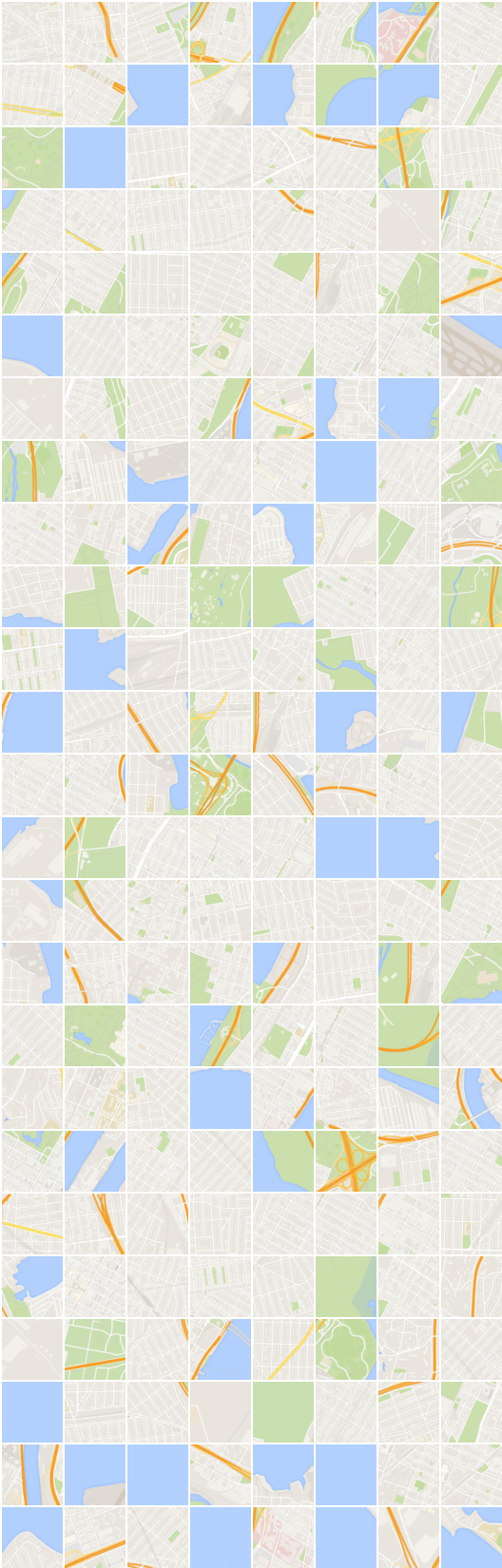
# iteración: 22200 :
x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (imagen -> segmentación -> imagen)

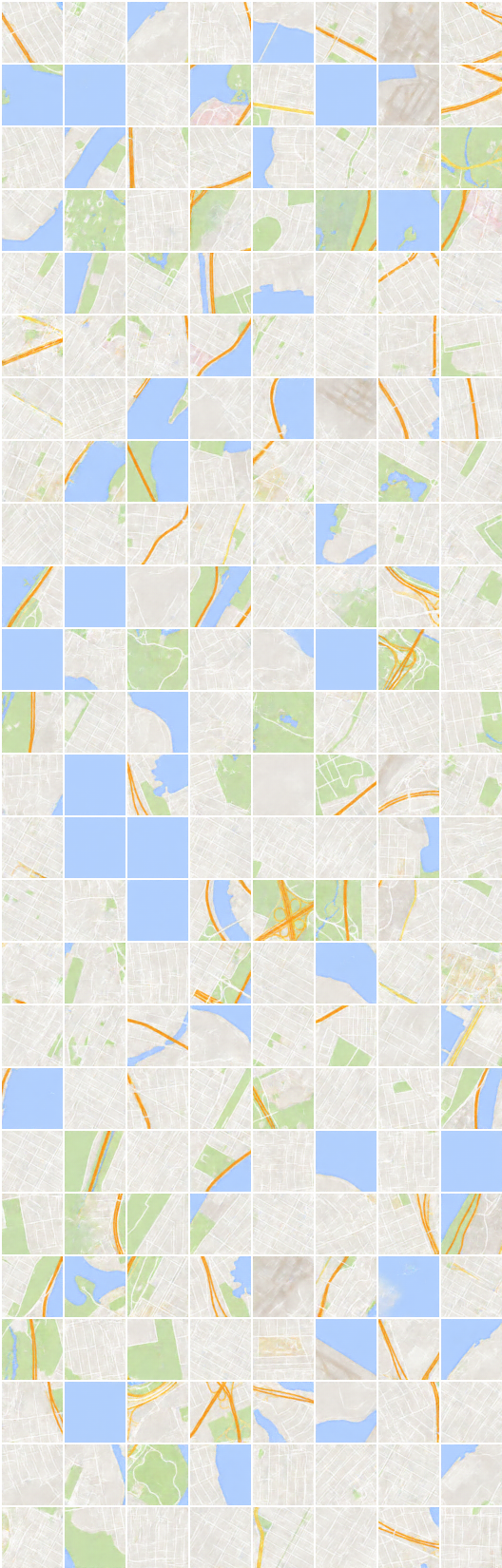

x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (segmentación -> imagen -> segmentación)

