TSP_ACO
1.0.0
Ant Colony Optimization (ACO) เป็นเทคนิคการใช้เมตา-ฮิวริสติกในสาขาข่าวกรองฝูง มันใช้สำหรับการแก้ปัญหาการเพิ่มประสิทธิภาพ combinatorial ที่แตกต่างกัน
ACO ขึ้นอยู่กับพฤติกรรมของอาณานิคมมดและความสามารถในการค้นหาสำหรับการเพิ่มประสิทธิภาพ combinatorial การวิเคราะห์พฤติกรรมตามธรรมชาติของอาณานิคมมดแสดงให้เห็นว่ามดเคลื่อนที่ไปตามการกระจายฟีโรโมนที่อุดมสมบูรณ์บนเส้นทางของพวกเขา อัลกอริทึมเลียนแบบพฤติกรรมนี้
ปัญหาพนักงานขายการเดินทาง (TSP) เป็นปัญหาอัลกอริทึมคลาสสิกที่มุ่งเน้นไปที่การเพิ่มประสิทธิภาพ
ทางออกที่ดีกว่ามักหมายถึงวิธีแก้ปัญหาที่ถูกกว่าสั้นลงหรือเร็วขึ้น
ปัญหาอธิบายพนักงานขายที่ต้องเดินทางระหว่างเมือง N เช่นที่เขาไปเยี่ยมแต่ละเมืองหนึ่งครั้งในระหว่างการเดินทางของเขา แต่ละเมืองเชื่อมต่อกับเมืองอื่น ๆ และลิงก์มีน้ำหนักคงที่ (ค่าเดินทางระยะทาง ฯลฯ )
ชุดข้อมูลประกอบด้วย 225 เมืองในภาคตะวันตกเฉียงเหนือและภาคกลางของทวีปย่อยอินเดีย
tsp dataset/
├── distance.txt
├── location_ll.txt
├── location_map.jpg
├── location_map_satellite_image.jpg
├── names.txt
├── road_distance.txt
└── travel_time.txt
| ไฟล์ | คำอธิบาย |
|---|---|
| location_ll.txt | พื้นที่ที่แยกพื้นที่ทางภูมิศาสตร์ (ละติจูดและลองจิจูด) ของแต่ละเมือง |
| ระยะทาง txt | ระยะห่างระหว่างเมือง Eucledian ระหว่างเมือง |
