graph4nlp
v0.5.5-alpha

Graph4NLP adalah perpustakaan yang mudah digunakan untuk R&D di persimpangan pembelajaran mendalam pada grafik dan pemrosesan bahasa alami (yaitu, DLG4NLP). Ini memberikan implementasi lengkap model canggih untuk para ilmuwan data dan juga antarmuka fleksibel untuk membangun model khusus untuk para peneliti dan pengembang dengan dukungan seluruh pipa. Dibangun di atas pustaka runtime yang sangat dioptimalkan termasuk DGL, Graph4NLP memiliki efisiensi berjalan tinggi dan ekstensibilitas yang besar. Arsitektur Graph4NLP ditunjukkan pada gambar berikut, di mana kotak dengan garis putus -putus mewakili fitur yang sedang dikembangkan. Graph4NLP terdiri dari empat lapisan yang berbeda: 1) Lapisan data, 2) Lapisan modul, 3) Lapisan Model, dan 4) Lapisan Aplikasi.
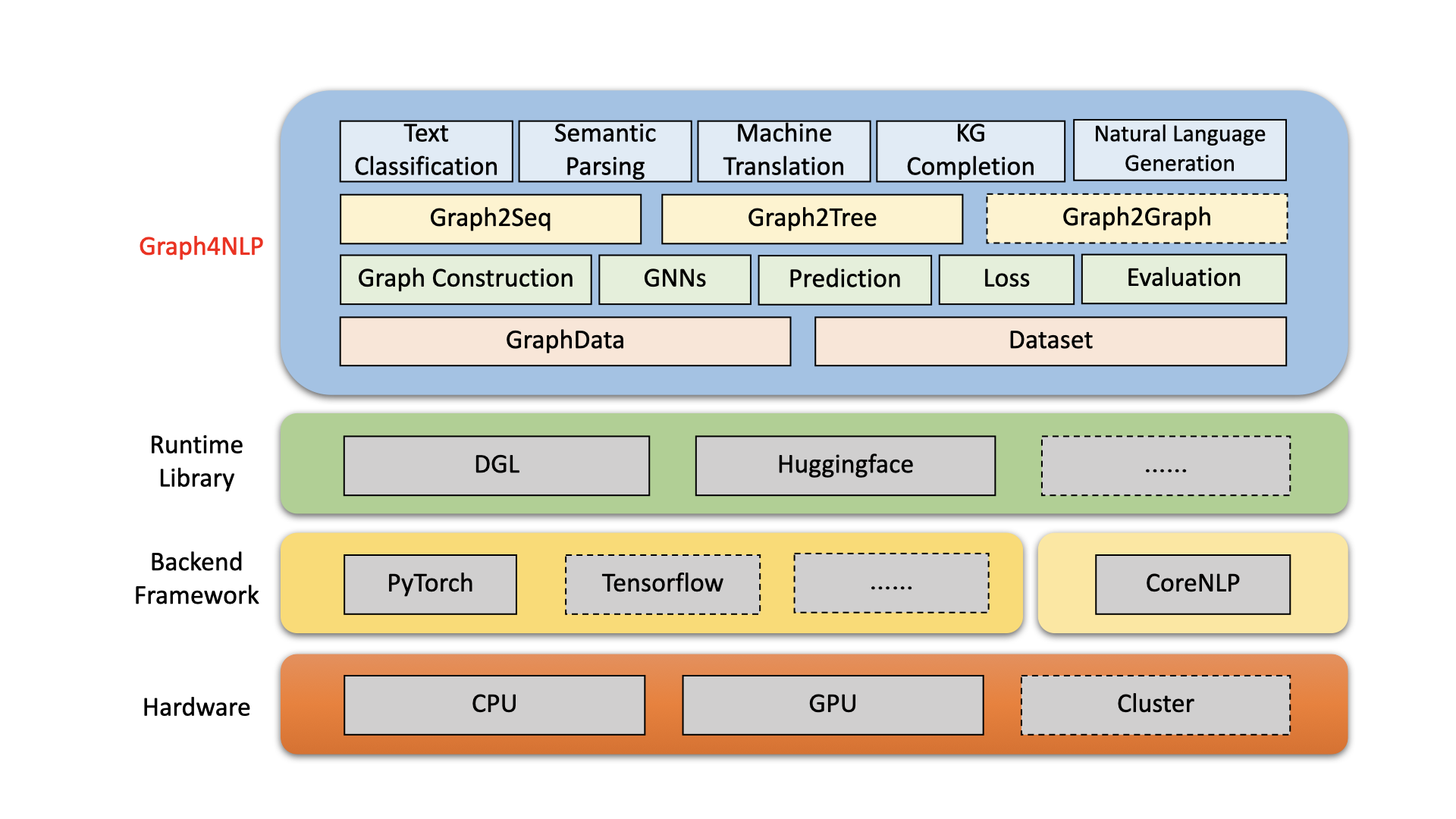
Gambar : Arsitektur Keseluruhan Graph4NLP
01/20/2022: Rilis V0.5.5 . Cobalah!
