graph4nlp
v0.5.5-alpha

O Graph4NLP é uma biblioteca fácil de usar para P&D no cruzamento de aprendizado profundo em gráficos e processamento de linguagem natural (ou seja, dlg4nlp). Ele fornece implementações completas de modelos de ponta para cientistas de dados e também interfaces flexíveis para criar modelos personalizados para pesquisadores e desenvolvedores com suporte de linha inteira. Construído em bibliotecas de tempo de execução altamente otimizadas, incluindo o DGL, o Graph4NLP possui alta eficiência de execução e grande extensibilidade. A arquitetura do Graph4NLP é mostrada na figura a seguir, onde caixas com linhas tracejadas representam os recursos em desenvolvimento. Graph4NLP consiste em quatro camadas diferentes: 1) camada de dados, 2) camada de módulo, 3) camada do modelo e 4) camada de aplicação.
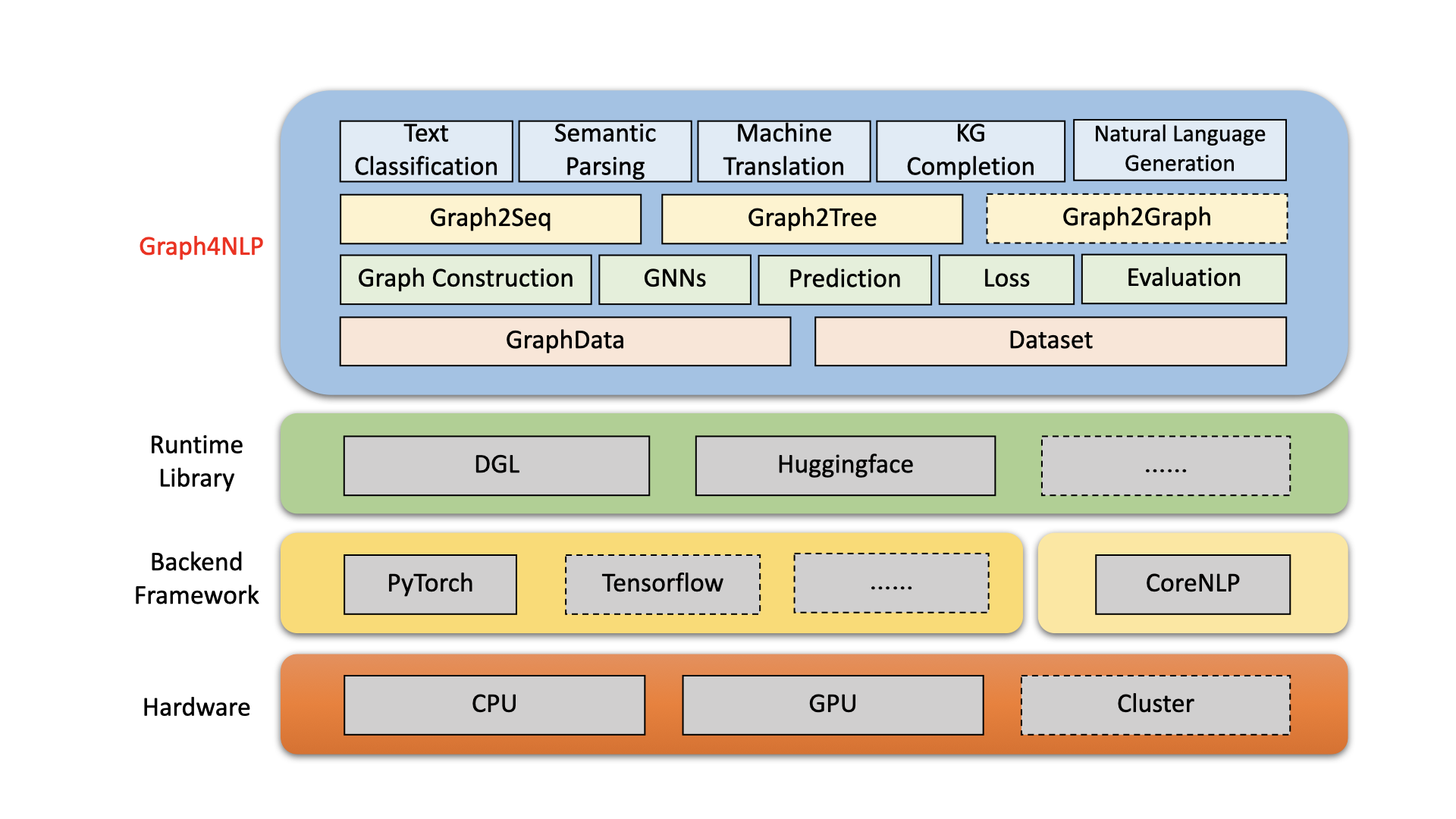
Figura : Arquitetura geral do Graph4NLP
20/01/2022: a versão v0.5.5 . Experimente!