| Road_distance.txt | ระยะทางตามถนนระหว่างเมือง |
| travel_time.txt | ใช้เวลาในการเดินทางจากเมืองหนึ่งไปยังอีกเมืองหนึ่ง |
ในระบบมดอาณานิคม (ACS) มดเทียมจำนวนหนึ่งจะถูกวางไว้ที่เมืองสุ่ม มดแต่ละตัวสร้างทัวร์ (ทางออกที่เป็นไปได้ของ TSP) มันเลือกเมืองต่อไปโดยใช้ กฎการเปลี่ยนแปลงของรัฐ (กฎโลภ) กฎนี้ให้ความสมดุลระหว่างการสำรวจขอบใหม่และการใช้ประโยชน์จากความรู้สะสม
ฟีโรโมนจำนวนคงที่จะถูกฝากโดยมดแต่ละครั้งในแต่ละขั้นตอนในเส้นทางที่ดีที่สุด (ทัวร์ที่ดีที่สุด)
การใช้วิธีการชั้นนำเราพยายามควบคุมพารามิเตอร์การเรียนรู้ มดที่หาเส้นทางที่ดีที่สุด (คุณภาพ) ได้รับรางวัลมากขึ้นว่ามดตัวอื่น ๆ ฟีโรโมนมากขึ้นจะถูกฝากบนเส้นทางที่ดีกว่าให้ความสำคัญกับทัวร์นั้นและลดเวลาเพื่อรับทางออกที่ดีที่สุด
ปริมาณฟีโรโมนที่สะสมอยู่ในคุณภาพของเส้นทาง
วิธี Maxmin มีจุดมุ่งหมายเพื่อให้ได้สิ่งที่ดีที่สุดของทั้งสองโลกซึ่งเป็นโซลูชันที่ใกล้เคียงกับที่ดีที่สุดพร้อมเวลาดำเนินการอย่างรวดเร็ว นี่คือความสำเร็จโดยการเปลี่ยนแปลงจำนวนฟีโรโมนที่ฝากผ่านขั้นตอน
ในขั้นต้นน้ำหนักสูงให้อัตราการเรียนรู้อย่างรวดเร็ว น้ำหนักค่อยๆลดลงจนถึง 75% จากนั้นโมเดลถ้าปรับน้ำหนักโดยการใช้น้ำหนักโดยเปรียบเทียบผลลัพธ์กับ ทัวร์ที่ดีที่สุดทั่วโลก
ในตอนท้ายของแต่ละขั้นตอนน้ำหนักจะถูกผูกไว้ภายในขีด จำกัด ของฟีโรโมนสูงสุดและขั้นต่ำเพื่อป้องกันการแก้ปัญหาในการทำงานที่หลงทาง
