Grimoire
1.0.0
ภาษาอังกฤษ | 中文简体
เพิ่มขีดความสามารถของแบบจำลองภาษาขนาดเล็กโดยใช้ grimoires
การเรียนรู้ในบริบท (ICL) เป็นหนึ่งในวิธีสำคัญในการเพิ่มประสิทธิภาพของโมเดลภาษาขนาดใหญ่ในงานที่เฉพาะเจาะจงโดยการจัดทำคำถามและคำตอบสองสามชุด อย่างไรก็ตามความสามารถของ ICL ของแบบจำลองประเภทต่าง ๆ แสดงการเปลี่ยนแปลงที่สำคัญเนื่องจากปัจจัยต่าง ๆ เช่นสถาปัตยกรรมแบบจำลองปริมาณข้อมูลการเรียนรู้และขนาดของพารามิเตอร์ โดยทั่วไปขนาดพารามิเตอร์ของโมเดลที่ใหญ่ขึ้นและข้อมูลการเรียนรู้ที่กว้างขวางยิ่งขึ้นความสามารถของ ICL ที่แข็งแกร่งขึ้น ในบทความนี้เราเสนอวิธีการ SLEICL (ICL ที่ได้รับการปรับปรุง LLM ที่แข็งแกร่ง) ที่ involves learning from examples using strong language models and then summarizing and transferring these learned skills to weak language models for inference and application.
สิ่งนี้ทำให้มั่นใจได้ถึงความมั่นคงและประสิทธิผลของ ICL เมื่อเปรียบเทียบกับการเปิดใช้งานแบบจำลองภาษาที่อ่อนแอโดยตรงจากตัวอย่างที่รวดเร็ว SLEICL ช่วยลดความยากลำบากของ ICL สำหรับรุ่นเหล่านี้ การทดลองของเราดำเนินการในชุดข้อมูลสูงสุดแปดชุดด้วยโมเดลภาษาห้าแบบแสดงให้เห็นว่าแบบจำลองภาษาที่อ่อนแอนั้นได้รับการปรับปรุงอย่างสม่ำเสมอเหนือความสามารถของพวกเขาเองหรือไม่สองสามครั้งโดยใช้วิธี SLEICL แบบจำลองภาษาที่อ่อนแอบางรุ่นอาจเกินประสิทธิภาพของ GPT4-1106-PRIEW (Zero-shot) ด้วยความช่วยเหลือของ SLEICL
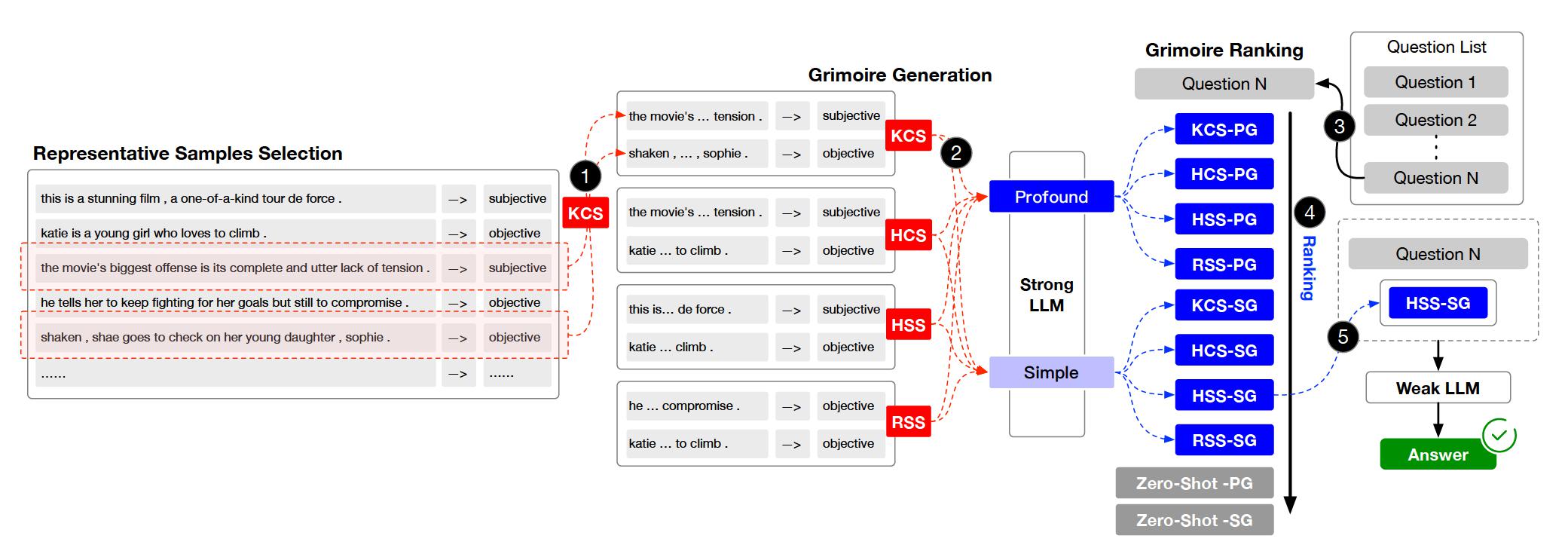
โครงการถูกจัดระเบียบเป็นไดเรกทอรีและโมดูลสำคัญหลายรายการ นี่คือภาพรวมของโครงสร้างโครงการ:
.
├── archived # Store the grimoire and hard samples used in our experiment.
├── assets # Store project assets, such as images, diagrams, or any visual elements used to enhance the presentation and understanding of the project.
├── configs # Store configuration files.
├── core # Core codebase.
│ ├── data # Data processing module.
│ ├── evaluator # Evaluator module.
│ └── llm # Load Large Language Models (LLMs) module.
├── data # Store datasets and data processing scripts.
├── external # Store the Grimoire Ranking model based on the classifier approach.
├── outputs # Store experiment output files.
├── prompts # Store text files used as prompts when interacting with LLMs.
├── stats # Store experiment statistical results.
└── tests # Store test code or unit tests.
โคลนที่เก็บ
git clone https://github.com/IAAR-Shanghai/Grimoire.git && cd Grimoireเตรียมพร้อมสำหรับสภาพแวดล้อม Conda
conda create -n grimoire python=3.8.18conda activate grimoireติดตั้งการพึ่งพา Python และประมวลผลข้อมูล
chmod +x setup.sh./setup.shกำหนดค่า
cp -r ./archived/.cache ./ดูการทดลองพายเพื่อดูวิธีเรียกใช้การทดลอง
เรียกใช้นักวิเคราะห์. py เพื่อวิเคราะห์ผลลัพธ์ที่บันทึกไว้ใน outputs
หมายเหตุ: เกี่ยวกับการปรับใช้ LLMS เรายังมีบทเรียนอ้างอิงบางอย่าง
สำหรับคำถามข้อเสนอแนะหรือคำแนะนำใด ๆ โปรดเปิดปัญหา GitHub คุณสามารถเข้าถึงปัญหา GitHub ได้
setup.sh เพื่อใช้การติดตั้งการพึ่งพา Python และการใช้งานของ embed.py และ compute_similarity.py ; huggingface ; experiment.yaml ; @article{Grimoire,
title={Grimoire is All You Need for Enhancing Large Language Models},
author={Ding Chen and Shichao Song and Qingchen Yu and Zhiyu Li and Wenjin Wang and Feiyu Xiong and Bo Tang},
journal={arXiv preprint arXiv:2401.03385},
year={2024},
}


