graph4nlp
v0.5.5-alpha

Graph4NLP -это простая в использовании библиотеку для НИОКР на пересечении глубокого обучения на графиках и обработке естественного языка (то есть, DLG4NLP). Он предоставляет как полную реализацию современных моделей для ученых-ученых, так и гибких интерфейсов для создания индивидуальных моделей для исследователей и разработчиков с поддержкой цельной питлины. Построенный на очень оптимизированных библиотеках выполнения, включая DGL, Graph4NLP обладает как высокой эффективностью, так и большой расширяемостью. Архитектура Graph4NLP показана на следующем рисунке, где коробки с пунктирными линиями представляют собой разрабатываемые функции. Graph4NLP состоит из четырех разных слоев: 1) слой данных, 2) уровня модуля, 3) модели -слой и 4) прикладного уровня.
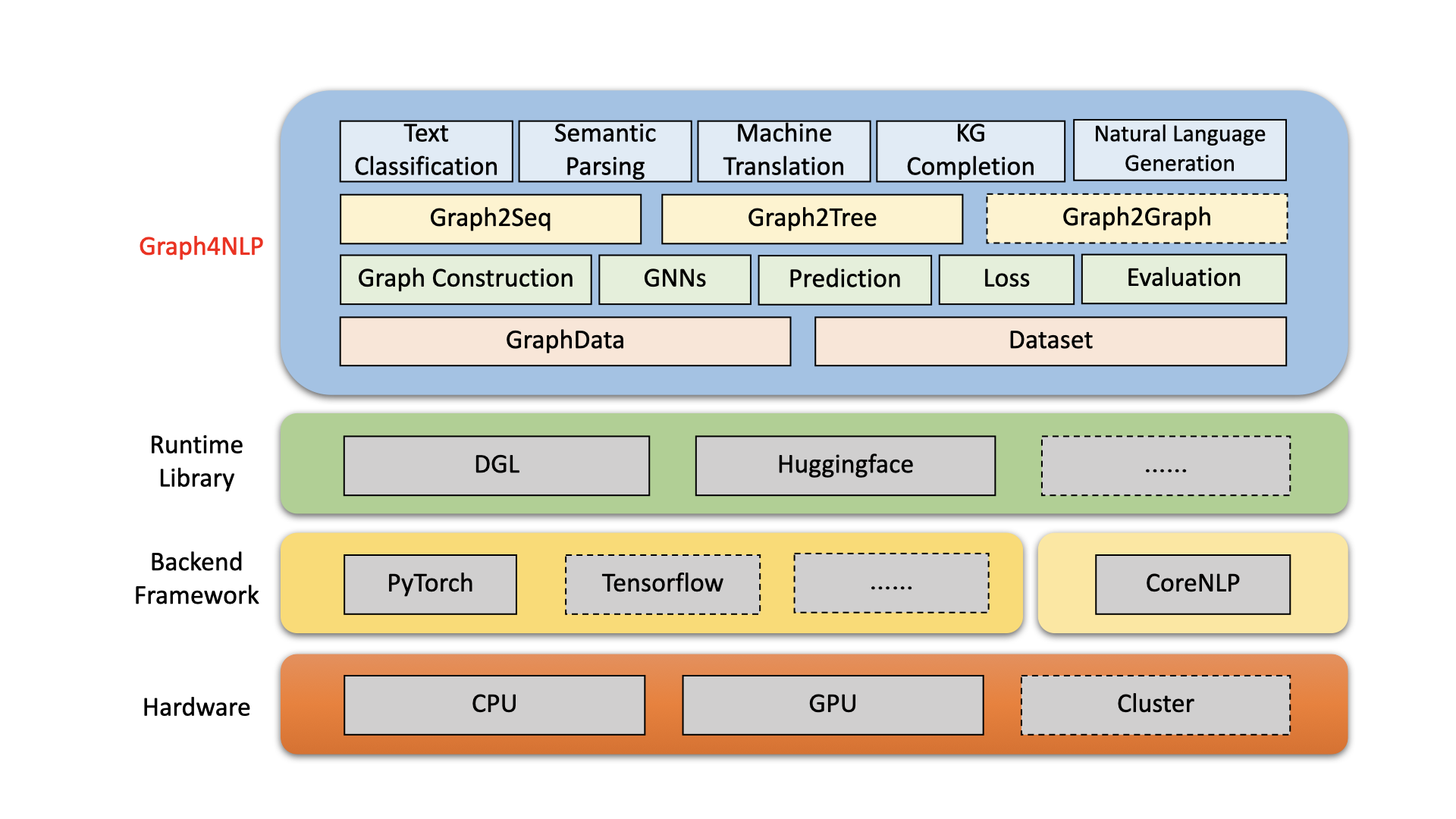
Рисунок : Graph4nlp Общая архитектура
20.01.2022: релиз V0.5.5 . Попробуйте!