09/26/2021: Rilis V0.5.1 . Cobalah!
09/01/2021: Selamat datang untuk mengunjungi situs web DLG4NLP kami (https://dlg4nlp.github.io/index.html) untuk berbagai sumber belajar!
06/05/2021: Rilis V0.4.1 .
| Pelepasan | Tanggal | Fitur |
|---|---|---|
| V0.5.5 | 2022-01-20 | - Dukungan Model.Predict API dengan memperkenalkan fungsi pembungkus. - Perkenalkan tiga fungsi inferensi_wrapper baru: classifier_inference_wrapper, generator_inference_wrapper, generator_inference_wrapper_for_tree. - Tambahkan contoh inferensi dan inferensi_advance di setiap aplikasi. - Pisahkan proses embedding topologi dan grafik. - Perbarui semua fungsi konstruksi grafik. - Modul Graph_embedding dibagi menjadi graph_embedding_initialization dan graph_embedding_learning. - menyatukan parameter dalam dataset. Kami menghapus parameter ambigu graph_type dan memperkenalkan graph_name untuk menunjukkan metode konstruksi grafik dan static_or_dynamic untuk menunjukkan jenis konstruksi grafik statis atau dinamis.- Baru: Dataset sekarang dapat secara otomatis memilih metode default (misalnya, topology_builder ) dengan hanya satu parameter graph_name . |
| V0.5.1 | 2021-09-26 | - Lint The Codes - Dukungan pengujian dengan data pengguna sendiri - Perbaiki bug: Ukuran kata embedding dikodekan dalam versi 0.4.1. Sekarang sama dengan parameter "word_emb_size". - Perbaiki bug: build_vocab () disebut dua kali dalam versi 0.4.1. - Perbaiki bug: Dua file utama contoh penyelesaian grafik pengetahuan melewatkan parameter opsional "kg_graph" di peringkat_and_hits () saat melanjutkan pelatihan model. - Perbaiki bug: Kami telah memperbaiki kesalahan jalur preprocessing di KGC ReadMe. - Perbaiki bug: Kami telah memperbaiki bug konstruksi embedding saat mengatur emb_strategy ke 'w2v'. |
| V0.4.1 | 2021-06-05 | - Mendukung seluruh pipa graph4nlp - Dukungan GraphData dan Dataset |
Graph4NLP bertujuan untuk membuatnya sangat mudah digunakan GNN dalam tugas NLP (lihat dokumentasi Graph4NLP). Berikut adalah contoh cara menggunakan model graph2seq (banyak digunakan dalam terjemahan mesin, penjawab pertanyaan, penguraian semantik, dan berbagai tugas NLP lainnya yang dapat diabstraksi sebagai masalah grafik-ke-urutan dan telah menunjukkan kinerja yang unggul).
Kami juga menawarkan API model tingkat tinggi lainnya seperti model grafik-ke-pohon. Jika Anda tertarik dengan masalah penelitian terkait DLG4NLP, Anda sangat dipersilakan untuk menggunakan perpustakaan kami dan merujuk ke survei Graph4NLP kami.
from graph4nlp . pytorch . datasets . jobs import JobsDataset
from graph4nlp . pytorch . modules . graph_construction . dependency_graph_construction import DependencyBasedGraphConstruction
from graph4nlp . pytorch . modules . config import get_basic_args
from graph4nlp . pytorch . models . graph2seq import Graph2Seq
from graph4nlp . pytorch . modules . utils . config_utils import update_values , get_yaml_config
# build dataset
jobs_dataset = JobsDataset ( root_dir = 'graph4nlp/pytorch/test/dataset/jobs' ,
topology_builder = DependencyBasedGraphConstruction ,
topology_subdir = 'DependencyGraph' ) # You should run stanfordcorenlp at background
vocab_model = jobs_dataset . vocab_model
# build model
user_args = get_yaml_config ( "examples/pytorch/semantic_parsing/graph2seq/config/dependency_gcn_bi_sep_demo.yaml" )
args = get_basic_args ( graph_construction_name = "node_emb" , graph_embedding_name = "gat" , decoder_name = "stdrnn" )
update_values ( to_args = args , from_args_list = [ user_args ])
graph2seq = Graph2Seq . from_args ( args , vocab_model )
# calculation
batch_data = JobsDataset . collate_fn ( jobs_dataset . train [ 0 : 12 ])
scores = graph2seq ( batch_data [ "graph_data" ], batch_data [ "tgt_seq" ]) # [Batch_size, seq_len, Vocab_size] Aliran komputasi grafik kami ditampilkan di bawah ini.

