graph4nlp
v0.5.5-alpha

Graph4NLP เป็นห้องสมุดที่ใช้งานง่ายสำหรับการวิจัยและพัฒนาที่จุดตัดของ การเรียนรู้อย่างลึกซึ้งเกี่ยวกับกราฟ และ การประมวลผลภาษาธรรมชาติ (เช่น DLG4NLP) มันให้ทั้ง การใช้งานอย่างเต็มรูป แบบของแบบจำลองที่ทันสมัยสำหรับนักวิทยาศาสตร์ด้านข้อมูลและ อินเทอร์เฟซที่ยืดหยุ่น เพื่อสร้างแบบจำลองที่กำหนดเองสำหรับนักวิจัยและนักพัฒนาด้วยการสนับสนุนทั้งหมด สร้างขึ้นจากไลบรารีรันไทม์ที่ได้รับการปรับปรุงอย่างสูงรวมถึง DGL, Graph4NLP มีทั้งประสิทธิภาพสูงและการขยายที่ยอดเยี่ยม สถาปัตยกรรมของ Graph4NLP จะแสดงในรูปต่อไปนี้โดยที่กล่องที่มีเส้นประแสดงถึงคุณสมบัติที่อยู่ภายใต้การพัฒนา graph4nlp ประกอบด้วยสี่เลเยอร์ที่แตกต่างกัน: 1) เลเยอร์ข้อมูล, 2) เลเยอร์โมดูล, 3) เลเยอร์โมเดลและ 4) เลเยอร์แอปพลิเคชัน
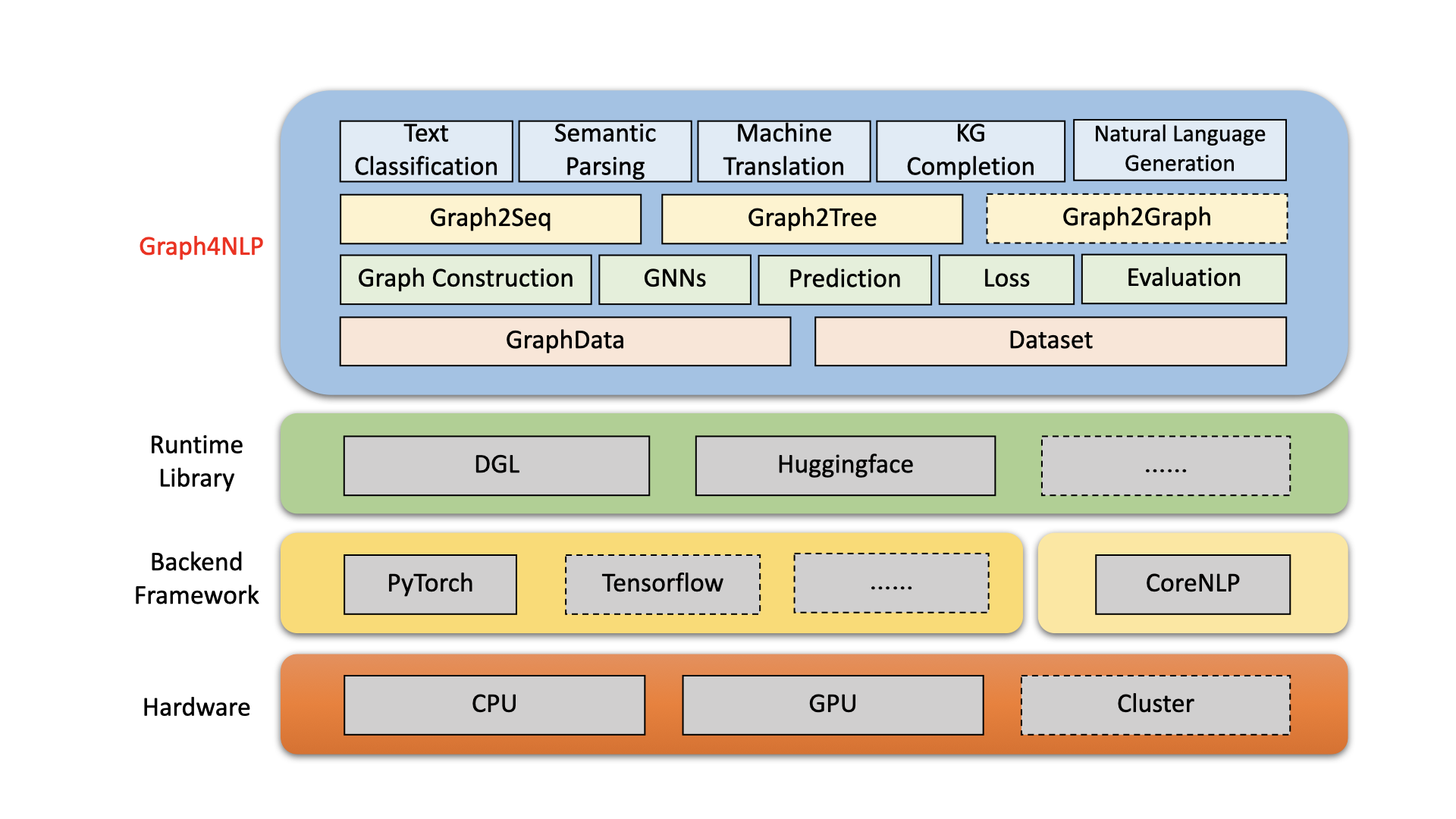
รูป : Graph4NLP สถาปัตยกรรมโดยรวม
01/20/2022: การเปิดตัว V0.5.5 ลองดู!