26.09.2021: релиз V0.5.1 . Попробуйте!
01.09.2021: Добро пожаловать, чтобы посетить наш веб -сайт DLG4NLP (https://dlg4nlp.github.io/index.html) для различных учебных ресурсов!
06/05/2021: V0.4.1 .
| Выпуски | Дата | Функции |
|---|---|---|
| V0.5.5 | 2022-01-20 | - Поддержка модели. Predict API, введя функции обертки. - Введите три новых функции specure_wrapper: classifier_inference_wrapper, generator_inference_wrapper, generator_inference_wrapper_for_tree. - Добавьте примеры вывода и вывода. - Разделите топологию графика и процесс встроения графика. - Обновите все функции построения графика. - Модуль graph_embedding делится на graph_embedding_initialization и graph_embedding_learning. - объединить параметры в наборе данных. Мы удаляем неоднозначный параметр graph_type и вводим graph_name , чтобы указать метод построения графа и static_or_dynamic , чтобы указать тип статического или динамического построения графика.- Новое: набор данных теперь может автоматически выбирать методы по умолчанию (например, topology_builder ) только одним параметра graph_name . |
| V0.5.1 | 2021-09-26 | - Заполните коды - Поддержка тестирования с помощью собственных данных пользователей - Исправьте ошибку: размер встраивания слова был жестко кодирован в версии 0.4.1. Теперь это равно параметру "word_emb_size". - Исправьте ошибку: build_vocab () называется дважды в версии 0.4.1. - Исправить ошибку: два основных файла примера завершения графа знаний пропустили необязательный параметр «kg_graph» в Ranking_and_hits () при возобновлении обучения модели. - Исправьте ошибку: мы исправили ошибку пути предварительной обработки в KGC Readme. - Исправьте ошибку: у нас есть исправленная строительная ошибка встраивания при установке EMB_STRATEGY в W2V. |
| v0.4.1 | 2021-06-05 | - Поддержите весь трубопровод Graph4nlp - Поддержка GraphData и DataSet |
Graph4NLP стремится сделать его невероятно простым в использовании GNN в задачах NLP (проверьте документацию Graph4NLP). Вот пример того, как использовать модель Graph2seq (широко используется в машинном переводе, ответе на вопросы, семантическом анализе и различных других задачах НЛП, которые могут быть абстрактны как задача графа к последовательности и показали превосходную производительность).
Мы также предлагаем другие высокоуровневые модельные API, такие как модели с графом в REE. Если вы заинтересованы в проблемах исследований, связанных с DLG4NLP, вы можете использовать нашу библиотеку и обратиться к нашему опросу Graph4NLP.
from graph4nlp . pytorch . datasets . jobs import JobsDataset
from graph4nlp . pytorch . modules . graph_construction . dependency_graph_construction import DependencyBasedGraphConstruction
from graph4nlp . pytorch . modules . config import get_basic_args
from graph4nlp . pytorch . models . graph2seq import Graph2Seq
from graph4nlp . pytorch . modules . utils . config_utils import update_values , get_yaml_config
# build dataset
jobs_dataset = JobsDataset ( root_dir = 'graph4nlp/pytorch/test/dataset/jobs' ,
topology_builder = DependencyBasedGraphConstruction ,
topology_subdir = 'DependencyGraph' ) # You should run stanfordcorenlp at background
vocab_model = jobs_dataset . vocab_model
# build model
user_args = get_yaml_config ( "examples/pytorch/semantic_parsing/graph2seq/config/dependency_gcn_bi_sep_demo.yaml" )
args = get_basic_args ( graph_construction_name = "node_emb" , graph_embedding_name = "gat" , decoder_name = "stdrnn" )
update_values ( to_args = args , from_args_list = [ user_args ])
graph2seq = Graph2Seq . from_args ( args , vocab_model )
# calculation
batch_data = JobsDataset . collate_fn ( jobs_dataset . train [ 0 : 12 ])
scores = graph2seq ( batch_data [ "graph_data" ], batch_data [ "tgt_seq" ]) # [Batch_size, seq_len, Vocab_size] Наш вычислительный поток Graph4NLP показан ниже.