Kami menyediakan koleksi aplikasi NLP yang komprehensif, bersama dengan contoh terperinci sebagai berikut:
Lingkungan: Torch 1.8, Ubuntu 16.04 dengan 2080Ti GPU
| Tugas | Dataset | Model GNN | Konstruksi Grafik | Evaluasi | Pertunjukan |
|---|---|---|---|---|---|
| Klasifikasi Teks | Trect Cairline CNSST | Gat | Ketergantungan Daerah pemilihan Ketergantungan | Ketepatan | 0.948 0.785 0,538 |
| Parsing semantik | Pekerjaan | SAGE | Daerah pemilihan | Akurasi eksekusi | 0.936 |
| Generasi pertanyaan | Pasukan | Ggnn | Ketergantungan | Bleu-4 | 0.15175 |
| Terjemahan mesin | IWSLT14 | GCN | Dinamis | Bleu-4 | 0.3212 |
| Peringkasan | CNN (30K) | GCN | Ketergantungan | Rouge-1 | 26.4 |
| Penyelesaian Grafik Pengetahuan | Kekerabatan | GCN | Ketergantungan | MRR | 82.4 |
| Masalah kata matematika | Mawps | SAGE | Dinamis | Akurasi solusi | 76.4 |
Saat ini, pengguna dapat menginstal Graph4NLP melalui PIP atau kode sumber . Graph4NLP mendukung OS berikut:
Kami menyediakan roda PIP untuk semua kombinasi OS/Pytorch/CUDA utama. Perhatikan bahwa kami sangat menyarankan pengguna Windows merujuk ke Installation via source code karena kompatibilitas.
Perhatikan bahwa >=1.6.0 OK.
$ python -c " import torch; print(torch.__version__) "
>>> 1.6.0$ python -c " import torch; print(torch.version.cuda) "
>>> 10.2 Diperlukan torchtext karena Graph4NLP mengandalkannya untuk mengimplementasikan embeddings. Harap perhatikan persyaratan Pytorch sebelum menginstal torchtext dengan skrip berikut! Untuk pencocokan versi terperinci, silakan merujuk di sini.
pip install torchtext # >=0.7.0 pip install graph4nlp ${CUDA} di mana ${CUDA} harus diganti dengan versi CUDA spesifik ( none (versi CPU), "-cu92" , "-cu101" , "-cu102" , "-cu110" ). Tabel berikut menunjukkan baris perintah beton. Untuk pengguna CUDA 11.1, silakan merujuk ke Installation via source code .
| Platform | Memerintah |
|---|---|
| CPU | pip install graph4nlp |
| CUDA 9.2 | pip install graph4nlp-cu92 |
| Cuda 10.1 | pip install graph4nlp-cu101 |
| CUDA 10.2 | pip install graph4nlp-cu102 |
| CUDA 11.0 | pip install graph4nlp-cu110 |
Perhatikan bahwa >=1.6.0 OK.
$ python -c " import torch; print(torch.__version__) "
>>> 1.6.0$ python -c " import torch; print(torch.version.cuda) "
>>> 10.2 Diperlukan torchtext karena Graph4NLP mengandalkannya untuk mengimplementasikan embeddings. Harap perhatikan persyaratan Pytorch sebelum menginstal torchtext dengan skrip berikut! Untuk pencocokan versi terperinci, silakan merujuk di sini.
pip install torchtext # >=0.7.0 Graph4NLP dari github: git clone https://github.com/graph4ai/graph4nlp.git
cd graph4nlp Kemudian jalankan ./configure (atau ./configure.bat jika Anda menggunakan Windows 10) untuk mengonfigurasi instalasi Anda. Program konfigurasi akan meminta Anda untuk menentukan versi CUDA Anda. Jika Anda tidak memiliki GPU, silakan ketik 'CPU'.
./configureAkhirnya, instal paket:
python setup.py installKami menunjukkan beberapa hyperparameters yang sering disetel di sini.
Jika Anda ingin mempelajari lebih lanjut tentang menerapkan pembelajaran mendalam pada teknik grafik untuk tugas NLP, selamat datang untuk mengunjungi situs web DLG4NLP kami (https://dlg4nlp.github.io/index.html) untuk berbagai sumber belajar! Anda dapat merujuk ke makalah survei kami yang memberikan gambaran umum tentang arah penelitian yang ada ini. Jika Anda ingin referensi terperinci ke perpustakaan kami, silakan merujuk ke dokumen kami.
Beri tahu kami jika Anda menemukan bug atau memiliki saran dengan mengajukan masalah.
Kami menyambut semua kontribusi dari perbaikan bug ke fitur dan ekstensi baru.
Kami berharap semua kontribusi yang dibahas dalam pelacak masalah dan melalui PRS.