09/26/2021: การเปิดตัว V0.5.1 ลองดู!
09/01/2021: ยินดีต้อนรับไปเยี่ยมชม เว็บไซต์ DLG4NLP ของเรา (https://dlg4nlp.github.io/index.html) สำหรับแหล่งข้อมูลการเรียนรู้ที่หลากหลาย!
06/05/2021: การเปิดตัว V0.4.1
| ปล่อย | วันที่ | คุณสมบัติ |
|---|---|---|
| v0.5.5 | 2022-01-20 | - โมเดลสนับสนุน Predict API โดยการแนะนำฟังก์ชั่น wrapper - แนะนำสามฟังก์ชั่นการ inference_wrapper ใหม่: classifier_inference_wrapper, generator_inference_wrapper, generator_inference_wrapper_for_tree - เพิ่มตัวอย่างการอนุมานและการอนุมานในแต่ละแอปพลิเคชัน - แยกทอพอโลยีกราฟและกระบวนการฝังกราฟ - ต่ออายุฟังก์ชั่นการก่อสร้างกราฟทั้งหมด - Module graph_embedding แบ่งออกเป็น graph_embedding_initialization และ graph_embedding_learning - รวมพารามิเตอร์ในชุดข้อมูล เราลบพารามิเตอร์ที่คลุมเครือ graph_type และแนะนำ graph_name เพื่อระบุวิธีการก่อสร้างกราฟและ static_or_dynamic เพื่อระบุประเภทการก่อสร้างกราฟแบบคงที่หรือแบบไดนามิก- ใหม่: ชุดข้อมูลตอนนี้สามารถเลือกวิธีการเริ่มต้นโดยอัตโนมัติ (เช่น topology_builder ) โดยอัตโนมัติเพียงหนึ่งพารามิเตอร์ graph_name |
| v0.5.1 | 2021-09-26 | - ผ้าสำลีรหัส - สนับสนุนการทดสอบด้วยข้อมูลของผู้ใช้เอง - แก้ไขข้อผิดพลาด: ขนาดการฝังคำว่าเป็นรหัสที่ยากในเวอร์ชัน 0.4.1 ตอนนี้มันเท่ากับพารามิเตอร์ "Word_EMB_SIZE" - แก้ไขข้อผิดพลาด: build_vocab () เรียกว่าสองครั้งในเวอร์ชัน 0.4.1 - แก้ไขข้อผิดพลาด: สองไฟล์หลักของตัวอย่างกราฟความรู้ที่เสร็จสมบูรณ์ไม่ได้รับพารามิเตอร์เสริม "kg_graph" ใน ranking_and_hits () เมื่อกลับมาฝึกอบรมโมเดลต่อ - แก้ไขข้อผิดพลาด: เราได้แก้ไขข้อผิดพลาดเส้นทางการประมวลผลล่วงหน้าใน KGC ReadMe - แก้ไขข้อผิดพลาด: เราได้แก้ไขข้อผิดพลาดในการสร้างการฝังเมื่อตั้งค่า emb_strategy เป็น 'w2v' |
| v0.4.1 | 2021-06-05 | - สนับสนุนไปป์ไลน์ทั้งหมดของ graph4nlp - GraphData และชุดข้อมูลสนับสนุน |
Graph4NLP มีจุดมุ่งหมายเพื่อให้ใช้ GNNs ในงาน NLP ได้ง่ายอย่างไม่น่าเชื่อ (ตรวจสอบเอกสาร graph4nlp) นี่คือตัวอย่างของวิธีการใช้โมเดล graph2seq (ใช้กันอย่างแพร่หลายในการแปลของเครื่อง, การตอบคำถาม, การแยกวิเคราะห์ความหมายและงาน NLP อื่น ๆ ที่สามารถสรุปได้ว่าเป็นปัญหากราฟต่อลำดับและแสดงประสิทธิภาพที่เหนือกว่า)
นอกจากนี้เรายังนำเสนอ API รุ่นระดับสูงอื่น ๆ เช่นรุ่นกราฟสู่ต้นไม้ หากคุณมีความสนใจในปัญหาการวิจัยที่เกี่ยวข้องกับ DLG4NLP คุณสามารถใช้ห้องสมุดของเราและอ้างอิงการสำรวจ Graph4NLP ของเรา
from graph4nlp . pytorch . datasets . jobs import JobsDataset
from graph4nlp . pytorch . modules . graph_construction . dependency_graph_construction import DependencyBasedGraphConstruction
from graph4nlp . pytorch . modules . config import get_basic_args
from graph4nlp . pytorch . models . graph2seq import Graph2Seq
from graph4nlp . pytorch . modules . utils . config_utils import update_values , get_yaml_config
# build dataset
jobs_dataset = JobsDataset ( root_dir = 'graph4nlp/pytorch/test/dataset/jobs' ,
topology_builder = DependencyBasedGraphConstruction ,
