graph4nlp
v0.5.5-alpha

Graph4NLP est une bibliothèque facile à utiliser pour la R&D à l'intersection de l'apprentissage en profondeur sur les graphiques et le traitement du langage naturel (c'est-à-dire DLG4NLP). Il fournit à la fois des implémentations complètes de modèles de pointe pour les scientifiques des données et également des interfaces flexibles pour construire des modèles personnalisés pour les chercheurs et les développeurs avec un support entièrement plipineux. Construit sur des bibliothèques d'exécution hautement optimisées, y compris DGL, Graph4NLP a à la fois une efficacité de fonctionnement élevée et une grande extensibilité. L'architecture de Graph4NLP est illustrée à la figure suivante, où les boîtes avec des lignes en pointillés représentent les fonctionnalités en cours de développement. Graph4NLP se compose de quatre couches différentes: 1) couche de données, 2) couche de module, 3) couche de modèle et 4) couche d'application.
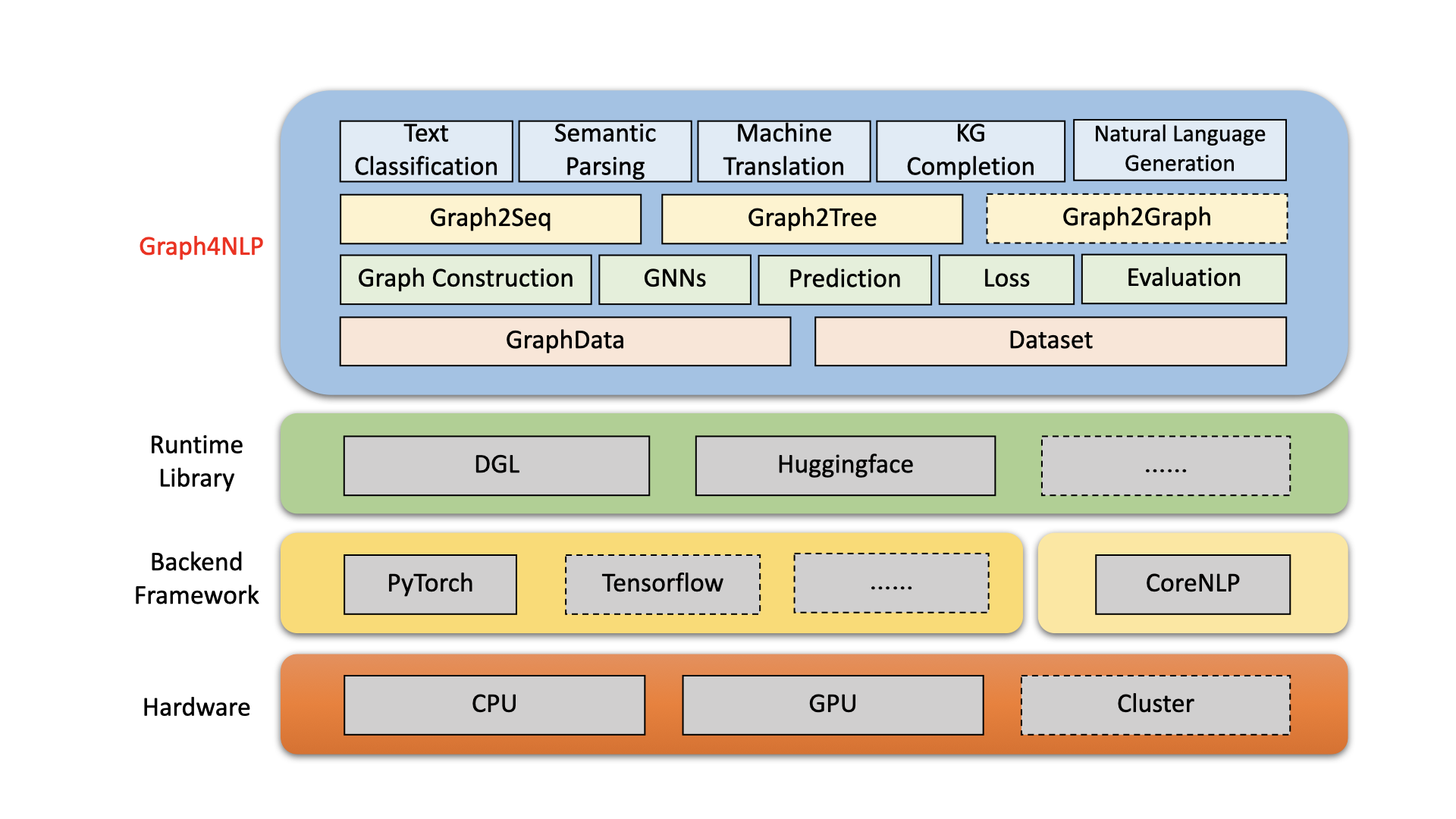
Figure : Architecture globale Graph4NLP
20/01/2022: la version V0.5.5 . Essayez-le!
