graph4nlp
v0.5.5-alpha

Graph4NLP는 그래프 및 자연어 처리 (예 : DLG4NLP) 에 대한 딥 러닝 의 교차점에서 R & D를위한 사용하기 쉬운 라이브러리입니다. 데이터 과학자를위한 최첨단 모델의 전체 구현 과 유연한 인터페이스 를 제공하여 전체 파이프 라인 지원을받는 연구원 및 개발자를위한 맞춤형 모델을 구축 할 수 있습니다. DGL을 포함한 고도로 최적화 된 런타임 라이브러리에 구축 된 Graph4NLP는 높은 러닝 효율과 확장 성을 모두 갖추고 있습니다. Graph4NLP 의 아키텍처는 다음 그림에 표시되며, 선이있는 상자는 개발중인 기능을 나타냅니다. Graph4NLP는 4 개의 다른 계층으로 구성됩니다. 1) 데이터 계층, 2) 모듈 계층, 3) 모델 레이어 및 4) 응용 프로그램 계층.
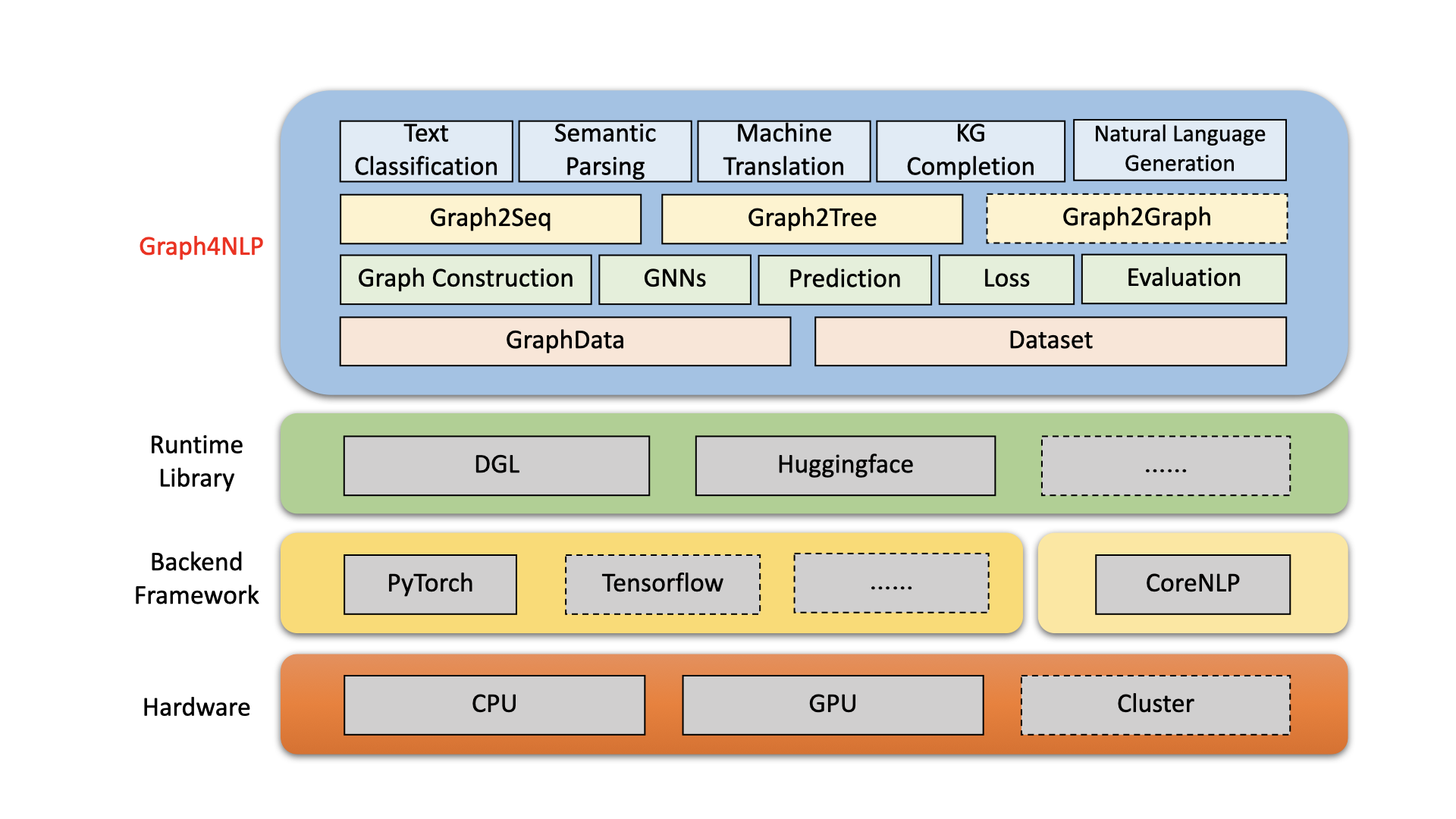
그림 : Graph4NLP 전체 아키텍처
01/20/2022 : V0.5.5 릴리스 . 시도해보십시오!
09/26/2021 : V0.5.1 릴리스 . 시도해보십시오!
09/01/2021 : 다양한 학습 리소스를 보려면 DLG4NLP 웹 사이트 (https://dlg4nlp.github.io/index.html)를 방문하십시오!
06/05/2021 : V0.4.1 릴리스 .
| 릴리스 | 날짜 | 특징 |
|---|---|---|
| v0.5.5 | 2022-01-20 | -Upport Model.Predict API 래퍼 기능을 도입하여. - 세 가지 새로운 inference_wrapper 함수를 소개합니다. classifier_inference_wrapper, generator_inference_wrapper, generator_inference_wrapper_for_tree. - 각 응용 프로그램에 추론 및 inference_advance 예제를 추가하십시오. - 그래프 토폴로지 및 그래프 임베딩 프로세스를 분리하십시오. - 모든 그래프 구성 기능을 갱신하십시오. - 모듈 Graph_embedding은 Graph_embedding_initialization 및 Graph_embedding_Learning으로 나뉩니다. - 데이터 세트에서 매개 변수를 통합하십시오. 