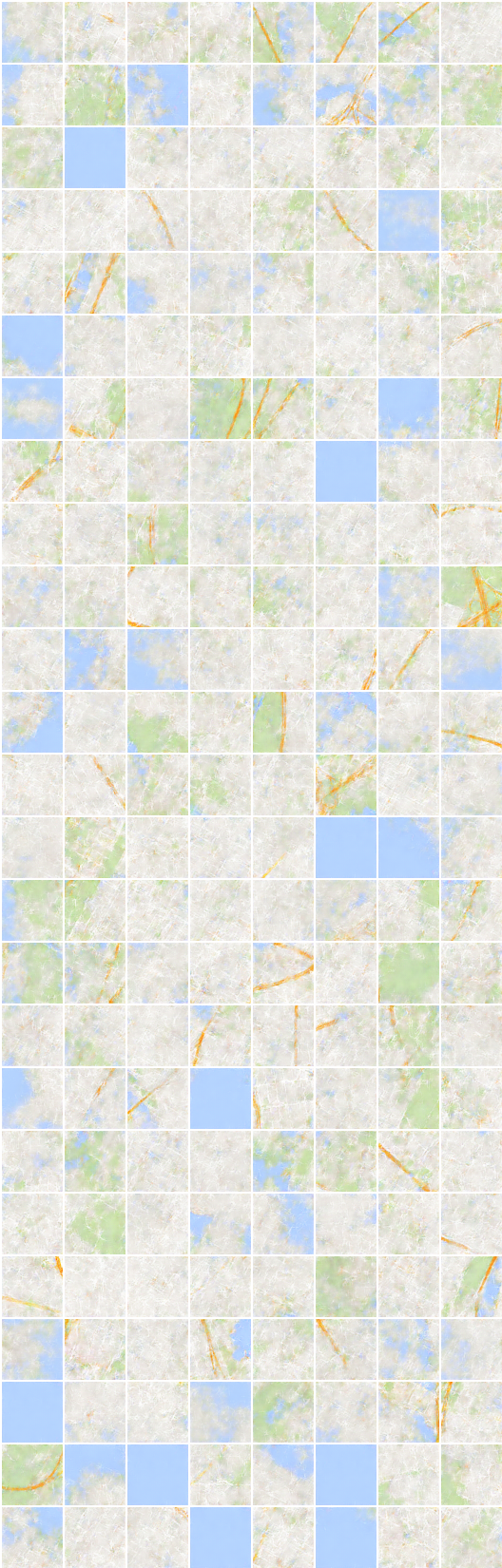
Generación y reconstrucción en el conjunto de datos de segmentación densa se ve raro que no se incluyen en el documento.
Supongo que una elección ingenua de la pérdida mean square error para la reconstrucción necesita algún cambio en este conjunto de datos.
# iteración: 19450 :
x_B -> G_BA(x_B) -> G_AB(G_BA(x_B)) (imagen -> segmentación -> imagen)

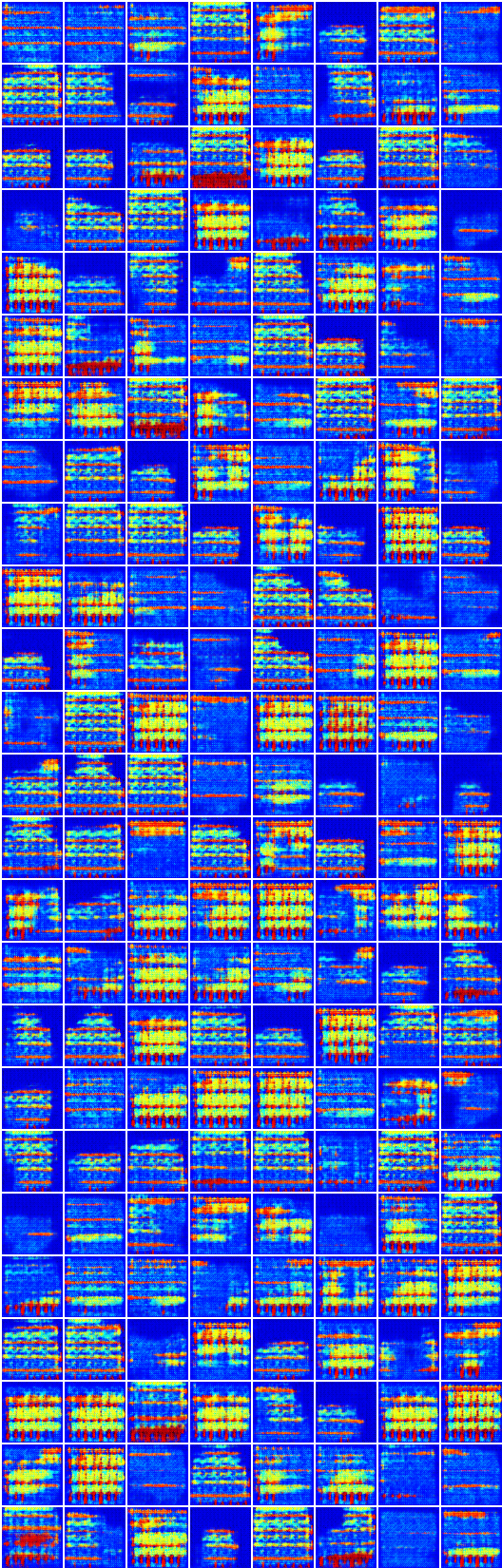

x_A -> G_AB(x_A) -> G_BA(G_AB(x_A)) (segmentación -> imagen -> segmentación)



Taehoon Kim / @carpedm20


