Grimoire
1.0.0
Английский | 中文简体
Улучшите возможности малых языковых моделей с использованием гримуаров.
Внутреннее обучение (ICL) является одним из ключевых методов повышения производительности крупных языковых моделей по конкретным задачам путем предоставления набора примеров нескольких выстрелов и ответов. Однако возможность ICL различных типов моделей показывает значительные изменения из -за таких факторов, как архитектура модели, объем данных обучения и размер параметров. Как правило, чем больше размер параметров модели и тем более обширными данными обучения, тем сильнее ее возможность ICL. В этой статье мы предлагаем метод SLEICL (сильный ICL LLM), который involves learning from examples using strong language models and then summarizing and transferring these learned skills to weak language models for inference and application.
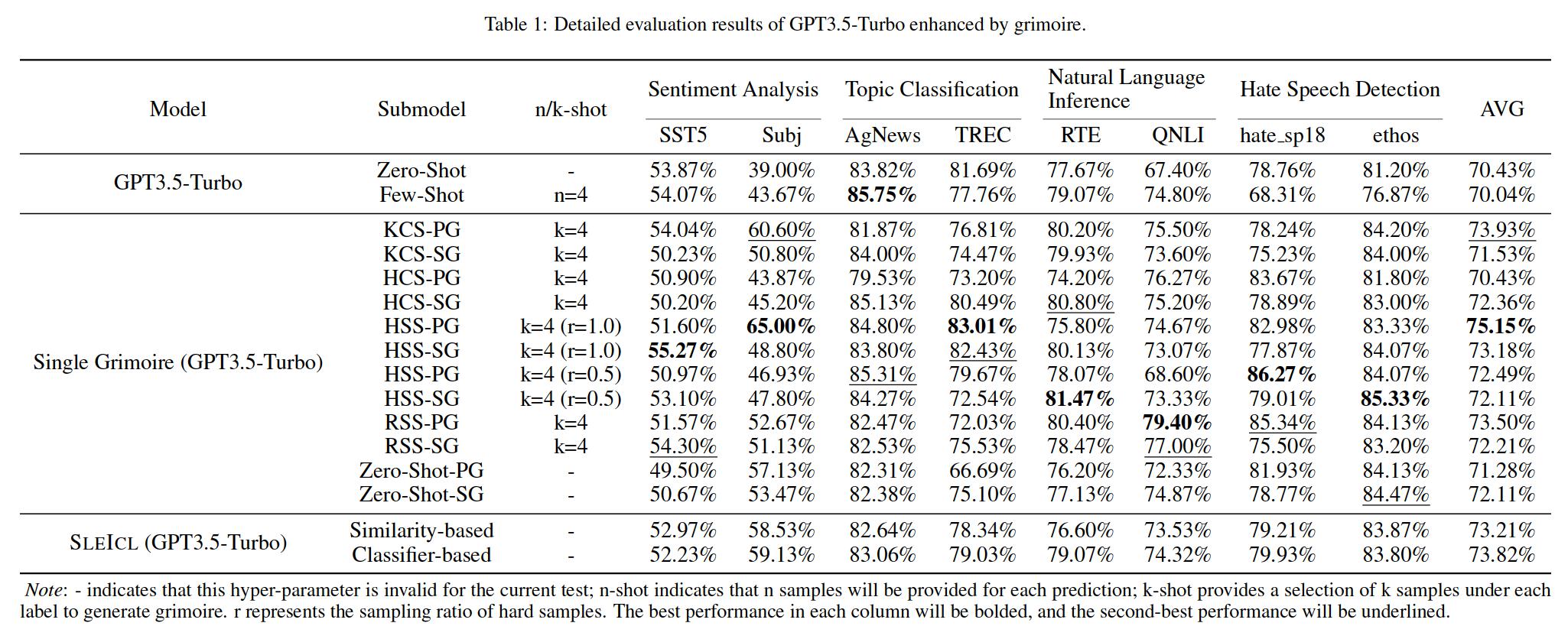
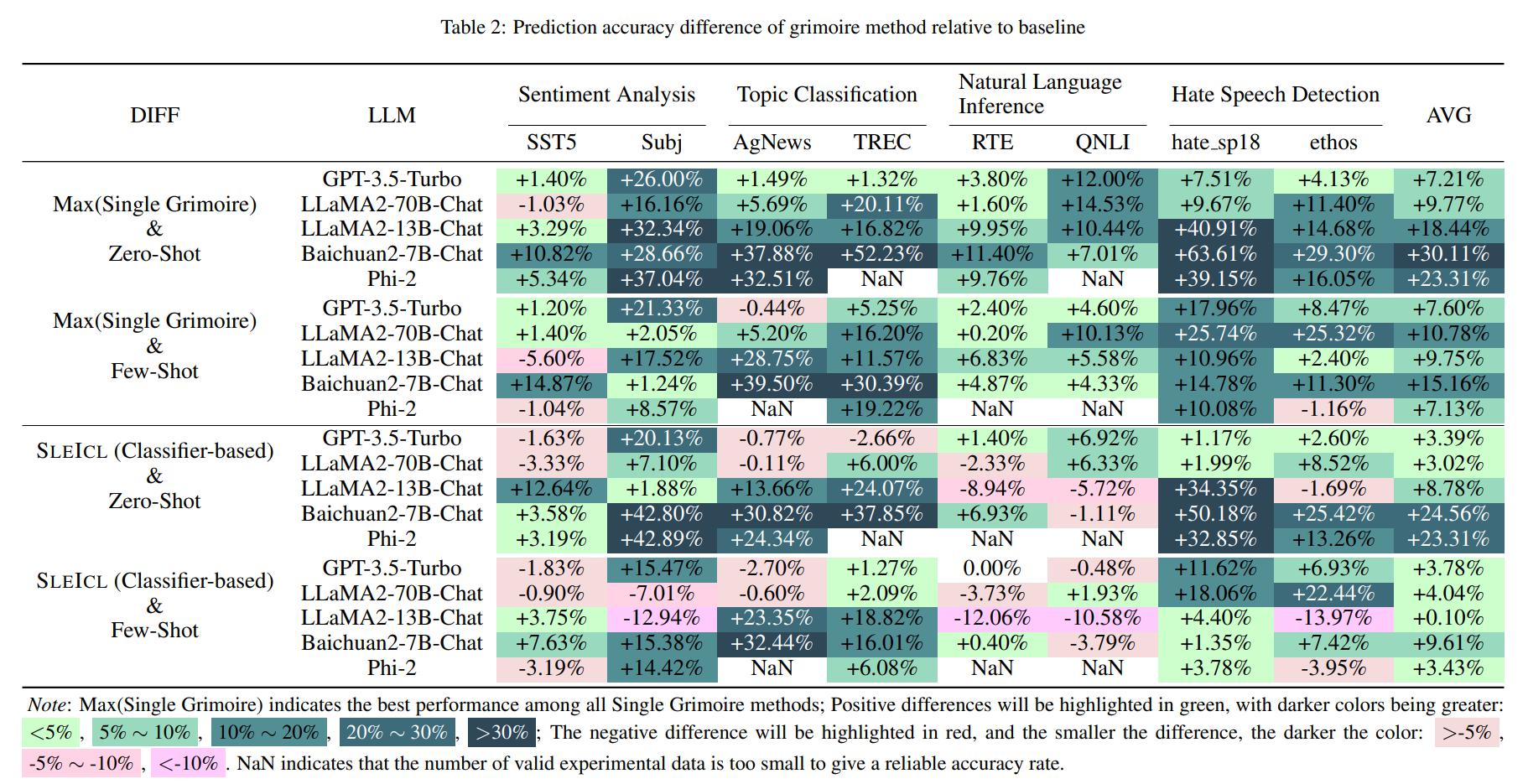
Это обеспечивает стабильность и эффективность ICL. По сравнению с непосредственным позволяет слабым языковым моделям учиться на быстрых примерах, SLEICL уменьшает сложность ICL для этих моделей. Наши эксперименты, проводимые на до восьми наборов данных с пятью языковыми моделями, демонстрируют, что слабые языковые модели достигают последовательного улучшения по сравнению с собственными возможностями с нулевым выстрелом или с несколькими выстрелами, используя метод SLEICL. Некоторые слабые языковые модели даже превосходят производительность GPT4-1106-Preview (Zero-Shot) с помощью SLEICL.
