Grimoire
1.0.0
Inglés | 中文简体
Mejore las capacidades de los modelos de lenguaje pequeños que utilizan Grimorires.
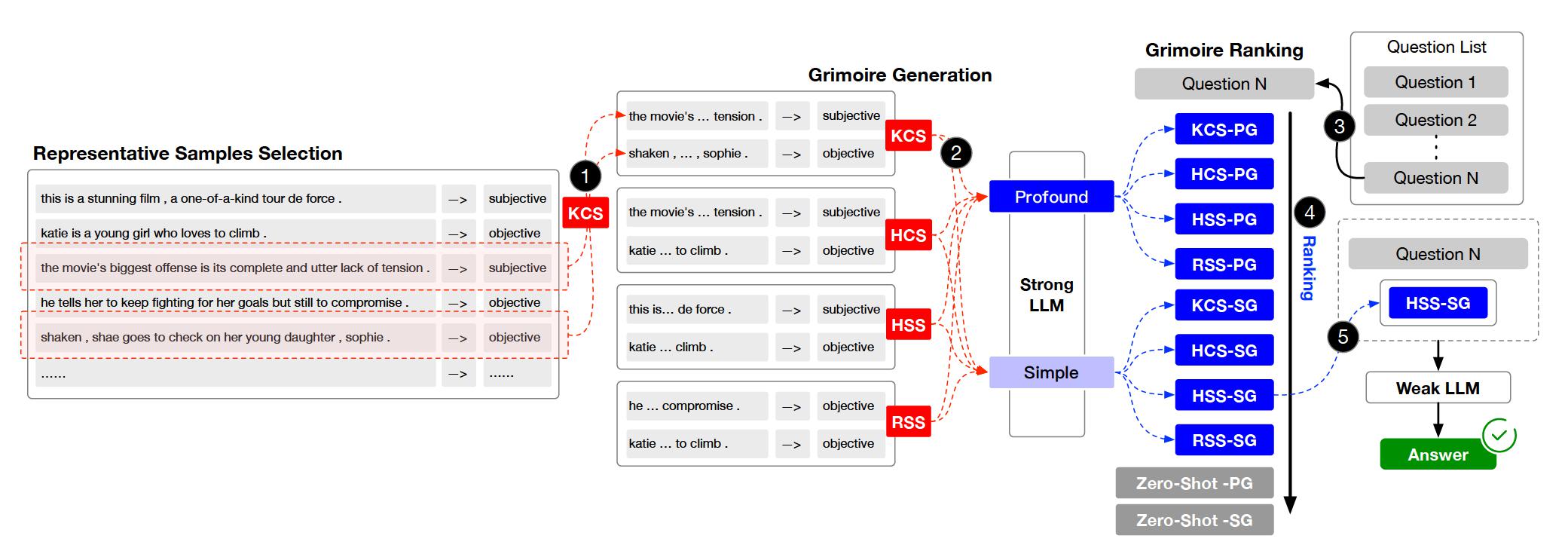
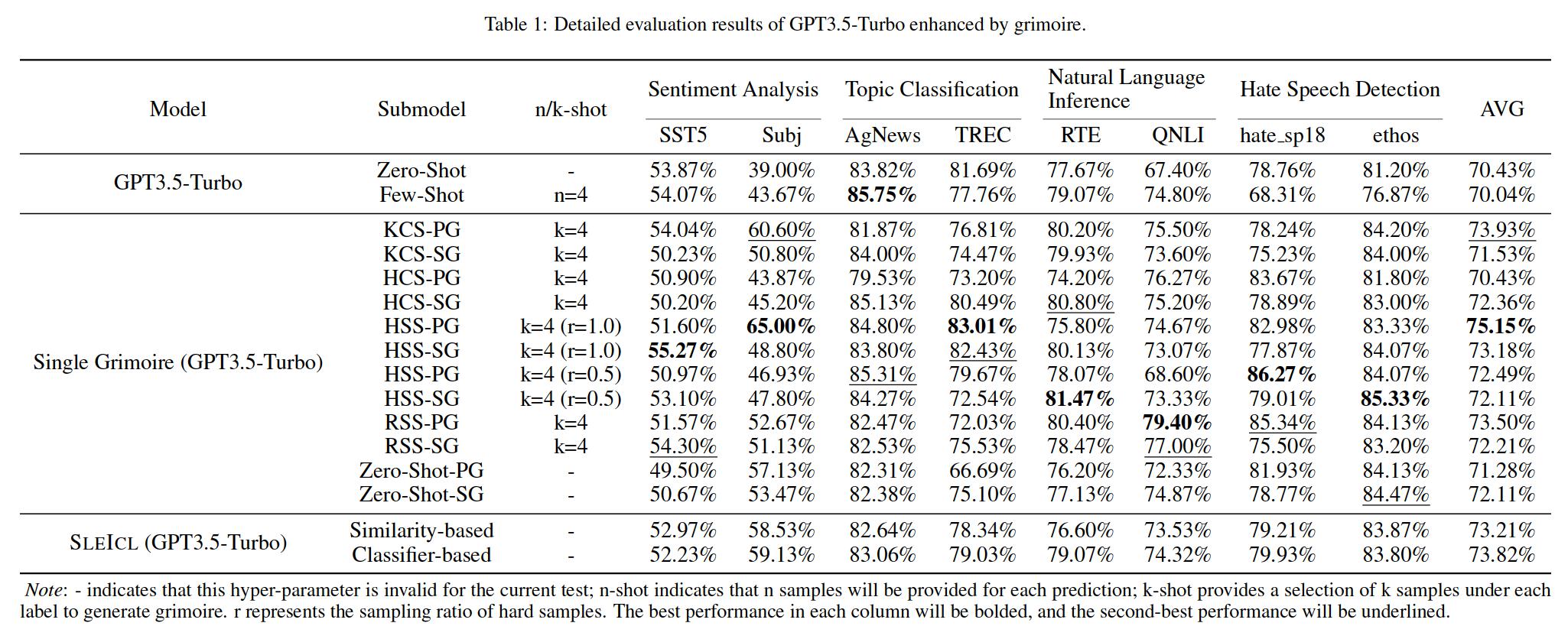
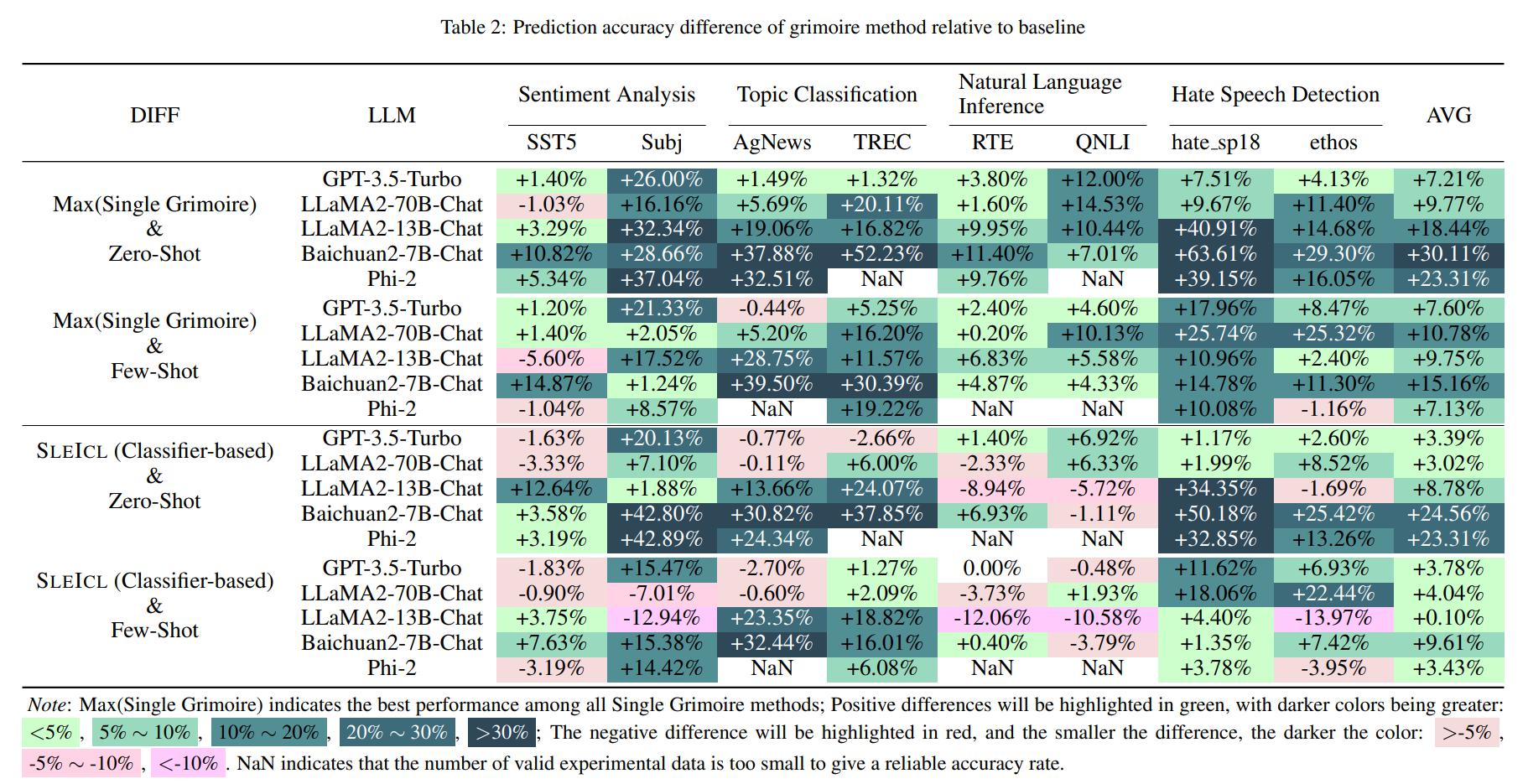
El aprendizaje en contexto (ICL) es uno de los métodos clave para mejorar el rendimiento de los modelos de lenguaje grandes en tareas específicas al proporcionar un conjunto de ejemplos de preguntas y respuestas de pocos disparos. Sin embargo, la capacidad de ICL de diferentes tipos de modelos muestra una variación significativa debido a factores como la arquitectura del modelo, el volumen de datos de aprendizaje y el tamaño de los parámetros. En general, cuanto más grande sea el tamaño del parámetro del modelo y cuanto más extensos sean los datos de aprendizaje, más fuerte será la capacidad de ICL. En este documento, proponemos un Método SLEACL (ICL mejorado de LLM Strong) que involves learning from examples using strong language models and then summarizing and transferring these learned skills to weak language models for inference and application.