26/09/2021: a versão v0.5.1 . Experimente!
01/09/2021: Bem -vindo para visitar nosso site dlg4nlp (https://dlg4nlp.github.io/index.html) para vários recursos de aprendizado!
05/06/2021: a versão v0.4.1 .
| Lançamentos | Data | Características |
|---|---|---|
| v0.5.5 | 2022-01-20 | - API de suporte a Model.Predict, introduzindo funções de wrapper. - Introduzir três novas funções inferenciadas_wrapper: classifier_inference_wrapper, generator_inference_wrapper, generator_inference_wrapper_for_tree. - Adicione os exemplos de inferência e inferência_advance em cada aplicativo. - Separe o processo de topologia de gráficos e incorporação de gráfico. - Renove todas as funções de construção de gráficos. - Module Graph_Embedding é dividido em graf_embedding_initialization e graf_embedding_learning. - Unifique os parâmetros no conjunto de dados. Removemos o parâmetro ambíguo graph_type e introduzimos graph_name para indicar o método de construção de gráficos e static_or_dynamic para indicar o tipo de construção de gráficos estáticos ou dinâmicos.- Novo: o conjunto de dados agora pode escolher automaticamente os métodos padrão (por exemplo, topology_builder ) por apenas um parâmetro graph_name . |
| v0.5.1 | 2021-09-26 | - fie os códigos - Suporte a testes com os próprios dados dos usuários - Corrija o bug: o tamanho da palavra incorporação foi codificado na versão 0.4.1. Agora é igual ao parâmetro "word_emb_size". - Fix o bug: o build_vocab () é chamado duas vezes na versão 0.4.1. - Corrija o bug: os dois arquivos principais do exemplo de conclusão do gráfico de conhecimento perderam o parâmetro opcional "kg_graph" em ranking_and_hits () ao retomar o treinamento do modelo. - Corrija o bug: corrigimos o erro do caminho de pré -processamento no KGC ReadMe. - Corrija o bug: corrigimos a incorporação de bug de construção ao definir o EMB_STRAYGIA como 'W2V'. |
| v0.4.1 | 2021-06-05 | - Suporte a todo o pipeline de graf4nlp - Suporte a graphData e conjunto de dados |
O Graph4NLP visa facilitar o uso de GNNs em tarefas de NLP (confira a documentação do Graph4NLP). Aqui está um exemplo de como usar o modelo Graph2SEQ (amplamente usado na tradução da máquina, resposta a perguntas, análise semântica e várias outras tarefas de PNL que podem ser abstratas como problema de gráfico de sequência e mostraram desempenho superior).
Também oferecemos outras APIs de modelo de alto nível, como modelos de gráfico para árvore. Se você estiver interessado em problemas de pesquisa relacionados ao DLG4NLP, poderá usar nossa biblioteca e se referir à nossa pesquisa Graph4NLP.
from graph4nlp . pytorch . datasets . jobs import JobsDataset
from graph4nlp . pytorch . modules . graph_construction . dependency_graph_construction import DependencyBasedGraphConstruction
from graph4nlp . pytorch . modules . config import get_basic_args
from graph4nlp . pytorch . models . graph2seq import Graph2Seq
from graph4nlp . pytorch . modules . utils . config_utils import update_values , get_yaml_config
# build dataset
jobs_dataset = JobsDataset ( root_dir = 'graph4nlp/pytorch/test/dataset/jobs' ,
topology_builder = DependencyBasedGraphConstruction ,
topology_subdir = 'DependencyGraph' ) # You should run stanfordcorenlp at background
vocab_model = jobs_dataset . vocab_model
# build model
user_args = get_yaml_config ( "examples/pytorch/semantic_parsing/graph2seq/config/dependency_gcn_bi_sep_demo.yaml" )
args = get_basic_args ( graph_construction_name = "node_emb" , graph_embedding_name = "gat" , decoder_name = "stdrnn" )
update_values ( to_args = args , from_args_list = [ user_args ])
graph2seq = Graph2Seq . from_args ( args , vocab_model )
# calculation
batch_data = JobsDataset . collate_fn ( jobs_dataset . train [ 0 : 12 ])
scores = graph2seq ( batch_data [ "graph_data" ], batch_data [ "tgt_seq" ]) # [Batch_size, seq_len, Vocab_size] Nosso fluxo de computação Graph4NLP é mostrado como abaixo.

