Grimoire
1.0.0
Anglais | 中文简体
Améliorez les capacités des modèles de petits langues à l'aide de grimoires.
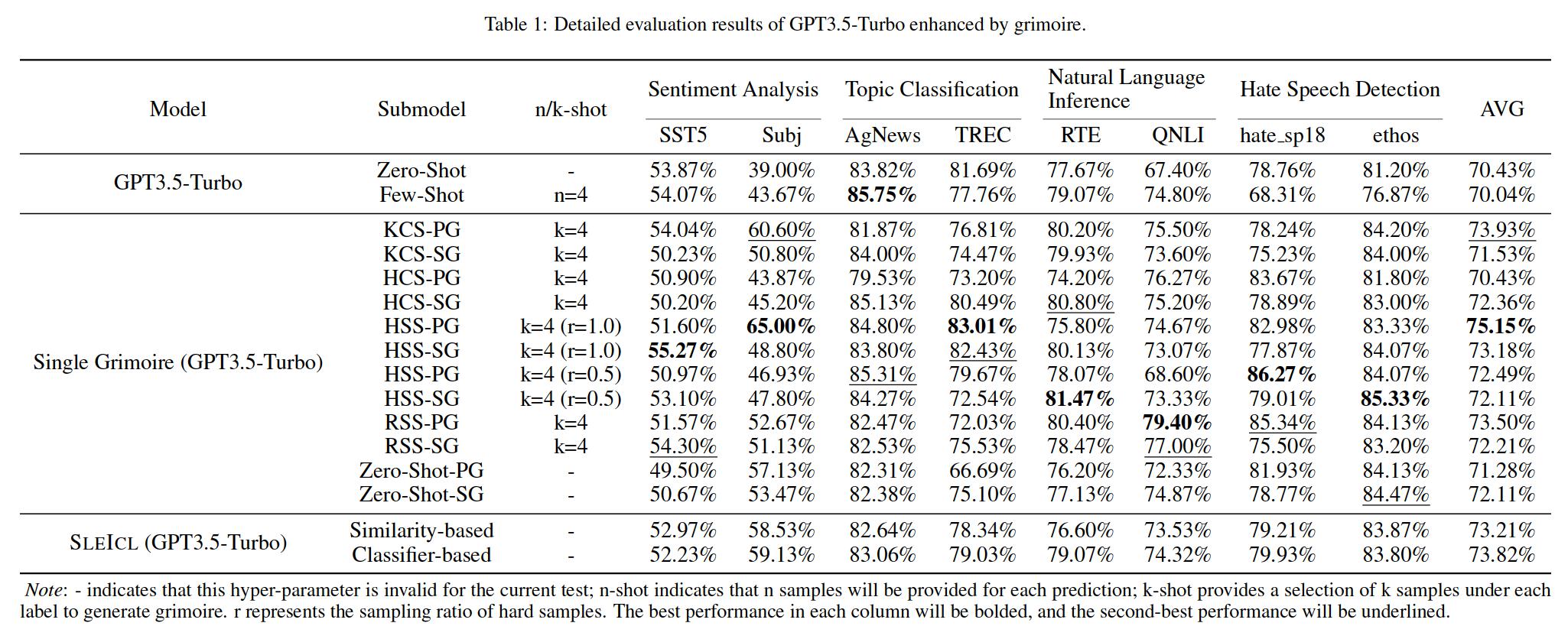
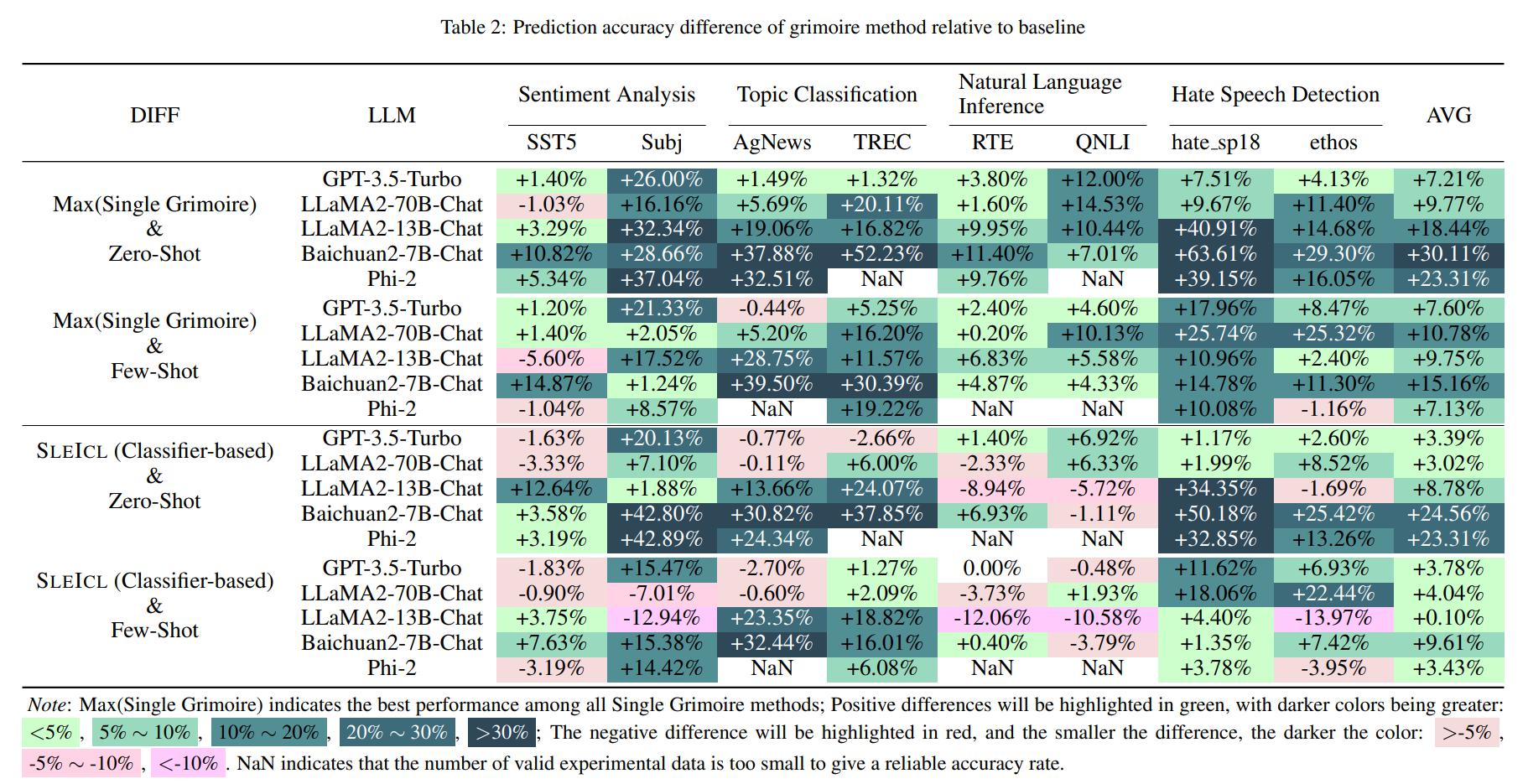
L'apprentissage dans le contexte (ICL) est l'une des méthodes clés pour améliorer les performances de modèles de langue importants sur des tâches spécifiques en fournissant un ensemble d'exemples de questions et réponses à quelques coups. Cependant, la capacité ICL de différents types de modèles montre une variation significative due à des facteurs tels que l'architecture des modèles, le volume des données d'apprentissage et la taille des paramètres. Généralement, plus la taille des paramètres du modèle est grande et plus les données d'apprentissage sont étendues, plus sa capacité ICL est forte. Dans cet article, nous proposons une méthode Sleicl (Strong LLM amélioré ICL) qui involves learning from examples using strong language models and then summarizing and transferring these learned skills to weak language models for inference and application.
Cela garantit la stabilité et l'efficacité de l'ICL. Par rapport à la réduction directe de modèles de langage faibles d'apprendre des exemples rapides, Sleicl réduit la difficulté de l'ICL pour ces modèles. Nos expériences, menées sur jusqu'à huit ensembles de données avec cinq modèles de langage, démontrent que les modèles de langage faibles atteignent une amélioration cohérente par rapport à leurs propres capacités zéro ou à quelques coups en utilisant la méthode Sleicl. Certains modèles de langage faibles dépassent même les performances de GPT4-1106-Preview (zéro-shot) à l'aide de Sleicl.