ปริมาณฟีโรโมนค่อยๆลดลงสำหรับ 75% แรกของการวนซ้ำ จากนั้นจำนวนเงินขึ้นอยู่กับคุณภาพเมื่อเทียบกับทัวร์ที่ดีที่สุด
params = {
'_colony_size' : "number of ants in the colony" ( default = 15 ),
'_steps' : "iteration to run through" ( default = 50 ),
'_mode' : "mode of algorithm to run the model"
} # Import model
from aco_tsp import SolveTSPUsingACO
# Setup parameters
_colony_size = 15
_steps = 50
# Select mode
# ['ACS', 'Elitist', 'MaxMin']
_mode = 'ACS'
# Nodes (latitude and longitude)
_nodes = [( 20.05961 , 77.949783 ), ( 17.075451 , 74.628664 ), ..., ( 19.4133545 , 80.0059101 )]
s
# Model setup and run
model = SolveTSPUsingACO (
mode = _mode ,
colony_size = _colony_size ,
steps = _steps ,
nodes = _nodes
)
runtime , distance = model . run () ด้วยความช่วยเหลือของ ACO เราสร้างเส้นทางที่ดีที่สุดเพื่อครอบคลุมทุกเมืองในขณะที่พยายามลดระยะการเดินทางให้น้อยที่สุด นอกจากนี้ผลลัพธ์ขึ้นอยู่กับพารามิเตอร์ของอัลกอริทึมและน้ำหนักขอบ (travel time, distance, road_distance) ที่ใช้ในการปรับเส้นทางให้เหมาะสม
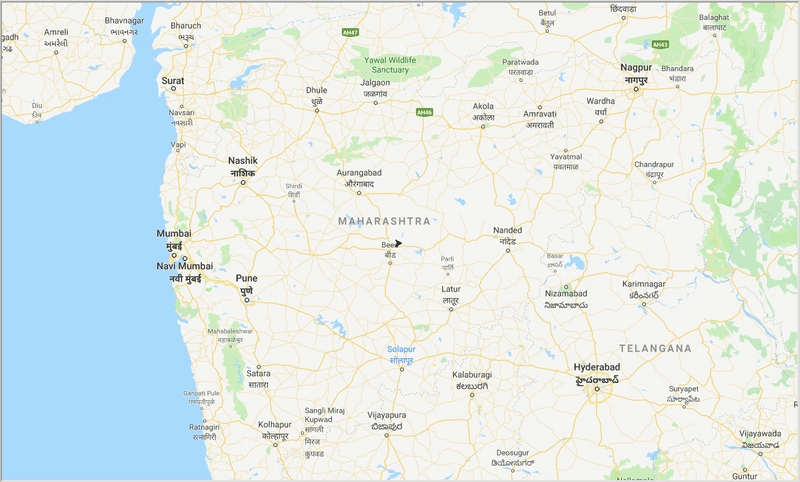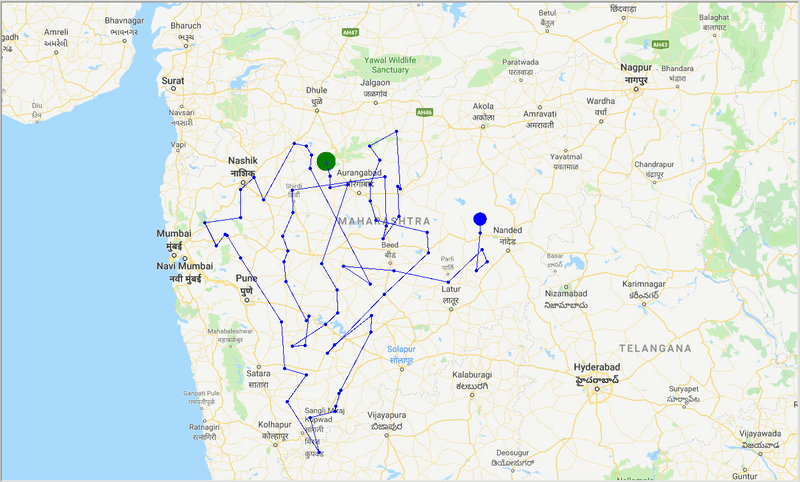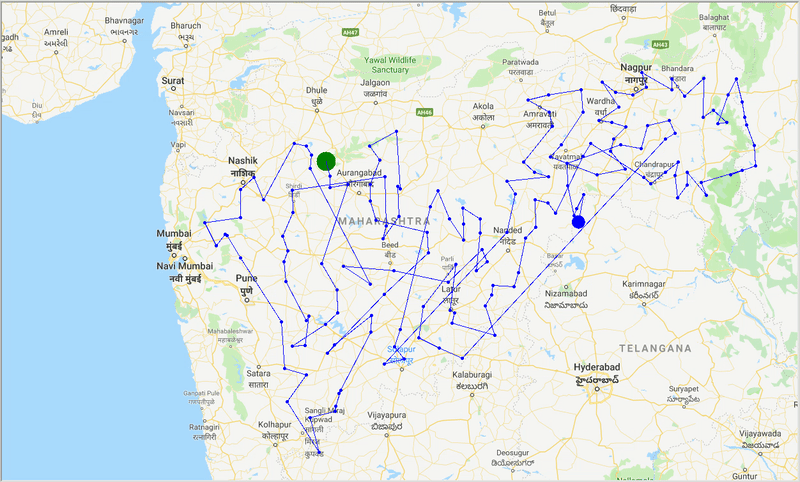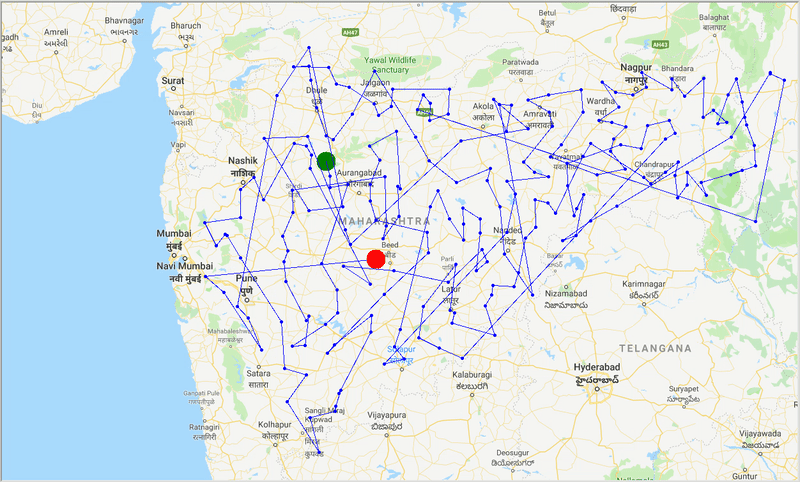
รูป: ร่องรอยของเส้นทางที่ดีที่สุดผ่านเมืองต่างๆ