모호한 매개 변수 graph_type 제거하고 graph_name 소개하여 그래프 구성 방법과 static_or_dynamic 표시하여 정적 또는 동적 그래프 구성 유형을 나타냅니다.- 새로운 : 데이터 세트는 이제 하나의 매개 변수 graph_name 만으로 기본 메소드 (예 : topology_builder )를 자동으로 선택할 수 있습니다. |
| v0.5.1 | 2021-09-26 | - 코드에 보풀을 뿌립니다 - 사용자 자체 데이터로 테스트를 지원합니다 - 버그 수정 : 단어 임베딩 크기는 0.4.1 버전으로 하드 코딩되었습니다. 이제 "word_emb_size"매개 변수와 같습니다. - 버그 수정 : build_vocab ()는 0.4.1 버전에서 두 번 호출됩니다. - 버그 수정 : 지식 그래프 완성의 두 가지 주요 파일 예제는 모델을 재개 할 때 ranking_and_hits ()의 선택적 매개 변수 "kg_graph"를 놓쳤다. - 버그 수정 : KGC readme에서 전처리 경로 오류를 수정했습니다. - 버그 수정 : EMB_Strategy를 'W2V'로 설정할 때 고정 임베딩 구조 버그가 있습니다. |
| v0.4.1 | 2021-06-05 | - Graph4NLP의 전체 파이프 라인을 지원합니다 -GraphData 및 데이터 세트 지원 |
Graph4NLP는 NLP 작업에서 GNNS를 사용하기가 매우 쉽게 만드는 것을 목표로합니다 (Graph4NLP 문서를 확인하십시오). 다음은 Graph2Seq 모델을 사용하는 방법 (기계 번역, 질문 응답, 의미 론적 구문 분석 및 그래프-시퀀스 문제로 추상화 될 수 있고 우수한 성능을 보여줄 수있는 다양한 NLP 작업에 널리 사용되는 방법에 대한 예입니다).
