Grimoire
1.0.0
Bahasa Inggris | 中文简体
Tingkatkan kemampuan model bahasa kecil menggunakan grimoires.
In-Context Learning (ICL) adalah salah satu metode utama untuk meningkatkan kinerja model bahasa besar pada tugas-tugas tertentu dengan memberikan satu set beberapa contoh pertanyaan dan jawaban jawaban. Namun, kemampuan ICL dari berbagai jenis model menunjukkan variasi yang signifikan karena faktor -faktor seperti arsitektur model, volume data pembelajaran, dan ukuran parameter. Secara umum, semakin besar ukuran parameter model dan semakin luas data pembelajaran, semakin kuat kemampuan ICL -nya. Dalam makalah ini, kami mengusulkan metode SLEICL (Strong LLM Enhanced ICL) yang involves learning from examples using strong language models and then summarizing and transferring these learned skills to weak language models for inference and application.
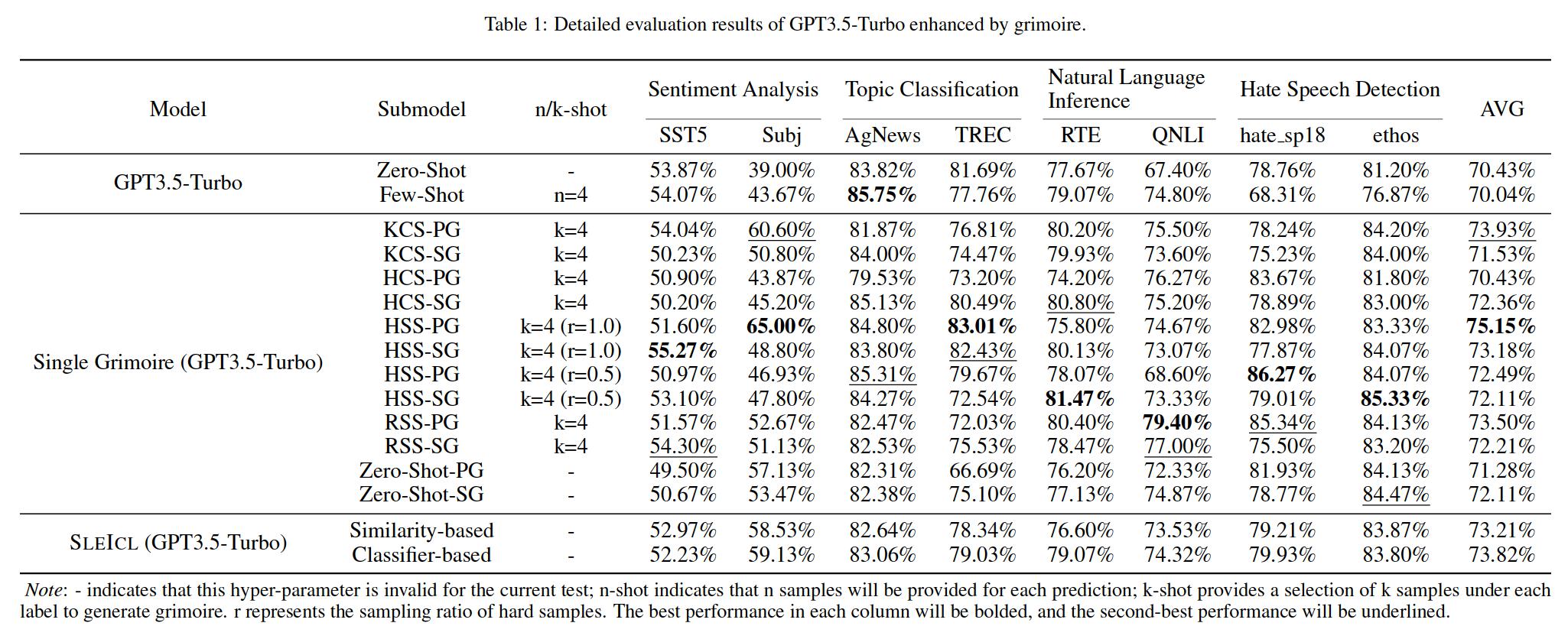
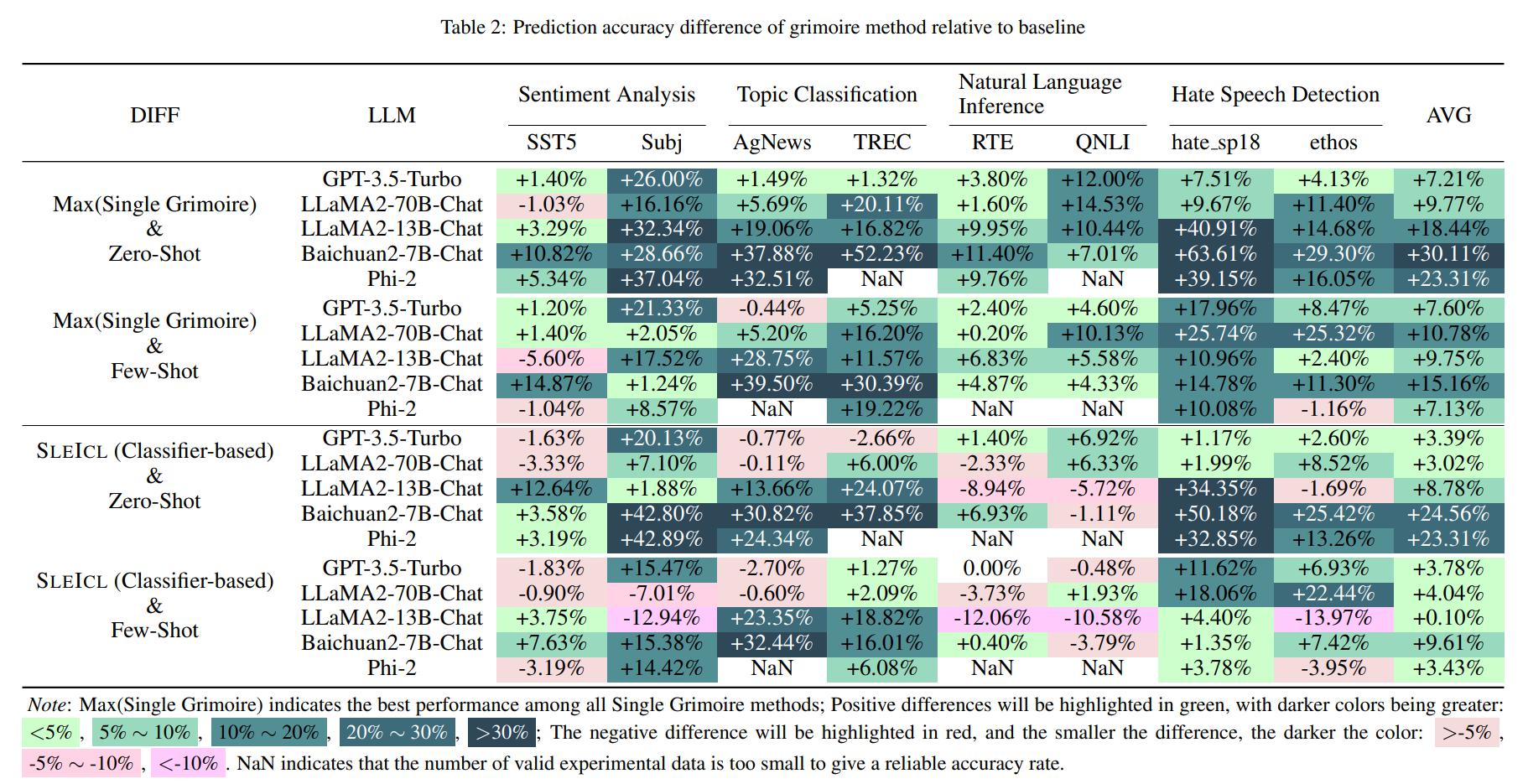
Ini memastikan stabilitas dan efektivitas ICL. Dibandingkan dengan secara langsung memungkinkan model bahasa yang lemah untuk belajar dari contoh cepat, SLEICL mengurangi kesulitan ICL untuk model ini. Eksperimen kami, yang dilakukan pada hingga delapan dataset dengan lima model bahasa, menunjukkan bahwa model bahasa yang lemah mencapai peningkatan yang konsisten dibandingkan kemampuan nol-shot atau beberapa-shot mereka sendiri menggunakan metode SLEICL. Beberapa model bahasa yang lemah bahkan melampaui kinerja GPT4-1106-preview (Zero-shot) dengan bantuan SLEICL.
