PWC RAG
1.0.0
RAG for Papers With Code é um método mais fácil de digitalizar por meio de toneladas de pesquisa de ML, apenas pressionando um botão. Um sistema de pano que mina uma grande quantidade de informações facilmente. Você fará suas perguntas em linguagem natural e ele responderá de acordo com os documentos relevantes que encontram nos documentos com código.
No lado do back-end, o sistema é alimentado com uma estrutura de geração aumentada de recuperação (RAG) que depende de um banco de dados vetorial sem servidor escalonável chamado Upstash, para incorporações que estamos usando modelos BGE no HuggingFace e Mixtral-8x7B-URUCT-V0.1 como LLM do HuggingFace.
No lado do front-end, esse assistente será integrado a um aplicativo Web interativo e facilmente implantável, construído com o Streamlit.
Clone o repo
git clone https://github.com/wittyicon29/PWC-RAG.gitMova para o diretório do espaço de trabalho
cd PWC-RAG Indexação para indexar dados no banco de dados vetorial, primeiro você precisa criar um índice no upstash e preencher as credenciais no arquivo .env :
UPSTASH_URL=...
UPSTASH_TOKEN=...
Execute o seguinte comando:
python -m src.index_papers --query " Mistral " --limit 200Resultado da indexação de 200 pedaços que correspondem à consulta "Mistral".

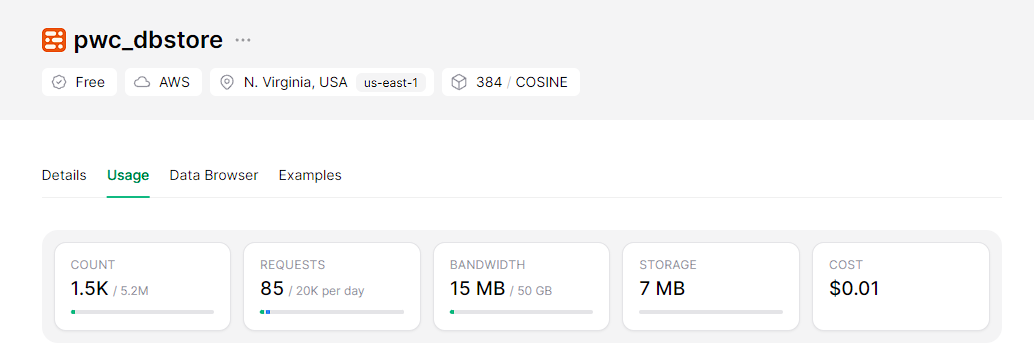
Executando os aplicativos de streamlit localmente
Antes de executar o aplicativo Streamlit, você deve definir o token da API Huggingface no arquivo '.env':
HUGGINGFACE_API_TOKEN=...Agora você pode o aplicativo Streamlit
python -m streamlit run src/app.py
Como construir um aplicativo movido a LLM para conversar com papéisWithCode