topology_subdir = 'DependencyGraph' ) # You should run stanfordcorenlp at background
vocab_model = jobs_dataset . vocab_model
# build model
user_args = get_yaml_config ( "examples/pytorch/semantic_parsing/graph2seq/config/dependency_gcn_bi_sep_demo.yaml" )
args = get_basic_args ( graph_construction_name = "node_emb" , graph_embedding_name = "gat" , decoder_name = "stdrnn" )
update_values ( to_args = args , from_args_list = [ user_args ])
graph2seq = Graph2Seq . from_args ( args , vocab_model )
# calculation
batch_data = JobsDataset . collate_fn ( jobs_dataset . train [ 0 : 12 ])
scores = graph2seq ( batch_data [ "graph_data" ], batch_data [ "tgt_seq" ]) # [Batch_size, seq_len, Vocab_size] โฟลว์การคำนวณ graph4nlp ของเราแสดงดังต่อไปนี้

เรามีการรวบรวมแอปพลิเคชัน NLP ที่ครอบคลุมพร้อมตัวอย่างโดยละเอียดดังนี้:
สิ่งแวดล้อม: คบเพลิง 1.8, Ubuntu 16.04 กับ 2080Ti GPUS
| งาน | ชุดข้อมูล | รุ่น GNN | การก่อสร้างกราฟ | การประเมิน | ผลงาน |
|---|---|---|---|---|---|
| การจำแนกข้อความ | ทรีทต์ ถ่านหิน CNSST | แก๊ส | การพึ่งพาอาศัยกัน การเลือกตั้ง การพึ่งพาอาศัยกัน | ความแม่นยำ | 0.948 0.785 0.538 |
| การแยกวิเคราะห์ความหมาย | งาน | ปราชญ์ | การเลือกตั้ง | ความแม่นยำในการดำเนินการ | 0.936 |
| การสร้างคำถาม | ทีม | ggnn | การพึ่งพาอาศัยกัน | bleu-4 | 0.15175 |
| การแปลเครื่องจักร | iwslt14 | GCN | พลวัต | bleu-4 | 0.3212 |
| การสรุป | CNN (30k) | GCN | การพึ่งพาอาศัยกัน | rouge-1 | 26.4 |
| กราฟความรู้เสร็จสมบูรณ์ | เครือญาติ | GCN | การพึ่งพาอาศัยกัน | MRR | 82.4 |
| ปัญหาคำคณิตศาสตร์ | มวอ | ปราชญ์ | พลวัต | ความแม่นยำในการแก้ปัญหา | 76.4 |
ปัจจุบันผู้ใช้สามารถติดตั้ง Graph4NLP ผ่าน PIP หรือ ซอร์สโค้ด graph4nlp รองรับ OSE ต่อไปนี้:
เราให้บริการล้อ PIP สำหรับการรวมกันของ OS/Pytorch/Cuda ที่สำคัญทั้งหมด โปรดทราบว่าเราขอแนะนำให้ผู้ใช้ Windows อ้างถึง Installation via source code เนื่องจากความเข้ากันได้
โปรดทราบว่า >=1.6.0 ก็โอเค
$ python -c " import torch; print(torch.__version__) "
>>> 1.6.0$ python -c " import torch; print(torch.version.cuda) "
>>> 10.2 torchtext เป็นสิ่งจำเป็นเนื่องจาก graph4nlp ต้องอาศัยมันเพื่อใช้งาน embeddings โปรดใส่ใจกับข้อกำหนดของ Pytorch ก่อนที่จะติดตั้ง torchtext ด้วยสคริปต์ต่อไปนี้! สำหรับการจับคู่เวอร์ชันโดยละเอียดโปรดดูที่นี่
pip install torchtext # >=0.7.0 pip install graph4nlp ${CUDA} โดยที่ ${CUDA} ควรถูกแทนที่ด้วยรุ่น cuda เฉพาะ ( none (เวอร์ชัน CPU), "-cu92" , "-cu101" , "-cu102" , "-cu110" ) ตารางต่อไปนี้แสดงบรรทัดคำสั่งคอนกรีต สำหรับผู้ใช้ CUDA 11.1 โปรดดู Installation via source code
| แพลตฟอร์ม | สั่งการ |
|---|---|
| ซีพียู | pip install graph4nlp |
| Cuda 9.2 | pip install graph4nlp-cu92 |
| Cuda 10.1 | pip install graph4nlp-cu101 |
| Cuda 10.2 | pip install graph4nlp-cu102 |
| Cuda 11.0 | pip install graph4nlp-cu110 |
โปรดทราบว่า >=1.6.0 ก็โอเค
