PWC RAG
1.0.0
RAG para documentos con código es un método más fácil para escanear a través de toneladas de investigación de ML simplemente presionando un botón. Un sistema de trapo que minera una gran cantidad de información fácilmente. Le hará sus preguntas en lenguaje natural y responderá de acuerdo con los documentos relevantes que encuentra en los documentos con código.
En el lado de backend, el sistema funciona con un marco de generación aumentada de recuperación (RAG) que se basa en una base de datos vectorial sin servidor escalable llamada UpShash, para incrustaciones estamos utilizando modelos BGE en la cara de abrazo y mixtral-8x7b-Instruct-V0.1 como LLM de Huggingface.
En el lado delantero, este asistente se integrará en una aplicación web interactiva y fácil de implementar construida con Streamlit.
Clonar el repositorio
git clone https://github.com/wittyicon29/PWC-RAG.gitMudarse al directorio del espacio de trabajo
cd PWC-RAG Indexación para indexar datos en el Vector DB, primero debe crear un índice en Upstash y completar las credenciales en el archivo .env :
UPSTASH_URL=...
UPSTASH_TOKEN=...
Ejecute el siguiente comando:
python -m src.index_papers --query " Mistral " --limit 200Resultado de indexar 200 fragmentos que coinciden con la consulta "Mistral".

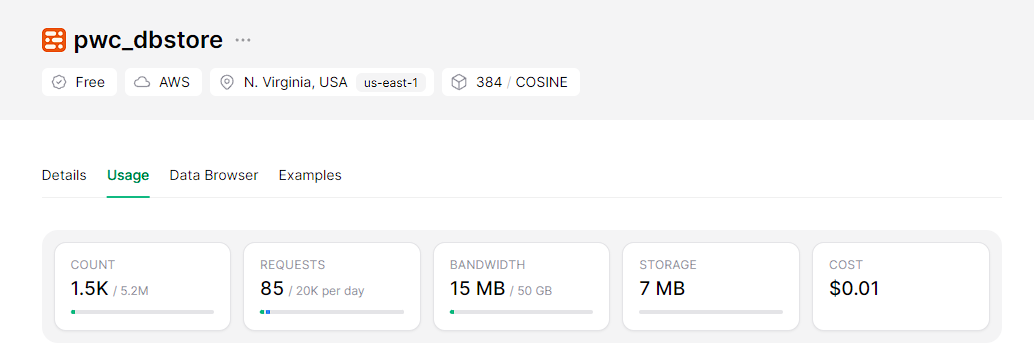
Ejecutando las aplicaciones de transmisión a nivel local
Antes de ejecutar la aplicación Streamlit, debe configurar el token de la API Huggingface en el archivo '.env':
HUGGINGFACE_API_TOKEN=...Ahora puedes la aplicación de transmisión
python -m streamlit run src/app.py
Cómo construir una aplicación alimentada por LLM para chatear con papel con código


