PWC RAG
1.0.0
ผ้าขี้ริ้วสำหรับเอกสารที่มีรหัสเป็นวิธีที่ง่ายกว่าในการสแกนผ่านการวิจัย ML จำนวนมากโดยเพียงกดปุ่ม ระบบผ้าขี้ริ้วที่ทำเหมืองข้อมูลจำนวนมากได้อย่างง่ายดาย คุณจะถามคำถามของคุณเป็นภาษาธรรมชาติและจะตอบตามเอกสารที่เกี่ยวข้องที่พบในเอกสารที่มีรหัส
ในด้านแบ็คเอนด์ระบบขับเคลื่อนด้วยเฟรมเวิร์ก Augmented Generation (RAG) ที่ขึ้นอยู่กับฐานข้อมูลเวกเตอร์ที่ไม่สามารถปรับขนาดได้ที่เรียกว่า upstash สำหรับการฝังตัวเราใช้รุ่น BGE บน Huggingface และ Mixtral-8x7b-instruct-v0.1
ในด้านส่วนหน้าผู้ช่วยนี้จะถูกรวมเข้ากับเว็บแอปพลิเคชันแบบอินเทอร์แอคทีฟและปรับใช้งานได้ง่ายที่สร้างขึ้นด้วย Streamlit
โคลน repo
git clone https://github.com/wittyicon29/PWC-RAG.gitย้ายไปที่ไดเรกทอรีพื้นที่ทำงาน
cd PWC-RAG การจัดทำดัชนีเพื่อดัชนีข้อมูลลงในเวกเตอร์ DB ก่อนอื่นคุณต้องสร้างดัชนีบน upstash และกรอกข้อมูลในข้อมูลรับรองในไฟล์ .env :
UPSTASH_URL=...
UPSTASH_TOKEN=...
เรียกใช้คำสั่งต่อไปนี้:
python -m src.index_papers --query " Mistral " --limit 200ผลลัพธ์ของการจัดทำดัชนี 200 ชิ้นที่ตรงกับแบบสอบถาม "mistral"

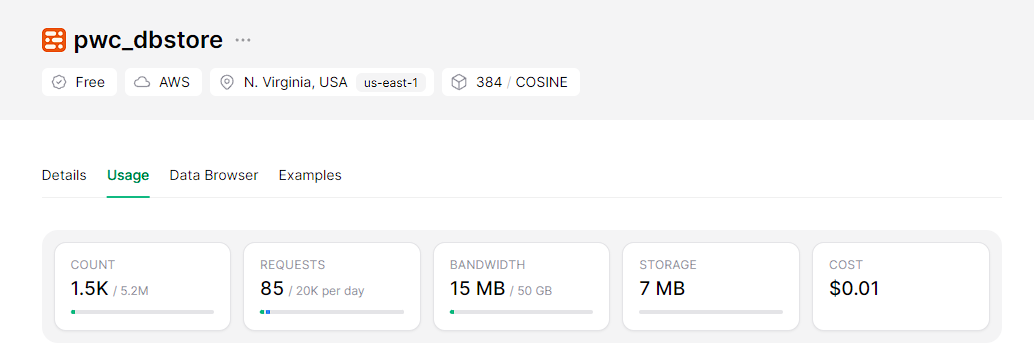
เรียกใช้แอปพลิเคชัน Streamlit ในเครื่อง
ก่อนที่จะเรียกใช้แอพ streamlit คุณต้องตั้งค่าโทเค็น HuggingFace API ในไฟล์ '.env':
HUGGINGFACE_API_TOKEN=...ตอนนี้คุณสามารถใช้แอป Streamlit
python -m streamlit run src/app.py
วิธีสร้างแอพที่ใช้พลังงาน LLM เพื่อแชทกับ PapersWithCode