26/09/2021: la version V0.5.1 . Essayez-le!
09/01/2021: Bienvenue à visiter notre site Web DLG4NLP (https://dlg4nlp.github.io/index.html) pour diverses ressources d'apprentissage!
06/05/2021: la version V0.4.1 .
| Sorties | Date | Caractéristiques |
|---|---|---|
| v0.5.5 | 2022-01-20 | - Support Model.predict API en introduisant des fonctions de wrapper. - Introduisez trois nouvelles fonctions Inference_Wrapper: classifier_inference_wrapper, générateur_inference_wrapper, générateur_inference_wrapper_for_tree. - Ajoutez les exemples d'inférence et d'inférence_advance dans chaque application. - Séparez la topologie du graphique et le processus d'intégration du graphique. - Renouveler toutes les fonctions de construction du graphique. - Module Graph_embedding est divisé en graph_embedding_initialization et graph_embedding_learning. - Unifiez les paramètres dans l'ensemble de données. Nous supprimons le paramètre ambigu graph_type et introduisons graph_name pour indiquer la méthode de construction du graphique et static_or_dynamic pour indiquer le type de construction de graphe statique ou dynamique.- Nouveau: l'ensemble de données peut désormais choisir automatiquement les méthodes par défaut (par exemple, topology_builder ) par un seul paramètre graph_name . |
| v0.5.1 | 2021-09-26 | - Lint les codes - Prise en charge des tests avec les propres données des utilisateurs - Correction du bogue: le mot d'intégration de la taille a été codé dur dans la version 0.4.1. Maintenant, il est égal au paramètre "word_emb_size". - Correction du bug: le build_vocab () est appelé deux fois dans la version 0.4.1. - Correction du bogue: les deux fichiers principaux de l'exemple d'achèvement du graphique de connaissances ont manqué le paramètre facultatif "kg_graph" dans le classement_and_hits () lors de la reprise de la formation du modèle. - Correction du bogue: nous avons corrigé l'erreur de chemin de prétraitement dans KGC Readme. - Correction du bogue: nous avons corrigé le bug de construction de construction lors de la définition de l'emb_strategy sur «W2V». |
| v0.4.1 | 2021-06-05 | - Soutenez l'ensemble du pipeline de Graph4NLP - GraphData et prise en charge de l'ensemble de données |
Graph4NLP vise à rendre les GNN incroyablement faciles à utiliser dans les tâches NLP (consultez la documentation Graph4NLP). Voici un exemple de la façon d'utiliser le modèle Graph2SEQ (largement utilisé dans la traduction automatique, la réponse aux questions, l'analyse sémantique et diverses autres tâches NLP qui peuvent être résumées en tant que problème graphique à séquence et ont montré des performances supérieures).
Nous proposons également d'autres API de modèles de haut niveau tels que les modèles de graphiques à arbre. Si vous êtes intéressé par les problèmes de recherche liés à DLG4NLP, vous êtes les bienvenus pour utiliser notre bibliothèque et vous référer à notre enquête Graph4NLP.
from graph4nlp . pytorch . datasets . jobs import JobsDataset
from graph4nlp . pytorch . modules . graph_construction . dependency_graph_construction import DependencyBasedGraphConstruction
from graph4nlp . pytorch . modules . config import get_basic_args
from graph4nlp . pytorch . models . graph2seq import Graph2Seq
from graph4nlp . pytorch . modules . utils . config_utils import update_values , get_yaml_config
# build dataset
jobs_dataset = JobsDataset ( root_dir = 'graph4nlp/pytorch/test/dataset/jobs' ,
topology_builder = DependencyBasedGraphConstruction ,
topology_subdir = 'DependencyGraph' ) # You should run stanfordcorenlp at background
vocab_model = jobs_dataset . vocab_model
# build model
user_args = get_yaml_config ( "examples/pytorch/semantic_parsing/graph2seq/config/dependency_gcn_bi_sep_demo.yaml" )
args = get_basic_args ( graph_construction_name = "node_emb" , graph_embedding_name = "gat" , decoder_name = "stdrnn" )
update_values ( to_args = args , from_args_list = [ user_args ])
graph2seq = Graph2Seq . from_args ( args , vocab_model )
# calculation
batch_data = JobsDataset . collate_fn ( jobs_dataset . train [ 0 : 12 ])
scores = graph2seq ( batch_data [ "graph_data" ], batch_data [ "tgt_seq" ]) # [Batch_size, seq_len, Vocab_size] Notre flux informatique Graph4NLP est illustré comme ci-dessous.