$ python -c " import torch; print(torch.__version__) "
>>> 1.6.0$ python -c " import torch; print(torch.version.cuda) "
>>> 10.2 torchtext เป็นสิ่งจำเป็นเนื่องจาก graph4nlp ต้องอาศัยมันเพื่อใช้งาน embeddings โปรดใส่ใจกับข้อกำหนดของ Pytorch ก่อนที่จะติดตั้ง torchtext ด้วยสคริปต์ต่อไปนี้! สำหรับการจับคู่เวอร์ชันโดยละเอียดโปรดดูที่นี่
pip install torchtext # >=0.7.0 Graph4NLP จาก gitHub: git clone https://github.com/graph4ai/graph4nlp.git
cd graph4nlp จากนั้นเรียกใช้ ./configure (หรือ ./configure.bat หากคุณใช้ Windows 10) เพื่อกำหนดค่าการติดตั้งของคุณ โปรแกรมการกำหนดค่าจะขอให้คุณระบุรุ่น CUDA ของคุณ หากคุณไม่มี GPU โปรดพิมพ์ 'CPU'
./configureในที่สุดติดตั้งแพ็คเกจ:
python setup.py installเราแสดง hyperparameters บางส่วนที่มักจะถูกปรับที่นี่
หากคุณต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการใช้การเรียนรู้อย่างลึกซึ้งเกี่ยวกับเทคนิคกราฟกับงาน NLP ยินดีต้อนรับไปเยี่ยมชมเว็บไซต์ DLG4NLP ของเรา (https://dlg4nlp.github.io/index.html) สำหรับแหล่งเรียนรู้ต่างๆ! คุณสามารถอ้างถึงรายงานสำรวจของเราซึ่งให้ภาพรวมของทิศทางการวิจัยที่มีอยู่นี้ หากคุณต้องการการอ้างอิงอย่างละเอียดถึงห้องสมุดของเราโปรดดูเอกสารของเรา
โปรดแจ้งให้เราทราบหากคุณพบข้อผิดพลาดหรือมีคำแนะนำใด ๆ โดยการยื่นปัญหา
เรายินดีต้อนรับการมีส่วนร่วมทั้งหมดตั้งแต่การแก้ไขข้อผิดพลาดไปจนถึงคุณสมบัติใหม่และส่วนขยาย
เราคาดหวังว่าการมีส่วนร่วมทั้งหมดที่กล่าวถึงในการติดตามปัญหาและผ่าน PRS
หากคุณพบว่ารหัสนี้มีประโยชน์โปรดพิจารณาอ้างถึงเอกสารต่อไปนี้
@article{wu2021graph,
title={Graph Neural Networks for Natural Language Processing: A Survey},
author={Lingfei Wu and Yu Chen and Kai Shen and Xiaojie Guo and Hanning Gao and Shucheng Li and Jian Pei and Bo Long},
journal={arXiv preprint arXiv:2106.06090},
year={2021}
}
@inproceedings{chen2020iterative,
title={Iterative Deep Graph Learning for Graph Neural Networks: Better and Robust Node Embeddings},
author={Chen, Yu and Wu, Lingfei and Zaki, Mohammed J},
booktitle={Proceedings of the 34th Conference on Neural Information Processing Systems},
month={Dec. 6-12,},
year={2020}
}
@inproceedings{chen2020reinforcement,
author = {Chen, Yu and Wu, Lingfei and Zaki, Mohammed J.},
title = {Reinforcement Learning Based Graph-to-Sequence Model for Natural Question Generation},
booktitle = {Proceedings of the 8th International Conference on Learning Representations},
month = {Apr. 26-30,},
year = {2020}
}
@article{xu2018graph2seq,
title={Graph2seq: Graph to sequence learning with attention-based neural networks},
author={Xu, Kun and Wu, Lingfei and Wang, Zhiguo and Feng, Yansong and Witbrock, Michael and Sheinin, Vadim},
journal={arXiv preprint arXiv:1804.00823},
year={2018}
}
@inproceedings{li-etal-2020-graph-tree,
title = {Graph-to-Tree Neural Networks for Learning Structured Input-Output Translation with Applications to Semantic Parsing and Math Word Problem},