Esto garantiza la estabilidad y efectividad de la ICL. En comparación con permitir directamente modelos de lenguaje débiles para aprender de ejemplos de inmediato, SLEACL reduce la dificultad de ICL para estos modelos. Nuestros experimentos, realizados en hasta ocho conjuntos de datos con cinco modelos de lenguaje, demuestran que los modelos de lenguaje débiles logran una mejora constante sobre sus propias capacidades de disparo cero o de pocos disparos utilizando el método SLEACL. Algunos modelos de lenguaje débiles incluso superan el rendimiento de la previa vista GPT4-1106 (cero-shot) con la ayuda de SLEACL.
El proyecto se organiza en varios directorios y módulos clave. Aquí hay una descripción general de la estructura del proyecto:
.
├── archived # Store the grimoire and hard samples used in our experiment.
├── assets # Store project assets, such as images, diagrams, or any visual elements used to enhance the presentation and understanding of the project.
├── configs # Store configuration files.
├── core # Core codebase.
│ ├── data # Data processing module.
│ ├── evaluator # Evaluator module.
│ └── llm # Load Large Language Models (LLMs) module.
├── data # Store datasets and data processing scripts.
├── external # Store the Grimoire Ranking model based on the classifier approach.
├── outputs # Store experiment output files.
├── prompts # Store text files used as prompts when interacting with LLMs.
├── stats # Store experiment statistical results.
└── tests # Store test code or unit tests.
Clon el repositorio.
git clone https://github.com/IAAR-Shanghai/Grimoire.git && cd GrimoirePrepárese para el entorno de conda.
conda create -n grimoire python=3.8.18conda activate grimoireInstale dependencias de Python y procese los datos.
chmod +x setup.sh./setup.shConfigurar
cp -r ./archived/.cache ./ .Busque Experiments.py para ver cómo ejecutar experimentos.
Ejecute Analyst.py para analizar los resultados guardados en outputs .
Nota: Con respecto a la implementación de LLM, también proporcionamos algunos tutoriales de referencia.
Para cualquier pregunta, comentarios o sugerencias, abra un problema de GitHub. Puede llegar a través de problemas de GitHub.
setup.sh para implementar la instalación de dependencias de Python y la implementación de embed.py y compute_similarity.py ; huggingface ; experiment.yaml ; @article{Grimoire,
title={Grimoire is All You Need for Enhancing Large Language Models},
author={Ding Chen and Shichao Song and Qingchen Yu and Zhiyu Li and Wenjin Wang and Feiyu Xiong and Bo Tang},
journal={arXiv preprint arXiv:2401.03385},
year={2024},
}


