PWC RAG
1.0.0
Тряпка для документов с кодом - более простой метод для сканирования тонн исследований ML, просто нажав кнопку. Тряпичная система, которая легко добывает большое количество информации. Вы зададите это ваши вопросы на естественном языке, и это ответит в соответствии с соответствующими документами, которые он найдет в документах с кодом.
На стороне бэкэнд система питается с помощью рамки из поиска с добычей наполненной генерации (RAG), которая опирается на масштабируемую векторную базу данных без сервера, называемую Upstash, для внедрения мы используем модели BGE на HuggingFace, а Mixtral-8x7b-Instruk-V0.1 в качестве LLM из HuggingFace.
На передней стороне этот помощник будет интегрирован в интерактивное и легко развертываемое веб-приложение, созданное с потоковой дорожкой.
Клонировать репо
git clone https://github.com/wittyicon29/PWC-RAG.gitПерейти в каталог рабочей области
cd PWC-RAG Индексирование для индекса данных в вектор DB, вам сначала необходимо создать индекс на Upstash и заполнить учетные данные в файле .env :
UPSTASH_URL=...
UPSTASH_TOKEN=...
Запустите следующую команду:
python -m src.index_papers --query " Mistral " --limit 200Результат индексации 200 кусков, соответствующих запросу «Мистерал».

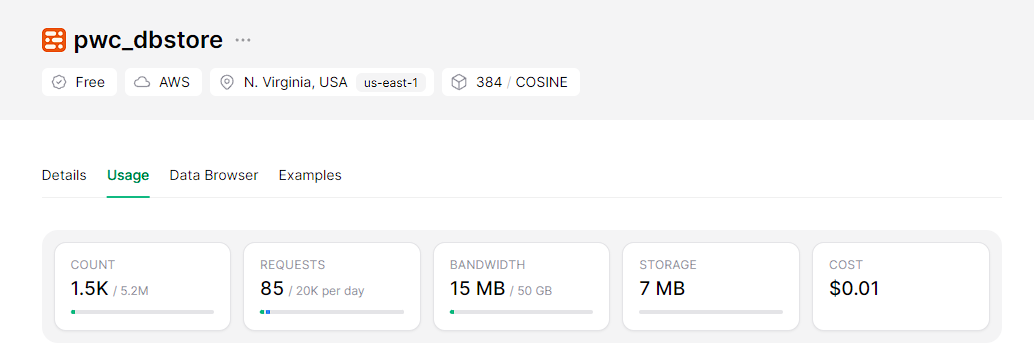
Запуск приложений по стриме локально
Перед запуском приложения StreamLit вы должны установить токен API AgingFace в файле '.env':
HUGGINGFACE_API_TOKEN=...Теперь вы можете приложение Streamlit
python -m streamlit run src/app.py
Как построить приложение LLM, чтобы поболтать с PapersWithCode