Мы предоставляем комплексную коллекцию приложений NLP, а также подробные примеры следующим образом:
Окружающая среда: Torch 1.8, Ubuntu 16.04 с 2080ti графические процессоры
| Задача | Набор данных | Модель GNN | График конструкция | Оценка | Производительность |
|---|---|---|---|---|---|
| Текстовая классификация | Трепт CAIRLINE CNSST | Газ | Зависимость Избирательный округ Зависимость | Точность | 0,948 0,785 0,538 |
| Семантический анализ | Рабочие места | МУДРЕЦ | Избирательный округ | Точность исполнения | 0,936 |
| Генерация вопросов | Отряд | Ггнн | Зависимость | Bleu-4 | 0,15175 |
| Машинный перевод | IWSLT14 | GCN | Динамика | Bleu-4 | 0,3212 |
| Суммирование | CNN (30K) | GCN | Зависимость | Rouge-1 | 26.4 |
| Завершение графа знаний | Родство | GCN | Зависимость | MRR | 82.4 |
| Проблема по математике | Маупс | МУДРЕЦ | Динамика | Точность решения | 76.4 |
В настоящее время пользователи могут устанавливать graph4nlp через PIP или исходный код . Graph4nlp поддерживает следующие OSES:
Мы предоставляем колеса PIP для всех основных комбинаций OS/Pytorch/Cuda. Обратите внимание, что мы настоятельно рекомендуем пользователям Windows обратиться к Installation via source code из -за совместимости.
Обратите внимание, что >=1.6.0 в порядке.
$ python -c " import torch; print(torch.__version__) "
>>> 1.6.0$ python -c " import torch; print(torch.version.cuda) "
>>> 10.2 torchtext необходим, так как Graph4NLP полагается на него для реализации Enterdings. Пожалуйста, обратите внимание на требования Pytorch перед установкой torchtext со следующим сценарием! Для получения подробной версии, пожалуйста, обратитесь к здесь.
pip install torchtext # >=0.7.0 pip install graph4nlp ${CUDA} где ${CUDA} должно быть заменено конкретной версией CUDA ( none (версия CPU), "-cu92" , "-cu101" , "-cu102" , "-cu110" ). В следующей таблице показаны конкретные командные строки. Для пользователей CUDA 11.1, пожалуйста, обратитесь к Installation via source code .
| Платформа | Командование |
|---|---|
| Процессор | pip install graph4nlp |
| CUDA 9.2 | pip install graph4nlp-cu92 |
| CUDA 10.1 | pip install graph4nlp-cu101 |
| CUDA 10.2 | pip install graph4nlp-cu102 |
| Cuda 11.0 | pip install graph4nlp-cu110 |
Обратите внимание, что >=1.6.0 в порядке.
$ python -c " import torch; print(torch.__version__) "
>>> 1.6.0$ python -c " import torch; print(torch.version.cuda) "
>>> 10.2 torchtext необходим, так как Graph4NLP полагается на него для реализации Enterdings. Пожалуйста, обратите внимание на требования Pytorch перед установкой torchtext со следующим сценарием! Для получения подробной версии, пожалуйста, обратитесь к здесь.
pip install torchtext # >=0.7.0 Graph4NLP из GitHub: git clone https://github.com/graph4ai/graph4nlp.git
cd graph4nlp Затем запустите ./configure (или ./configure.bat если вы используете Windows 10) для настройки установки. Программа конфигурации попросит вас указать вашу версию CUDA. Если у вас нет графического процессора, пожалуйста, введите «процессор».
./configureНаконец, установите пакет:
python setup.py installМы показываем некоторые из гиперпараметров, которые часто настраиваются здесь.
Если вы хотите узнать больше о применении глубокого обучения на методах графиков к задачам NLP, добро пожаловать, чтобы посетить наш веб -сайт DLG4NLP (https://dlg4nlp.github.io/index.html) для различных учебных ресурсов! Вы можете ссылаться на нашу документацию, в которой представлен обзор этого существующего направления исследования. Если вам нужна подробная ссылка на нашу библиотеку, пожалуйста, обратитесь к нашим документам.
Пожалуйста, дайте нам знать, если вы столкнетесь с ошибкой или у вас есть какие -либо предложения, подав проблему.
Мы приветствуем все вклад от исправлений ошибок в новые функции и расширения.
Мы ожидаем, что все вклады, обсуждаемые в The The Change Tracker и пройдя PRS.
Если вы нашли этот код полезным, пожалуйста, рассмотрите возможность сослаться на следующие документы.