또한 그래프 투 트리 모델과 같은 다른 고급 모델 API도 제공합니다. DLG4NLP 관련 연구 문제에 관심이 있다면 라이브러리를 사용하고 Graph4NLP 설문 조사를 참조하십시오.
from graph4nlp . pytorch . datasets . jobs import JobsDataset
from graph4nlp . pytorch . modules . graph_construction . dependency_graph_construction import DependencyBasedGraphConstruction
from graph4nlp . pytorch . modules . config import get_basic_args
from graph4nlp . pytorch . models . graph2seq import Graph2Seq
from graph4nlp . pytorch . modules . utils . config_utils import update_values , get_yaml_config
# build dataset
jobs_dataset = JobsDataset ( root_dir = 'graph4nlp/pytorch/test/dataset/jobs' ,
topology_builder = DependencyBasedGraphConstruction ,
topology_subdir = 'DependencyGraph' ) # You should run stanfordcorenlp at background
vocab_model = jobs_dataset . vocab_model
# build model
user_args = get_yaml_config ( "examples/pytorch/semantic_parsing/graph2seq/config/dependency_gcn_bi_sep_demo.yaml" )
args = get_basic_args ( graph_construction_name = "node_emb" , graph_embedding_name = "gat" , decoder_name = "stdrnn" )
update_values ( to_args = args , from_args_list = [ user_args ])
graph2seq = Graph2Seq . from_args ( args , vocab_model )
# calculation
batch_data = JobsDataset . collate_fn ( jobs_dataset . train [ 0 : 12 ])
scores = graph2seq ( batch_data [ "graph_data" ], batch_data [ "tgt_seq" ]) # [Batch_size, seq_len, Vocab_size] Graph4NLP 컴퓨팅 흐름은 다음과 같이 표시됩니다.

우리는 다음과 같이 자세한 예제와 함께 포괄적 인 NLP 응용 프로그램 모음을 제공합니다.
환경 : Torch 1.8, Ubuntu 16.04가 2080ti gpus
| 일 | 데이터 세트 | GNN 모델 | 그래프 구성 | 평가 | 성능 |
|---|---|---|---|---|---|
| 텍스트 분류 | 트렉 케어 라인 CNSST | 개트 | 의존 후원자 의존 | 정확성 | 0.948 0.785 0.538 |
| 시맨틱 파싱 | 일자리 | 세이지 | 후원자 | 실행 정확도 | 0.936 |
| 질문 세대 | 분대 | ggnn | 의존 | 블루 -4 | 0.15175 |
| 기계 번역 | IWSLT14 | GCN | 동적 | 블루 -4 | 0.3212 |
| 요약 | CNN (30K) | GCN | 의존 | 루즈 -1 | 26.4 |
| 지식 그래프 완성 | 혈연 관계 | GCN | 의존 | MRR | 82.4 |
| 수학 단어 문제 | mawps | 세이지 | 동적 | 솔루션 정확도 | 76.4 |
현재 사용자는 PIP 또는 소스 코드를 통해 Graph4NLP를 설치할 수 있습니다. Graph4NLP는 다음 OS를 지원합니다.
우리는 모든 주요 OS/Pytorch/Cuda 조합에 PIP 휠을 제공합니다. Windows 사용자는 호환성으로 인해 Installation via source code 참조하는 것이 좋습니다.
>=1.6.0 은 괜찮습니다.