Nous fournissons une collection complète d'applications PNL, ainsi que des exemples détaillés comme suit:
Environnement: Torch 1.8, Ubuntu 16.04 avec 2080ti GPUS
| Tâche | Ensemble de données | Modèle GNN | Construction de graphiques | Évaluation | Performance |
|---|---|---|---|---|---|
| Classification de texte | Randonnée Cairline CNSST | FLINGUE | Dépendance Circonscription électorale Dépendance | Précision | 0,948 0,785 0,538 |
| Analyse sémantique | Emplois | SAGE | Circonscription électorale | Précision d'exécution | 0,936 |
| Génération de questions | Équipe | GGNN | Dépendance | Bleu-4 | 0,15175 |
| Traduction automatique | Iwslt14 | GCN | Dynamique | Bleu-4 | 0,3212 |
| Récapitulation | CNN (30K) | GCN | Dépendance | Rouge-1 | 26.4 |
| Achèvement du graphique des connaissances | Parenté | GCN | Dépendance | MRR | 82.4 |
| Problème de mot mathématique | Tronçonneurs | SAGE | Dynamique | Précision de la solution | 76.4 |
Actuellement, les utilisateurs peuvent installer Graph4NLP via PIP ou Code source . Graph4NLP prend en charge les OSO suivantes:
Nous fournissons des roues PIP pour toutes les principales combinaisons OS / Pytorch / Cuda. Notez que nous recommandons vivement que les utilisateurs Windows se réfèrent à Installation via source code en raison de la compatibilité.
Notez que >=1.6.0 est OK.
$ python -c " import torch; print(torch.__version__) "
>>> 1.6.0$ python -c " import torch; print(torch.version.cuda) "
>>> 10.2 torchtext est nécessaire car Graph4NLP s'appuie sur celui-ci pour implémenter des intégres. Veuillez faire attention aux exigences de Pytorch avant d'installer torchtext avec le script suivant! Pour une version détaillée de la version, veuillez vous référer ici.
pip install torchtext # >=0.7.0 pip install graph4nlp ${CUDA} où ${CUDA} doit être remplacé par la version CUDA spécifique ( none (version CPU), "-cu92" , "-cu101" , "-cu102" , "-cu110" ). Le tableau suivant montre les lignes de commande en béton. Pour les utilisateurs de CUDA 11.1, veuillez vous référer à Installation via source code .
| Plate-forme | Commande |
|---|---|
| Processeur | pip install graph4nlp |
| Cuda 9.2 | pip install graph4nlp-cu92 |
| CUDA 10.1 | pip install graph4nlp-cu101 |
| Cuda 10.2 | pip install graph4nlp-cu102 |
| Cuda 11.0 | pip install graph4nlp-cu110 |
Notez que >=1.6.0 est OK.
$ python -c " import torch; print(torch.__version__) "
>>> 1.6.0$ python -c " import torch; print(torch.version.cuda) "
>>> 10.2 torchtext est nécessaire car Graph4NLP s'appuie sur celui-ci pour implémenter des intégres. Veuillez faire attention aux exigences de Pytorch avant d'installer torchtext avec le script suivant! Pour une version détaillée de la version, veuillez vous référer ici.
pip install torchtext # >=0.7.0 Graph4NLP depuis GitHub: git clone https://github.com/graph4ai/graph4nlp.git
cd graph4nlp Ensuite, exécutez ./configure (ou ./configure.bat si vous utilisez Windows 10) pour configurer votre installation. Le programme de configuration vous demandera de spécifier votre version CUDA. Si vous n'avez pas de GPU, veuillez taper «CPU».
./configureEnfin, installez le package:
python setup.py installNous montrons certains des hyperparamètres qui sont souvent réglés ici.
Si vous souhaitez en savoir plus sur l'application de l'apprentissage en profondeur sur les techniques de graphiques aux tâches NLP, bienvenue pour visiter notre site Web DLG4NLP (https://dlg4nlp.github.io/index.html) pour diverses ressources d'apprentissage! Vous pouvez vous référer à notre document d'enquête qui donne un aperçu de cette direction de recherche existante. Si vous voulez une référence détaillée à notre bibliothèque, veuillez vous référer à nos documents.
Veuillez nous faire savoir si vous rencontrez un bogue ou si vous avez des suggestions en déposant un problème.
Nous accueillons toutes les contributions des corrections de bogues aux nouvelles fonctionnalités et extensions.
Nous nous attendons à toutes les contributions discutées dans le tracker du numéro et en passant par PRS.
