PWC RAG
1.0.0
Lag für Papiere mit Code ist eine einfachere Methode, um Tonnen von ML -Forschung zu durchsuchen, indem Sie einfach auf eine Taste klicken. Ein Lappensystem, das eine große Menge an Informationen leicht abgibt. Sie werden ihm Ihre Fragen in der natürlichen Sprache stellen und es wird nach relevanten Arbeiten beantwortet, die es auf Papieren mit Code findet.
Auf der Backend-Seite wird das System mit einem RA-Framework (Abruf Augmented Generation) betrieben, der sich auf einer skalierbaren serverlosen Vektor-Datenbank namens UPSSTASH basiert. Für Einbettungen verwenden wir BGE-Modelle auf dem Umarmungsface und Mixtral-8x7b-Instruct-V0.1 als LLM aus dem Umarmungsgefühl.
Auf der Front-End-Seite wird dieser Assistent in eine interaktive und einfach einsetzbare Webanwendung integriert, die mit Streamlit erstellt wurde.
Klonen Sie das Repo
git clone https://github.com/wittyicon29/PWC-RAG.gitWechseln Sie zum Arbeitsbereichsverzeichnis
cd PWC-RAG Indexierung für die Index von Daten in den Vektor -DB, müssen Sie zunächst einen Index für Upstash erstellen und die Anmeldeinformationen in der Datei .env eingeben:
UPSTASH_URL=...
UPSTASH_TOKEN=...
Führen Sie den folgenden Befehl aus:
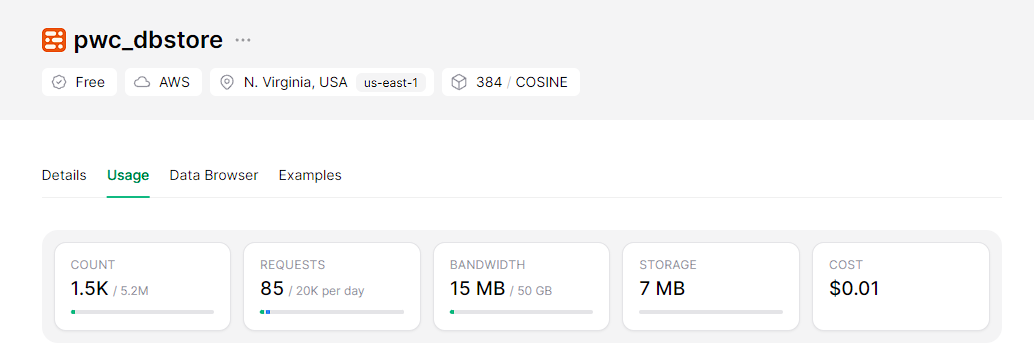
python -m src.index_papers --query " Mistral " --limit 200Ergebnis der Indexierung von 200 Stücken, die mit der "Mistral" -Anfrage übereinstimmen.

Ausführen der Stromanwendungen lokal ausführen
Bevor Sie die Streamlit -App ausführen, müssen Sie das HuggingFace -API -Token in der Datei '.env' festlegen:
HUGGINGFACE_API_TOKEN=...Jetzt können Sie die streamlit -App
python -m streamlit run src/app.py
So erstellen Sie eine LLM-Anbieter-App, um mit Papers mit demCode zu chatten