$ python -c " import torch; print(torch.__version__) "
>>> 1.6.0$ python -c " import torch; print(torch.version.cuda) "
>>> 10.2 THRAGR4NLP는 임베딩을 구현하기 위해 IT에 의존하기 때문에 torchtext 필요합니다. 다음 스크립트로 torchtext 설치하기 전에 Pytorch 요구 사항에주의를 기울이십시오! 자세한 버전 매칭은 여기를 참조하십시오.
pip install torchtext # >=0.7.0 pip install graph4nlp ${CUDA} 여기서 ${CUDA} 특정 CUDA 버전 ( none (CPU 버전), "-cu92" , "-cu101" , "-cu102" , "-cu110" 으로 대체되어야합니다. 다음 표는 콘크리트 명령 라인을 보여줍니다. CUDA 11.1 사용자의 경우 Installation via source code 참조하십시오.
| 플랫폼 | 명령 |
|---|---|
| CPU | pip install graph4nlp |
| CUDA 9.2 | pip install graph4nlp-cu92 |
| CUDA 10.1 | pip install graph4nlp-cu101 |
| CUDA 10.2 | pip install graph4nlp-cu102 |
| CUDA 11.0 | pip install graph4nlp-cu110 |
>=1.6.0 은 괜찮습니다.
$ python -c " import torch; print(torch.__version__) "
>>> 1.6.0$ python -c " import torch; print(torch.version.cuda) "
>>> 10.2 THRAGR4NLP는 임베딩을 구현하기 위해 IT에 의존하기 때문에 torchtext 필요합니다. 다음 스크립트로 torchtext 설치하기 전에 Pytorch 요구 사항에주의를 기울이십시오! 자세한 버전 매칭은 여기를 참조하십시오.
pip install torchtext # >=0.7.0 Graph4NLP 의 소스 코드를 다운로드하십시오. git clone https://github.com/graph4ai/graph4nlp.git
cd graph4nlp 그런 다음 ./configure (또는 ./configure.bat Windows 10을 사용하는 경우)를 실행하여 설치를 구성하십시오. 구성 프로그램은 CUDA 버전을 지정하도록 요청합니다. GPU가없는 경우 'CPU'를 입력하십시오.
./configure마지막으로 패키지를 설치하십시오.
python setup.py install우리는 종종 여기에 조정되는 과복 미터의 일부를 보여줍니다.
NLP 작업에 그래프 기술에 딥 러닝을 적용하는 것에 대해 자세히 알아 보려면 다양한 학습 리소스를 위해 DLG4NLP 웹 사이트 (https://dlg4nlp.github.io/index.html)를 방문하십시오! 이 기존 연구 방향에 대한 개요를 제공하는 설문 조사 논문을 참조 할 수 있습니다. 우리 도서관에 대한 자세한 내용을 원하시면 문서를 참조하십시오.
버그가 발생하거나 문제를 제기하여 제안이 있으면 알려주십시오.
우리는 버그 수정에서 새로운 기능 및 확장에 이르기까지 모든 기여를 환영합니다.
우리는 이슈 트래커에서 논의 된 모든 기여와 PRS를 통과 할 것으로 예상합니다.
이 코드가 유용하다고 생각되면 다음 논문을 인용하는 것을 고려하십시오.