Si vous avez trouvé ce code utile, veuillez envisager de citer les articles suivants.
@article{wu2021graph,
title={Graph Neural Networks for Natural Language Processing: A Survey},
author={Lingfei Wu and Yu Chen and Kai Shen and Xiaojie Guo and Hanning Gao and Shucheng Li and Jian Pei and Bo Long},
journal={arXiv preprint arXiv:2106.06090},
year={2021}
}
@inproceedings{chen2020iterative,
title={Iterative Deep Graph Learning for Graph Neural Networks: Better and Robust Node Embeddings},
author={Chen, Yu and Wu, Lingfei and Zaki, Mohammed J},
booktitle={Proceedings of the 34th Conference on Neural Information Processing Systems},
month={Dec. 6-12,},
year={2020}
}
@inproceedings{chen2020reinforcement,
author = {Chen, Yu and Wu, Lingfei and Zaki, Mohammed J.},
title = {Reinforcement Learning Based Graph-to-Sequence Model for Natural Question Generation},
booktitle = {Proceedings of the 8th International Conference on Learning Representations},
month = {Apr. 26-30,},
year = {2020}
}
@article{xu2018graph2seq,
title={Graph2seq: Graph to sequence learning with attention-based neural networks},
author={Xu, Kun and Wu, Lingfei and Wang, Zhiguo and Feng, Yansong and Witbrock, Michael and Sheinin, Vadim},
journal={arXiv preprint arXiv:1804.00823},
year={2018}
}
@inproceedings{li-etal-2020-graph-tree,
title = {Graph-to-Tree Neural Networks for Learning Structured Input-Output Translation with Applications to Semantic Parsing and Math Word Problem},
author = {Li, Shucheng and
Wu, Lingfei and
Feng, Shiwei and
Xu, Fangli and
Xu, Fengyuan and
Zhong, Sheng},
booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2020},
month = {Nov},
year = {2020}
}
@inproceedings{huang-etal-2020-knowledge,
title = {Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward},
author = {Huang, Luyang and
Wu, Lingfei and
Wang, Lu},
booktitle = {Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics},
month = {Jul},
year = {2020},
pages = {5094--5107}
}
@inproceedings{wu-etal-2018-word,
title = {Word Mover{'}s Embedding: From {W}ord2{V}ec to Document Embedding},
author = {Wu, Lingfei and
Yen, Ian En-Hsu and
Xu, Kun and
Xu, Fangli and
Balakrishnan, Avinash and
Chen, Pin-Yu and
Ravikumar, Pradeep and
Witbrock, Michael J.},
booktitle = {Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing},
pages = {4524--4534},
year = {2018},
}
@inproceedings{chen2020graphflow,
author = {Yu Chen and
Lingfei Wu and
Mohammed J. Zaki},
title = {GraphFlow: Exploiting Conversation Flow with Graph Neural Networks
for Conversational Machine Comprehension},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI} 2020},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {1230--1236},
year = {2020}
}
@inproceedings{shen2020hierarchical,
title={Hierarchical Attention Based Spatial-Temporal Graph-to-Sequence Learning for Grounded Video Description},
author={Shen, Kai and Wu, Lingfei and Xu, Fangli and Tang, Siliang and Xiao, Jun and Zhuang, Yueting},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI} 2020},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {941--947},
year = {2020}
}
@inproceedings{ijcai2020-419,
title = {RDF-to-Text Generation with Graph-augmented Structural Neural Encoders},
author = {Gao, Hanning and Wu, Lingfei and Hu, Po and Xu, Fangli},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI-20}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {3030--3036},
year = {2020}
}
Équipe Graph4ai: Lingfei Wu (chef d'équipe), Yu Chen, Kai Shen, Xiaojie Guo, Hanning Gao, Shucheng Li, Saizhuo Wang, Xiao Liu et Jing Hu. Nous sommes passionnés par le développement de bibliothèques open source utiles qui visent à promouvoir l'utilisation facile de diverses techniques d'apprentissage en profondeur sur les graphiques pour le traitement du langage naturel. Notre équipe est composée de chercheurs, de scientifiques appliqués aux données et d'étudiants diplômés de divers groupes industriels et universitaires, notamment Pinterest (Lingfei Wu), Université du Zhejiang (Kai Shen), Facebook AI (Yu Chen), IBM TJ Watson Research Center (Xiaojie Guo), Tongji University (Hanning Gao), Nanjing University (Shucheng li), SAUSHY Wang).
Si vous avez des questions techniques, veuillez soumettre de nouveaux problèmes.
Si vous avez d'autres questions, veuillez nous contacter: Lingfei wu [[email protected]] et xiaojie guo [[email protected]] .
Graph4NLP utilise Apache License 2.0.


