Grimoire
1.0.0
Inglês | 中文简体
Aprimore os recursos de pequenos modelos de idiomas usando grimóios.
A aprendizagem no contexto (ICL) é um dos principais métodos para melhorar o desempenho de grandes modelos de idiomas em tarefas específicas, fornecendo um conjunto de alguns exemplos de perguntas e respostas. No entanto, a capacidade da ICL de diferentes tipos de modelos mostra variação significativa devido a fatores como arquitetura do modelo, volume de dados de aprendizado e tamanho dos parâmetros. Geralmente, quanto maior o tamanho do parâmetro do modelo e mais extensos os dados de aprendizado, mais forte sua capacidade de ICL. Neste artigo, propomos um Method Sleicl (ICL fortaleced forte LLM) que involves learning from examples using strong language models and then summarizing and transferring these learned skills to weak language models for inference and application.
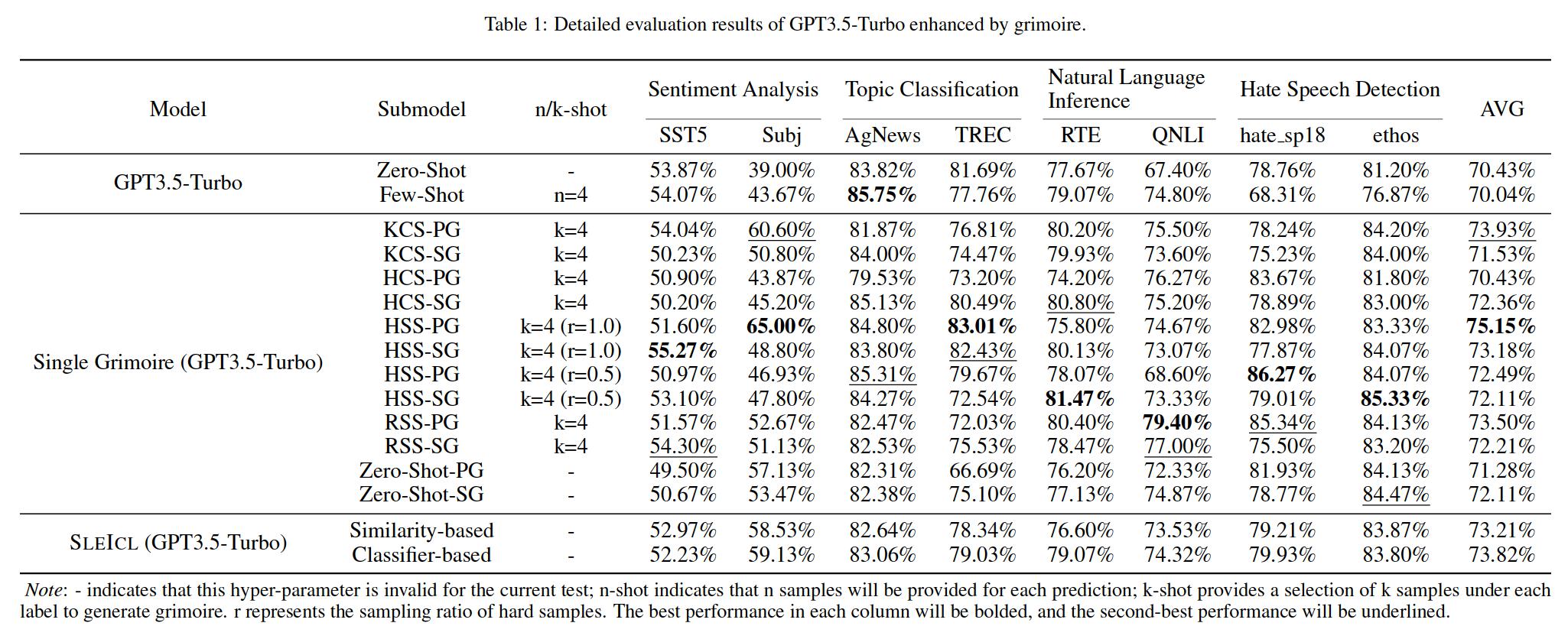
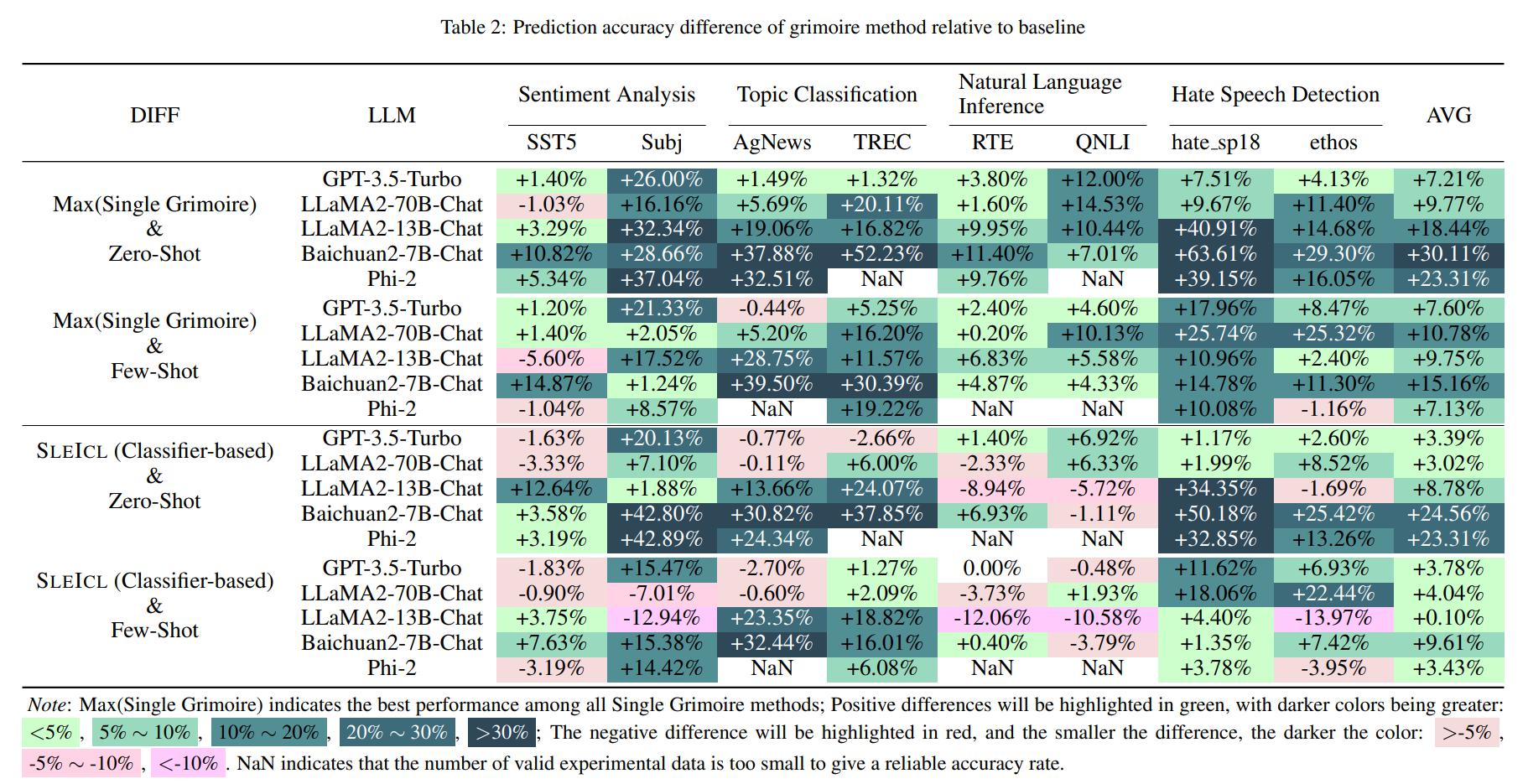
Isso garante a estabilidade e a eficácia da ICL. Comparado com os modelos de linguagem fraca diretamente para aprender com exemplos rápidos, o SLEICL reduz a dificuldade da ICL para esses modelos. Nossos experimentos, realizados em até oito conjuntos de dados com cinco modelos de idiomas, demonstram que os modelos de linguagem fracos alcançam melhorias consistentes em relação aos seus próprios recursos de tiro zero ou poucos anos usando o método Sleicl. Alguns modelos de linguagem fracos até superam o desempenho da pré-visualização GPT4-1106 (zero tiro) com o auxílio do Sleicl.