Fornecemos uma coleção abrangente de aplicativos de PNL, juntamente com exemplos detalhados da seguinte forma:
Ambiente: Torch 1.8, Ubuntu 16.04 com 2080ti GPUS
| Tarefa | Conjunto de dados | Modelo GNN | Construção de gráficos | Avaliação | Desempenho |
|---|---|---|---|---|---|
| Classificação de texto | Trect Linha de pedras CNSST | Gat | Dependência Extérito Dependência | Precisão | 0,948 0,785 0,538 |
| Parsing semântico | Empregos | SÁBIO | Extérito | Precisão da execução | 0,936 |
| Geração de perguntas | Esquadrão | Ggnn | Dependência | Bleu-4 | 0,15175 |
| Tradução da máquina | IWSLT14 | Gcn | Dinâmico | Bleu-4 | 0,3212 |
| Resumo | CNN (30K) | Gcn | Dependência | Rouge-1 | 26.4 |
| Conclusão do gráfico de conhecimento | Parentesco | Gcn | Dependência | Mrr | 82.4 |
| Problema da palavra matemática | Mawps | SÁBIO | Dinâmico | Precisão da solução | 76.4 |
Atualmente, os usuários podem instalar o Graph4NLP via PIP ou código -fonte . Graph4NLP suporta os seguintes operacionais:
Fornecemos rodas PIP para todas as principais combinações de OS/Pytorch/Cuda. Observe que é altamente recomendável que os usuários Windows consulte a Installation via source code devido à compatibilidade.
Observe que >=1.6.0 está ok.
$ python -c " import torch; print(torch.__version__) "
>>> 1.6.0$ python -c " import torch; print(torch.version.cuda) "
>>> 10.2 torchtext é necessário, pois o Graph4NLP conta com ele para implementar incorporação. Preste atenção aos requisitos do Pytorch antes de instalar torchtext com o script a seguir! Para correspondência detalhada da versão, consulte aqui.
pip install torchtext # >=0.7.0 pip install graph4nlp ${CUDA} onde ${CUDA} deve ser substituído pela versão CUDA específica ( none (versão da CPU), "-cu92" , "-cu101" , "-cu102" , "-cu110" ). A tabela a seguir mostra as linhas de comando concreto. Para usuários do CUDA 11.1, consulte a Installation via source code .
| Plataforma | Comando |
|---|---|
| CPU | pip install graph4nlp |
| CUDA 9.2 | pip install graph4nlp-cu92 |
| CUDA 10.1 | pip install graph4nlp-cu101 |
| CUDA 10.2 | pip install graph4nlp-cu102 |
| CUDA 11.0 | pip install graph4nlp-cu110 |
Observe que >=1.6.0 está ok.
$ python -c " import torch; print(torch.__version__) "
>>> 1.6.0$ python -c " import torch; print(torch.version.cuda) "
>>> 10.2 torchtext é necessário, pois o Graph4NLP conta com ele para implementar incorporação. Preste atenção aos requisitos do Pytorch antes de instalar torchtext com o script a seguir! Para correspondência detalhada da versão, consulte aqui.
pip install torchtext # >=0.7.0 Graph4NLP do Github: git clone https://github.com/graph4ai/graph4nlp.git
cd graph4nlp Em seguida, execute ./configure (ou ./configure.bat se você estiver usando o Windows 10) para configurar sua instalação. O programa de configuração solicitará que você especifique sua versão CUDA. Se você não tiver uma GPU, digite 'CPU'.
./configurePor fim, instale o pacote:
python setup.py installMostramos alguns dos hiperparâmetros que geralmente são sintonizados aqui.
Se você quiser saber mais sobre a aplicação de técnicas de aprendizado profundo nas tarefas de PNL, seja bem -vindo para visitar nosso site dlg4nlp (https://dlg4nlp.github.io/index.html) para vários recursos de aprendizado! Você pode se referir ao nosso documento de pesquisa, que fornece uma visão geral dessa direção de pesquisa existente. Se você deseja referência detalhada à nossa biblioteca, consulte nossos documentos.
Informe -nos se você encontrar um bug ou tiver alguma sugestão, apresentando um problema.
Congratulamo -nos com todas as contribuições de correções de bugs para novos recursos e extensões.
Esperamos todas as contribuições discutidas no rastreador de questões e passando pelo PRS.
Se você achou esse código útil, considere citar os documentos a seguir.