Jika Anda menemukan kode ini bermanfaat, silakan pertimbangkan mengutip makalah berikut.
@article{wu2021graph,
title={Graph Neural Networks for Natural Language Processing: A Survey},
author={Lingfei Wu and Yu Chen and Kai Shen and Xiaojie Guo and Hanning Gao and Shucheng Li and Jian Pei and Bo Long},
journal={arXiv preprint arXiv:2106.06090},
year={2021}
}
@inproceedings{chen2020iterative,
title={Iterative Deep Graph Learning for Graph Neural Networks: Better and Robust Node Embeddings},
author={Chen, Yu and Wu, Lingfei and Zaki, Mohammed J},
booktitle={Proceedings of the 34th Conference on Neural Information Processing Systems},
month={Dec. 6-12,},
year={2020}
}
@inproceedings{chen2020reinforcement,
author = {Chen, Yu and Wu, Lingfei and Zaki, Mohammed J.},
title = {Reinforcement Learning Based Graph-to-Sequence Model for Natural Question Generation},
booktitle = {Proceedings of the 8th International Conference on Learning Representations},
month = {Apr. 26-30,},
year = {2020}
}
@article{xu2018graph2seq,
title={Graph2seq: Graph to sequence learning with attention-based neural networks},
author={Xu, Kun and Wu, Lingfei and Wang, Zhiguo and Feng, Yansong and Witbrock, Michael and Sheinin, Vadim},
journal={arXiv preprint arXiv:1804.00823},
year={2018}
}
@inproceedings{li-etal-2020-graph-tree,
title = {Graph-to-Tree Neural Networks for Learning Structured Input-Output Translation with Applications to Semantic Parsing and Math Word Problem},
author = {Li, Shucheng and
Wu, Lingfei and
Feng, Shiwei and
Xu, Fangli and
Xu, Fengyuan and
Zhong, Sheng},
booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2020},
month = {Nov},
year = {2020}
}
@inproceedings{huang-etal-2020-knowledge,
title = {Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward},
author = {Huang, Luyang and
Wu, Lingfei and
Wang, Lu},
booktitle = {Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics},
month = {Jul},
year = {2020},
pages = {5094--5107}
}
@inproceedings{wu-etal-2018-word,
title = {Word Mover{'}s Embedding: From {W}ord2{V}ec to Document Embedding},
author = {Wu, Lingfei and
Yen, Ian En-Hsu and
Xu, Kun and
Xu, Fangli and
Balakrishnan, Avinash and
Chen, Pin-Yu and
Ravikumar, Pradeep and
Witbrock, Michael J.},
booktitle = {Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing},
pages = {4524--4534},
year = {2018},
}
@inproceedings{chen2020graphflow,
author = {Yu Chen and
Lingfei Wu and
Mohammed J. Zaki},
title = {GraphFlow: Exploiting Conversation Flow with Graph Neural Networks
for Conversational Machine Comprehension},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI} 2020},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {1230--1236},
year = {2020}
}
@inproceedings{shen2020hierarchical,
title={Hierarchical Attention Based Spatial-Temporal Graph-to-Sequence Learning for Grounded Video Description},
author={Shen, Kai and Wu, Lingfei and Xu, Fangli and Tang, Siliang and Xiao, Jun and Zhuang, Yueting},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI} 2020},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {941--947},
year = {2020}
}
@inproceedings{ijcai2020-419,
title = {RDF-to-Text Generation with Graph-augmented Structural Neural Encoders},
author = {Gao, Hanning and Wu, Lingfei and Hu, Po and Xu, Fangli},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI-20}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {3030--3036},
year = {2020}
}
Tim Graph4ai: Lingfei Wu (pemimpin tim), Yu Chen, Kai Shen, Xiaojie Guo, Hanning Gao, Shucheng LI, Saizhuo Wang, Xiao Liu dan Jing Hu. Kami bersemangat dalam mengembangkan perpustakaan open-source yang berguna yang bertujuan untuk mempromosikan mudah penggunaan berbagai pembelajaran mendalam pada teknik grafik untuk pemrosesan bahasa alami. Tim kami terdiri dari ilmuwan penelitian, ilmuwan data terapan, dan mahasiswa pascasarjana dari berbagai kelompok industri dan akademik, termasuk Pinterest (Lingfei Wu), Universitas Zhejiang (Kai Shen), Facebook AI (Universitas Yu), Hanning Gao, Hanning Gao, Universitas Hanning Gao (NANAOOJIE), HANINING GA. (Saizhuo Wang).
Jika Anda memiliki pertanyaan teknis, silakan kirimkan masalah baru.
Jika Anda memiliki pertanyaan lain, silakan hubungi kami: Lingfei Wu [[email protected]] dan Xiaojie Guo [[email protected]] .
Graph4NLP menggunakan lisensi Apache 2.0.