author = {Li, Shucheng and
Wu, Lingfei and
Feng, Shiwei and
Xu, Fangli and
Xu, Fengyuan and
Zhong, Sheng},
booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2020},
month = {Nov},
year = {2020}
}
@inproceedings{huang-etal-2020-knowledge,
title = {Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward},
author = {Huang, Luyang and
Wu, Lingfei and
Wang, Lu},
booktitle = {Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics},
month = {Jul},
year = {2020},
pages = {5094--5107}
}
@inproceedings{wu-etal-2018-word,
title = {Word Mover{'}s Embedding: From {W}ord2{V}ec to Document Embedding},
author = {Wu, Lingfei and
Yen, Ian En-Hsu and
Xu, Kun and
Xu, Fangli and
Balakrishnan, Avinash and
Chen, Pin-Yu and
Ravikumar, Pradeep and
Witbrock, Michael J.},
booktitle = {Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing},
pages = {4524--4534},
year = {2018},
}
@inproceedings{chen2020graphflow,
author = {Yu Chen and
Lingfei Wu and
Mohammed J. Zaki},
title = {GraphFlow: Exploiting Conversation Flow with Graph Neural Networks
for Conversational Machine Comprehension},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI} 2020},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {1230--1236},
year = {2020}
}
@inproceedings{shen2020hierarchical,
title={Hierarchical Attention Based Spatial-Temporal Graph-to-Sequence Learning for Grounded Video Description},
author={Shen, Kai and Wu, Lingfei and Xu, Fangli and Tang, Siliang and Xiao, Jun and Zhuang, Yueting},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI} 2020},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {941--947},
year = {2020}
}
@inproceedings{ijcai2020-419,
title = {RDF-to-Text Generation with Graph-augmented Structural Neural Encoders},
author = {Gao, Hanning and Wu, Lingfei and Hu, Po and Xu, Fangli},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI-20}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {3030--3036},
year = {2020}
}
ทีม Graph4ai: Lingfei Wu (หัวหน้าทีม), Yu Chen, Kai Shen, Xiaojie Guo, Hanning Gao, Shucheng Li, Saizhuo Wang, Xiao Liu และ Jing Hu เรามีความกระตือรือร้นในการพัฒนาห้องสมุดโอเพนซอร์ซที่มีประโยชน์ซึ่งมีจุดมุ่งหมายเพื่อส่งเสริมการใช้งานการเรียนรู้อย่างลึกซึ้งที่หลากหลายเกี่ยวกับเทคนิคกราฟสำหรับการประมวลผลภาษาธรรมชาติ ทีมงานของเราประกอบด้วยนักวิทยาศาสตร์การวิจัยนักวิทยาศาสตร์ข้อมูลประยุกต์และนักศึกษาระดับบัณฑิตศึกษาจากกลุ่มอุตสาหกรรมและวิชาการที่หลากหลายรวมถึง Pinterest (Lingfei Wu), มหาวิทยาลัยเจ้อเจียง (Kai Shen), Facebook AI (Yu Chen), IBM TJ Watson Research Center (Xiaojie Guo) (Saizhuo Wang)
หากคุณมีคำถามทางเทคนิคใด ๆ โปรดส่งปัญหาใหม่
หากคุณมีคำถามอื่น ๆ โปรดติดต่อเรา: Lingfei Wu [[email protected]] และ Xiaojie Guo [[email protected]]
graph4nlp ใช้ Apache License 2.0