@article{wu2021graph,
title={Graph Neural Networks for Natural Language Processing: A Survey},
author={Lingfei Wu and Yu Chen and Kai Shen and Xiaojie Guo and Hanning Gao and Shucheng Li and Jian Pei and Bo Long},
journal={arXiv preprint arXiv:2106.06090},
year={2021}
}
@inproceedings{chen2020iterative,
title={Iterative Deep Graph Learning for Graph Neural Networks: Better and Robust Node Embeddings},
author={Chen, Yu and Wu, Lingfei and Zaki, Mohammed J},
booktitle={Proceedings of the 34th Conference on Neural Information Processing Systems},
month={Dec. 6-12,},
year={2020}
}
@inproceedings{chen2020reinforcement,
author = {Chen, Yu and Wu, Lingfei and Zaki, Mohammed J.},
title = {Reinforcement Learning Based Graph-to-Sequence Model for Natural Question Generation},
booktitle = {Proceedings of the 8th International Conference on Learning Representations},
month = {Apr. 26-30,},
year = {2020}
}
@article{xu2018graph2seq,
title={Graph2seq: Graph to sequence learning with attention-based neural networks},
author={Xu, Kun and Wu, Lingfei and Wang, Zhiguo and Feng, Yansong and Witbrock, Michael and Sheinin, Vadim},
journal={arXiv preprint arXiv:1804.00823},
year={2018}
}
@inproceedings{li-etal-2020-graph-tree,
title = {Graph-to-Tree Neural Networks for Learning Structured Input-Output Translation with Applications to Semantic Parsing and Math Word Problem},
author = {Li, Shucheng and
Wu, Lingfei and
Feng, Shiwei and
Xu, Fangli and
Xu, Fengyuan and
Zhong, Sheng},
booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2020},
month = {Nov},
year = {2020}
}
@inproceedings{huang-etal-2020-knowledge,
title = {Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward},
author = {Huang, Luyang and
Wu, Lingfei and
Wang, Lu},
booktitle = {Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics},
month = {Jul},
year = {2020},
pages = {5094--5107}
}
@inproceedings{wu-etal-2018-word,
title = {Word Mover{'}s Embedding: From {W}ord2{V}ec to Document Embedding},
author = {Wu, Lingfei and
Yen, Ian En-Hsu and
Xu, Kun and
Xu, Fangli and
Balakrishnan, Avinash and
Chen, Pin-Yu and
Ravikumar, Pradeep and
Witbrock, Michael J.},
booktitle = {Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing},
pages = {4524--4534},
year = {2018},
}
@inproceedings{chen2020graphflow,
author = {Yu Chen and
Lingfei Wu and
Mohammed J. Zaki},
title = {GraphFlow: Exploiting Conversation Flow with Graph Neural Networks
for Conversational Machine Comprehension},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI} 2020},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {1230--1236},
year = {2020}
}
@inproceedings{shen2020hierarchical,
title={Hierarchical Attention Based Spatial-Temporal Graph-to-Sequence Learning for Grounded Video Description},
author={Shen, Kai and Wu, Lingfei and Xu, Fangli and Tang, Siliang and Xiao, Jun and Zhuang, Yueting},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI} 2020},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {941--947},
year = {2020}
}
@inproceedings{ijcai2020-419,
title = {RDF-to-Text Generation with Graph-augmented Structural Neural Encoders},
author = {Gao, Hanning and Wu, Lingfei and Hu, Po and Xu, Fangli},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI-20}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {3030--3036},
year = {2020}
}
Команда Graph4ai: Lingfei Wu (руководитель команды), Ю Чен, Кай Шен, Сяоджи Го, Ханнинг Гао, Шученг Ли, Саучхуо Ван, Сяо Лю и Цзин Ху. Мы увлечены разработкой полезных библиотек с открытым исходным кодом, которые направлены на то, чтобы способствовать легкому использованию различных глубоких обучения методам графиков для обработки естественного языка. Наша команда состоит из исследователей, ученых, прикладных данных и аспирантов из различных промышленных и академических групп, в том числе Pinterest (Lingfei Wu), Чжэцзянский университет (Kai Shen), Facebook AI (Yu Chen), IBM TJ Watson Research Center (Siaojie guo), huchustize li), hucheng hukenize li Ван).
Если у вас есть какие -либо технические вопросы, пожалуйста, отправьте новые проблемы.
Если у вас есть какие -либо другие вопросы, пожалуйста, свяжитесь с нами: Lingfei wu [[email protected]] и Xiaojie Guo [[email protected]] .
Graph4nlp использует Apache License 2.0.