@article{wu2021graph,
title={Graph Neural Networks for Natural Language Processing: A Survey},
author={Lingfei Wu and Yu Chen and Kai Shen and Xiaojie Guo and Hanning Gao and Shucheng Li and Jian Pei and Bo Long},
journal={arXiv preprint arXiv:2106.06090},
year={2021}
}
@inproceedings{chen2020iterative,
title={Iterative Deep Graph Learning for Graph Neural Networks: Better and Robust Node Embeddings},
author={Chen, Yu and Wu, Lingfei and Zaki, Mohammed J},
booktitle={Proceedings of the 34th Conference on Neural Information Processing Systems},
month={Dec. 6-12,},
year={2020}
}
@inproceedings{chen2020reinforcement,
author = {Chen, Yu and Wu, Lingfei and Zaki, Mohammed J.},
title = {Reinforcement Learning Based Graph-to-Sequence Model for Natural Question Generation},
booktitle = {Proceedings of the 8th International Conference on Learning Representations},
month = {Apr. 26-30,},
year = {2020}
}
@article{xu2018graph2seq,
title={Graph2seq: Graph to sequence learning with attention-based neural networks},
author={Xu, Kun and Wu, Lingfei and Wang, Zhiguo and Feng, Yansong and Witbrock, Michael and Sheinin, Vadim},
journal={arXiv preprint arXiv:1804.00823},
year={2018}
}
@inproceedings{li-etal-2020-graph-tree,
title = {Graph-to-Tree Neural Networks for Learning Structured Input-Output Translation with Applications to Semantic Parsing and Math Word Problem},
author = {Li, Shucheng and
Wu, Lingfei and
Feng, Shiwei and
Xu, Fangli and
Xu, Fengyuan and
Zhong, Sheng},
booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2020},
month = {Nov},
year = {2020}
}
@inproceedings{huang-etal-2020-knowledge,
title = {Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward},
author = {Huang, Luyang and
Wu, Lingfei and
Wang, Lu},
booktitle = {Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics},
month = {Jul},
year = {2020},
pages = {5094--5107}
}
@inproceedings{wu-etal-2018-word,
title = {Word Mover{'}s Embedding: From {W}ord2{V}ec to Document Embedding},
author = {Wu, Lingfei and
Yen, Ian En-Hsu and
Xu, Kun and
Xu, Fangli and
Balakrishnan, Avinash and
Chen, Pin-Yu and
Ravikumar, Pradeep and
Witbrock, Michael J.},
booktitle = {Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing},
pages = {4524--4534},
year = {2018},
}
@inproceedings{chen2020graphflow,
author = {Yu Chen and
Lingfei Wu and
Mohammed J. Zaki},
title = {GraphFlow: Exploiting Conversation Flow with Graph Neural Networks
for Conversational Machine Comprehension},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI} 2020},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {1230--1236},
year = {2020}
}
@inproceedings{shen2020hierarchical,
title={Hierarchical Attention Based Spatial-Temporal Graph-to-Sequence Learning for Grounded Video Description},
author={Shen, Kai and Wu, Lingfei and Xu, Fangli and Tang, Siliang and Xiao, Jun and Zhuang, Yueting},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI} 2020},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {941--947},
year = {2020}
}
@inproceedings{ijcai2020-419,
title = {RDF-to-Text Generation with Graph-augmented Structural Neural Encoders},
author = {Gao, Hanning and Wu, Lingfei and Hu, Po and Xu, Fangli},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI-20}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {3030--3036},
year = {2020}
}
Graph4ai 팀 : Lingfei Wu (팀장), Yu Chen, Kai Shen, Xiaojie Guo, Hanning Gao, Shucheng Li, Saizhuo Wang, Xiao Liu 및 Jing Hu. 우리는 자연어 처리를위한 그래프 기술에 대한 다양한 딥 러닝 기술을 쉽게 사용하는 것을 목표로하는 유용한 오픈 소스 라이브러리를 개발하는 데 열정적입니다. 우리 팀은 연구 과학자, 응용 데이터 과학자 및 Pinterest (Lingfei Wu), Zhejiang University (Kai Shen), Facebook AI (Yu Chen), IBM TJ Watson Research Center (Xiaojie Guo), Tongji University (Hanjing Gao), Nanjing Li (Shuchennning Li), IBM TJ Watson Research Center를 포함한 다양한 산업 및 학술 그룹의 대학원생으로 구성됩니다. (Saizhuo Wang).
기술적 인 질문이 있으시면 새로운 문제를 제출하십시오.
다른 질문이 있으시면 Lingfei Wu [[email protected]] 및 Xiaojie Guo [[email protected]] 에 문의하십시오.
Graph4NLP는 Apache License 2.0을 사용합니다.