@article{wu2021graph,
title={Graph Neural Networks for Natural Language Processing: A Survey},
author={Lingfei Wu and Yu Chen and Kai Shen and Xiaojie Guo and Hanning Gao and Shucheng Li and Jian Pei and Bo Long},
journal={arXiv preprint arXiv:2106.06090},
year={2021}
}
@inproceedings{chen2020iterative,
title={Iterative Deep Graph Learning for Graph Neural Networks: Better and Robust Node Embeddings},
author={Chen, Yu and Wu, Lingfei and Zaki, Mohammed J},
booktitle={Proceedings of the 34th Conference on Neural Information Processing Systems},
month={Dec. 6-12,},
year={2020}
}
@inproceedings{chen2020reinforcement,
author = {Chen, Yu and Wu, Lingfei and Zaki, Mohammed J.},
title = {Reinforcement Learning Based Graph-to-Sequence Model for Natural Question Generation},
booktitle = {Proceedings of the 8th International Conference on Learning Representations},
month = {Apr. 26-30,},
year = {2020}
}
@article{xu2018graph2seq,
title={Graph2seq: Graph to sequence learning with attention-based neural networks},
author={Xu, Kun and Wu, Lingfei and Wang, Zhiguo and Feng, Yansong and Witbrock, Michael and Sheinin, Vadim},
journal={arXiv preprint arXiv:1804.00823},
year={2018}
}
@inproceedings{li-etal-2020-graph-tree,
title = {Graph-to-Tree Neural Networks for Learning Structured Input-Output Translation with Applications to Semantic Parsing and Math Word Problem},
author = {Li, Shucheng and
Wu, Lingfei and
Feng, Shiwei and
Xu, Fangli and
Xu, Fengyuan and
Zhong, Sheng},
booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2020},
month = {Nov},
year = {2020}
}
@inproceedings{huang-etal-2020-knowledge,
title = {Knowledge Graph-Augmented Abstractive Summarization with Semantic-Driven Cloze Reward},
author = {Huang, Luyang and
Wu, Lingfei and
Wang, Lu},
booktitle = {Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics},
month = {Jul},
year = {2020},
pages = {5094--5107}
}
@inproceedings{wu-etal-2018-word,
title = {Word Mover{'}s Embedding: From {W}ord2{V}ec to Document Embedding},
author = {Wu, Lingfei and
Yen, Ian En-Hsu and
Xu, Kun and
Xu, Fangli and
Balakrishnan, Avinash and
Chen, Pin-Yu and
Ravikumar, Pradeep and
Witbrock, Michael J.},
booktitle = {Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing},
pages = {4524--4534},
year = {2018},
}
@inproceedings{chen2020graphflow,
author = {Yu Chen and
Lingfei Wu and
Mohammed J. Zaki},
title = {GraphFlow: Exploiting Conversation Flow with Graph Neural Networks
for Conversational Machine Comprehension},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI} 2020},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {1230--1236},
year = {2020}
}
@inproceedings{shen2020hierarchical,
title={Hierarchical Attention Based Spatial-Temporal Graph-to-Sequence Learning for Grounded Video Description},
author={Shen, Kai and Wu, Lingfei and Xu, Fangli and Tang, Siliang and Xiao, Jun and Zhuang, Yueting},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI} 2020},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {941--947},
year = {2020}
}
@inproceedings{ijcai2020-419,
title = {RDF-to-Text Generation with Graph-augmented Structural Neural Encoders},
author = {Gao, Hanning and Wu, Lingfei and Hu, Po and Xu, Fangli},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI-20}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {3030--3036},
year = {2020}
}
Equipe Graph4ai: Lingfei Wu (líder da equipe), Yu Chen, Kai Shen, Xiaojie Guo, Hanning Gao, Shucheng Li, Saizhuo Wang, Xiao Liu e Jing Hu. Somos apaixonados no desenvolvimento de bibliotecas úteis de código aberto, que visam promover o fácil uso de várias técnicas de aprendizado profundo em gráficos para o processamento de linguagem natural. Our team consists of research scientists, applied data scientists, and graduate students from a variety of industrial and academic groups, including Pinterest (Lingfei Wu), Zhejiang University (Kai Shen), Facebook AI (Yu Chen), IBM TJ Watson Research Center (Xiaojie Guo), Tongji University (Hanning Gao), Nanjing University (Shucheng Li), HKUST (Saizhuo Wang).
Se você tiver alguma dúvida técnica, envie novos problemas.
Se você tiver outras perguntas, entre em contato conosco: lingfei wu [[email protected]] e xiaojie guo [[email protected]] .
O Graph4NLP usa a Apache License 2.0.