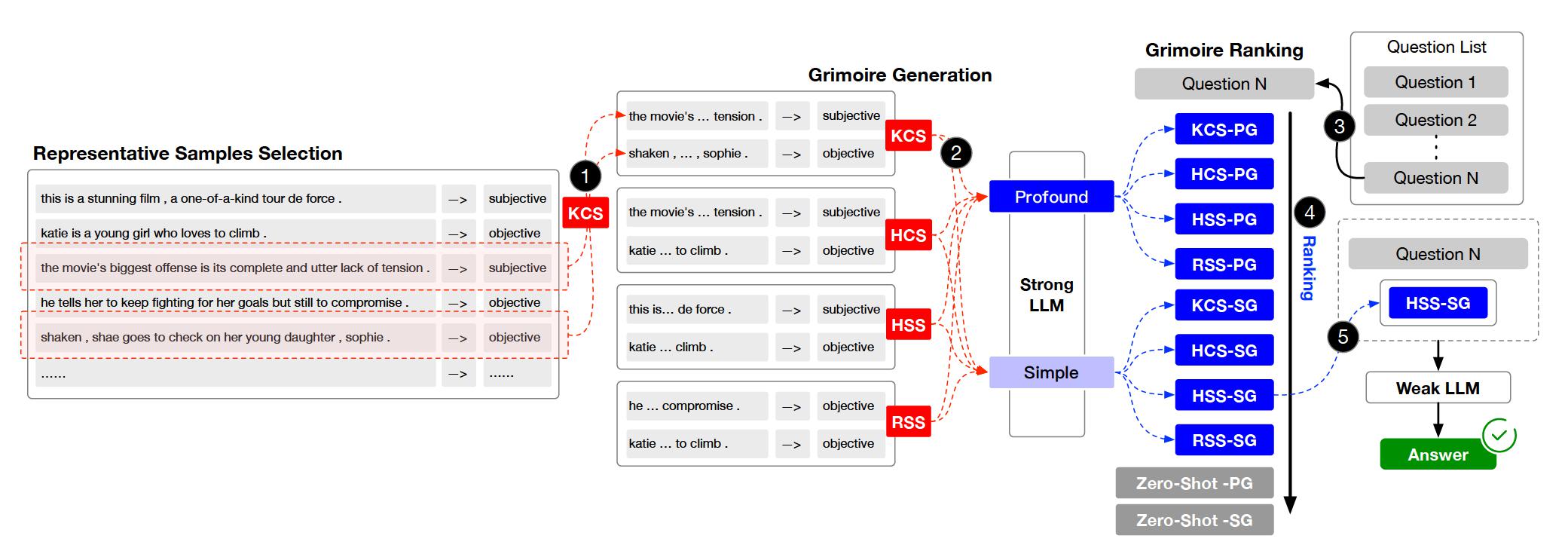
O projeto está organizado em vários diretórios e módulos importantes. Aqui está uma visão geral da estrutura do projeto:
.
├── archived # Store the grimoire and hard samples used in our experiment.
├── assets # Store project assets, such as images, diagrams, or any visual elements used to enhance the presentation and understanding of the project.
├── configs # Store configuration files.
├── core # Core codebase.
│ ├── data # Data processing module.
│ ├── evaluator # Evaluator module.
│ └── llm # Load Large Language Models (LLMs) module.
├── data # Store datasets and data processing scripts.
├── external # Store the Grimoire Ranking model based on the classifier approach.
├── outputs # Store experiment output files.
├── prompts # Store text files used as prompts when interacting with LLMs.
├── stats # Store experiment statistical results.
└── tests # Store test code or unit tests.
Clone o repositório.
git clone https://github.com/IAAR-Shanghai/Grimoire.git && cd GrimoirePrepare -se para o ambiente do conda.
conda create -n grimoire python=3.8.18conda activate grimoireInstale as dependências do Python e processe os dados.
chmod +x setup.sh./setup.shConfigure
cp -r ./archived/.cache ./ .Procure experimentos.py para ver como executar experimentos.
Execute analst.py para analisar os resultados salvos nas outputs .
Nota: Em relação à implantação do LLMS, também fornecemos alguns tutoriais de referência.
Para qualquer dúvida, feedback ou sugestões, abra um problema do GitHub. Você pode alcançar os problemas do GitHub.
setup.sh para implementar a instalação de dependências do Python e a implementação de embed.py e compute_similarity.py ; huggingface ; experiment.yaml ; @article{Grimoire,
title={Grimoire is All You Need for Enhancing Large Language Models},
author={Ding Chen and Shichao Song and Qingchen Yu and Zhiyu Li and Wenjin Wang and Feiyu Xiong and Bo Tang},
journal={arXiv preprint arXiv:2401.03385},
year={2024},
}