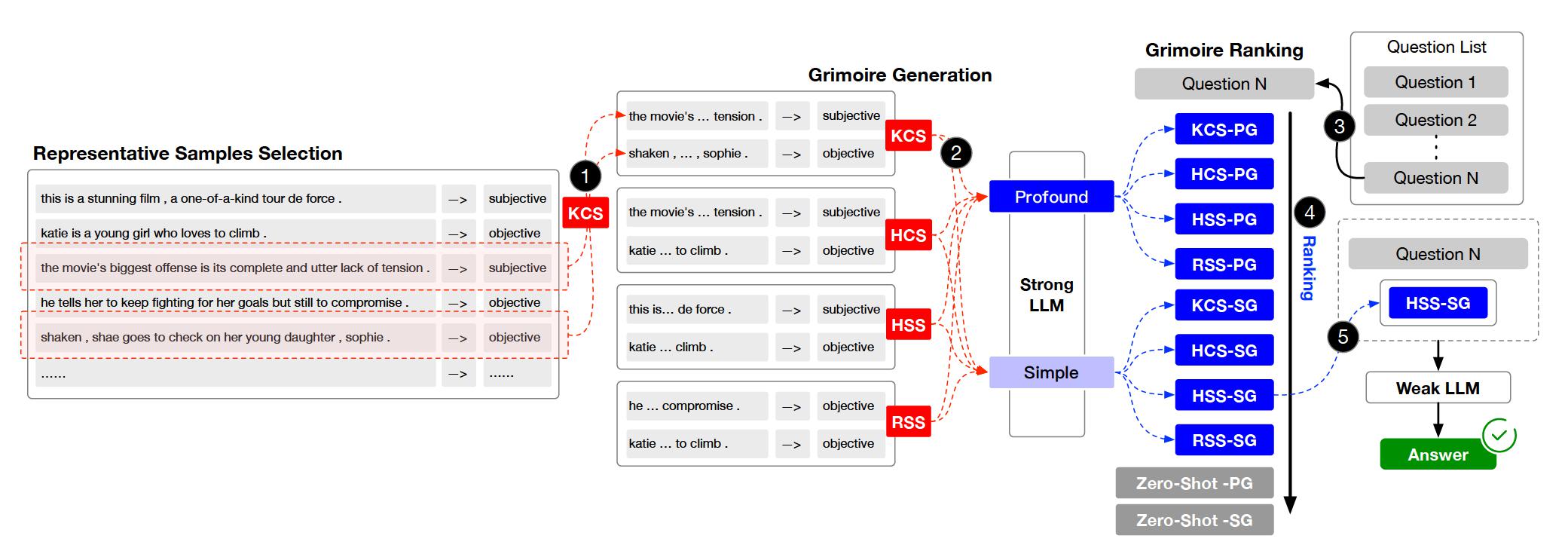
Le projet est organisé en plusieurs répertoires et modules clés. Voici un aperçu de la structure du projet:
.
├── archived # Store the grimoire and hard samples used in our experiment.
├── assets # Store project assets, such as images, diagrams, or any visual elements used to enhance the presentation and understanding of the project.
├── configs # Store configuration files.
├── core # Core codebase.
│ ├── data # Data processing module.
│ ├── evaluator # Evaluator module.
│ └── llm # Load Large Language Models (LLMs) module.
├── data # Store datasets and data processing scripts.
├── external # Store the Grimoire Ranking model based on the classifier approach.
├── outputs # Store experiment output files.
├── prompts # Store text files used as prompts when interacting with LLMs.
├── stats # Store experiment statistical results.
└── tests # Store test code or unit tests.
Clone le référentiel.
git clone https://github.com/IAAR-Shanghai/Grimoire.git && cd GrimoirePréparez-vous à l'environnement Conda.
conda create -n grimoire python=3.8.18conda activate grimoireInstallez les dépendances Python et traitez les données.
chmod +x setup.sh./setup.shConfigurer
cp -r ./archived/.cache ./ .Regardez dans des expériences.py pour voir comment exécuter des expériences.
Exécutez l'analyste.py pour analyser les résultats enregistrés dans outputs .
Remarque: Concernant le déploiement de LLMS, nous fournissons également quelques tutoriels de référence.
Pour toute question, commentaire ou suggestion, veuillez ouvrir un problème de github. Vous pouvez contacter les problèmes de github.
setup.sh unifiée.sh pour implémenter l'installation des dépendances Python et la mise en œuvre d' embed.py et compute_similarity.py ; huggingface ; experiment.yaml ; @article{Grimoire,
title={Grimoire is All You Need for Enhancing Large Language Models},
author={Ding Chen and Shichao Song and Qingchen Yu and Zhiyu Li and Wenjin Wang and Feiyu Xiong and Bo Tang},
journal={arXiv preprint arXiv:2401.03385},
year={2024},
}