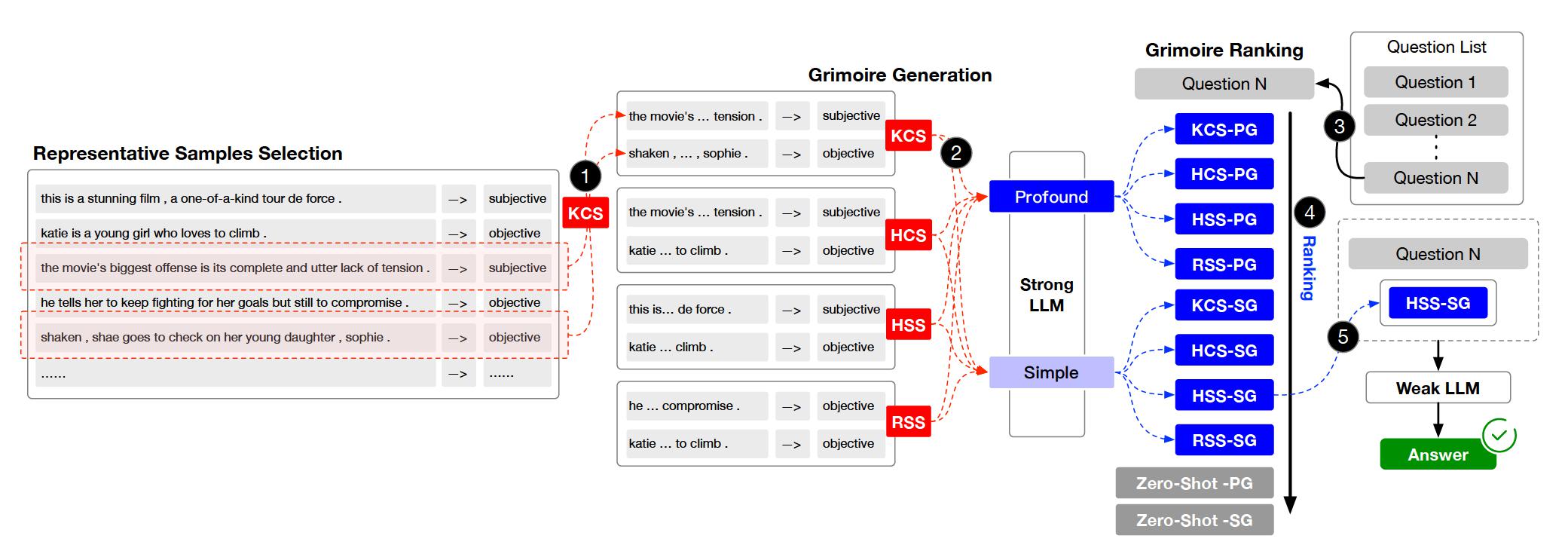
Proyek ini diatur ke dalam beberapa direktori dan modul utama. Berikut gambaran struktur proyek:
.
├── archived # Store the grimoire and hard samples used in our experiment.
├── assets # Store project assets, such as images, diagrams, or any visual elements used to enhance the presentation and understanding of the project.
├── configs # Store configuration files.
├── core # Core codebase.
│ ├── data # Data processing module.
│ ├── evaluator # Evaluator module.
│ └── llm # Load Large Language Models (LLMs) module.
├── data # Store datasets and data processing scripts.
├── external # Store the Grimoire Ranking model based on the classifier approach.
├── outputs # Store experiment output files.
├── prompts # Store text files used as prompts when interacting with LLMs.
├── stats # Store experiment statistical results.
└── tests # Store test code or unit tests.
Klon Repositori.
git clone https://github.com/IAAR-Shanghai/Grimoire.git && cd GrimoireBersiaplah untuk lingkungan Conda.
conda create -n grimoire python=3.8.18conda activate grimoireInstal dependensi Python dan proses data.
chmod +x setup.sh./setup.shKonfigurasikan
cp -r ./archived/.cache ./ .Lihatlah eksperimen.py untuk melihat cara menjalankan eksperimen.
Jalankan Analyst.py untuk menganalisis hasil yang disimpan dalam outputs .
Catatan: Mengenai penyebaran LLMS, kami juga memberikan beberapa tutorial referensi.
Untuk pertanyaan, umpan balik, atau saran apa pun, silakan buka masalah GitHub. Anda dapat menjangkau melalui masalah GitHub.
setup.sh terpadu untuk mengimplementasikan instalasi dependensi Python dan implementasi embed.py dan compute_similarity.py ; huggingface ; experiment.yaml ; @article{Grimoire,
title={Grimoire is All You Need for Enhancing Large Language Models},
author={Ding Chen and Shichao Song and Qingchen Yu and Zhiyu Li and Wenjin Wang and Feiyu Xiong and Bo Tang},
journal={arXiv preprint arXiv:2401.03385},
year={2024},
}