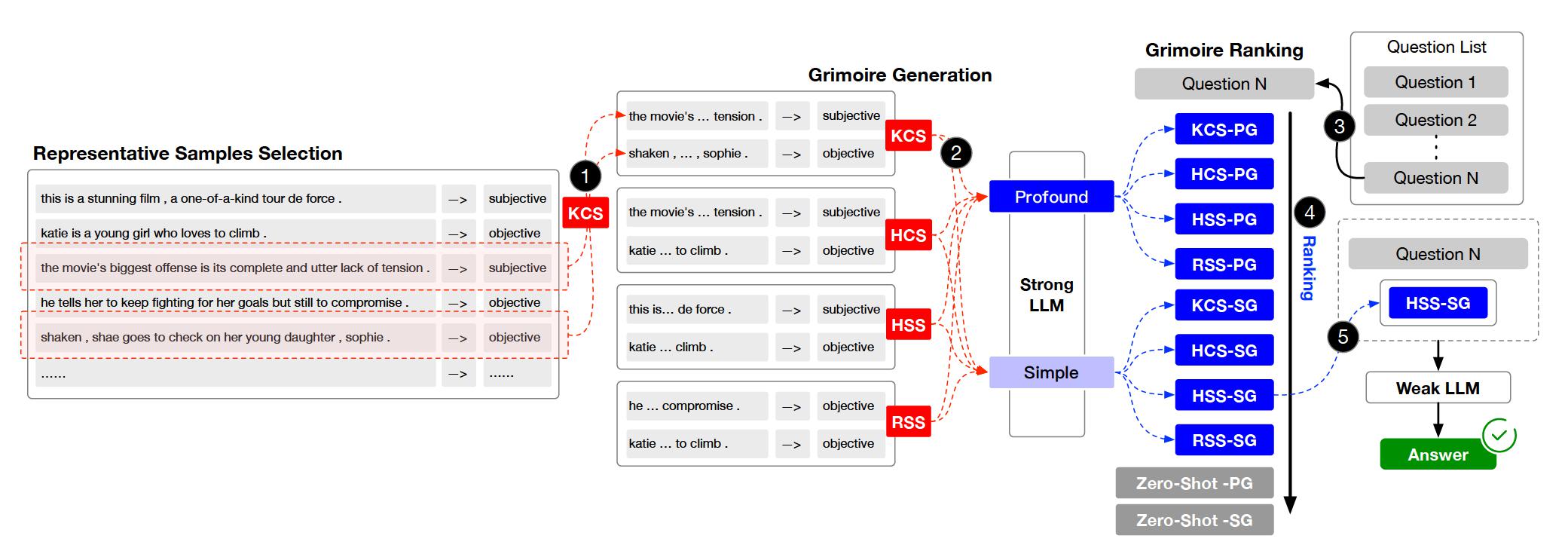
Проект организован в несколько ключевых каталогов и модулей. Вот обзор структуры проекта:
.
├── archived # Store the grimoire and hard samples used in our experiment.
├── assets # Store project assets, such as images, diagrams, or any visual elements used to enhance the presentation and understanding of the project.
├── configs # Store configuration files.
├── core # Core codebase.
│ ├── data # Data processing module.
│ ├── evaluator # Evaluator module.
│ └── llm # Load Large Language Models (LLMs) module.
├── data # Store datasets and data processing scripts.
├── external # Store the Grimoire Ranking model based on the classifier approach.
├── outputs # Store experiment output files.
├── prompts # Store text files used as prompts when interacting with LLMs.
├── stats # Store experiment statistical results.
└── tests # Store test code or unit tests.
Клонировать репозиторий.
git clone https://github.com/IAAR-Shanghai/Grimoire.git && cd GrimoireПодготовьтесь к среде Conda.
conda create -n grimoire python=3.8.18conda activate grimoireУстановите зависимости Python и обработайте данные.
chmod +x setup.sh./setup.shНастройка
cp -r ./archived/.cache ./ .Посмотрите на experiments.py, чтобы увидеть, как проводить эксперименты.
Запустите Analyst.py, чтобы проанализировать результаты, сохраненные в outputs .
Примечание. Что касается развертывания LLMS, мы также предоставляем некоторые справочные учебные пособия.
По любым вопросам, обратной связи или предложениям, пожалуйста, откройте проблему GitHub. Вы можете обратиться через проблемы GitHub.
setup.sh для реализации установки зависимостей Python и реализации embed.py и compute_similarity.py ; huggingface ; experiment.yaml ; @article{Grimoire,
title={Grimoire is All You Need for Enhancing Large Language Models},
author={Ding Chen and Shichao Song and Qingchen Yu and Zhiyu Li and Wenjin Wang and Feiyu Xiong and Bo Tang},
journal={arXiv preprint arXiv:2401.03385},
year={2024},
}


