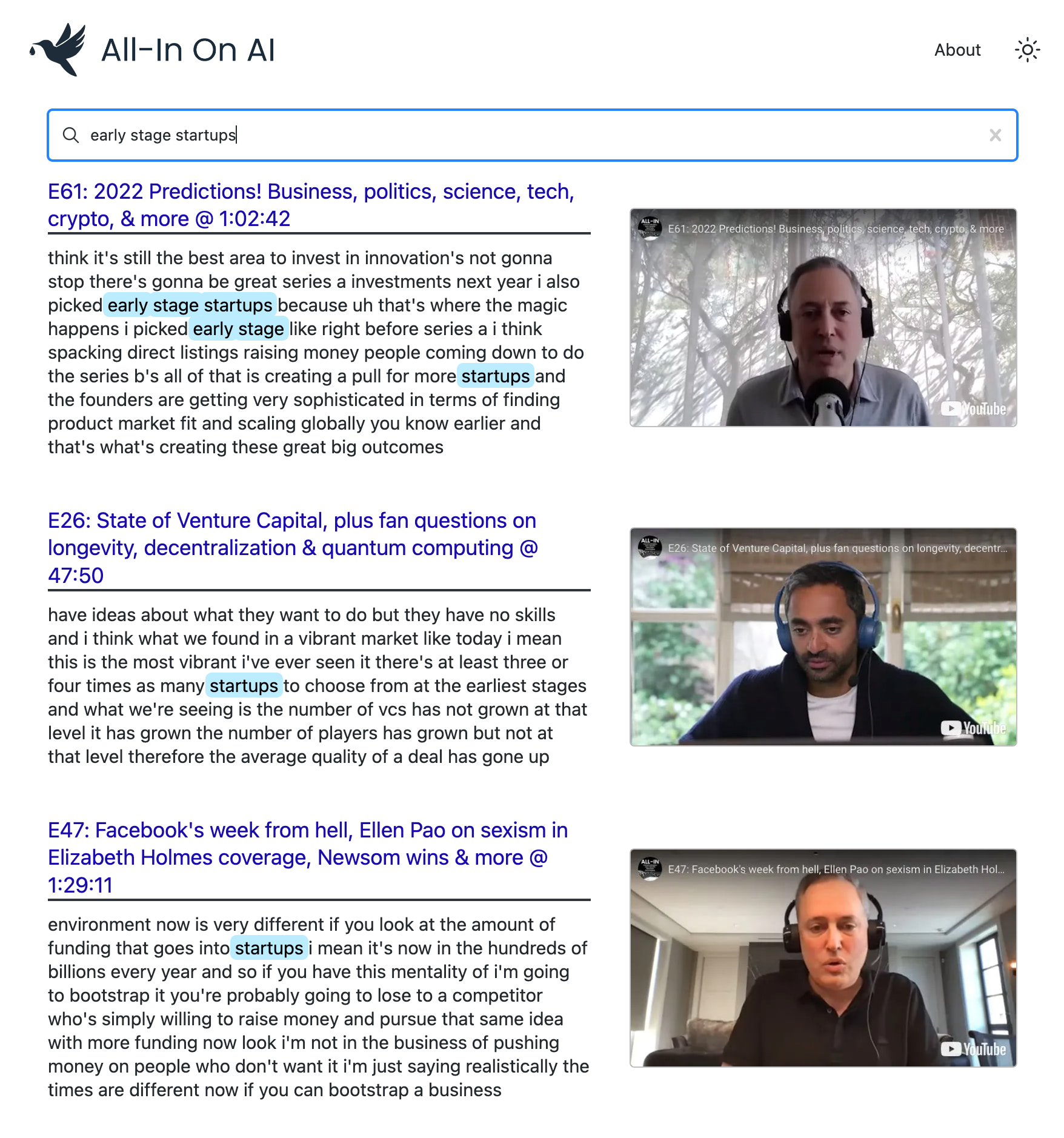
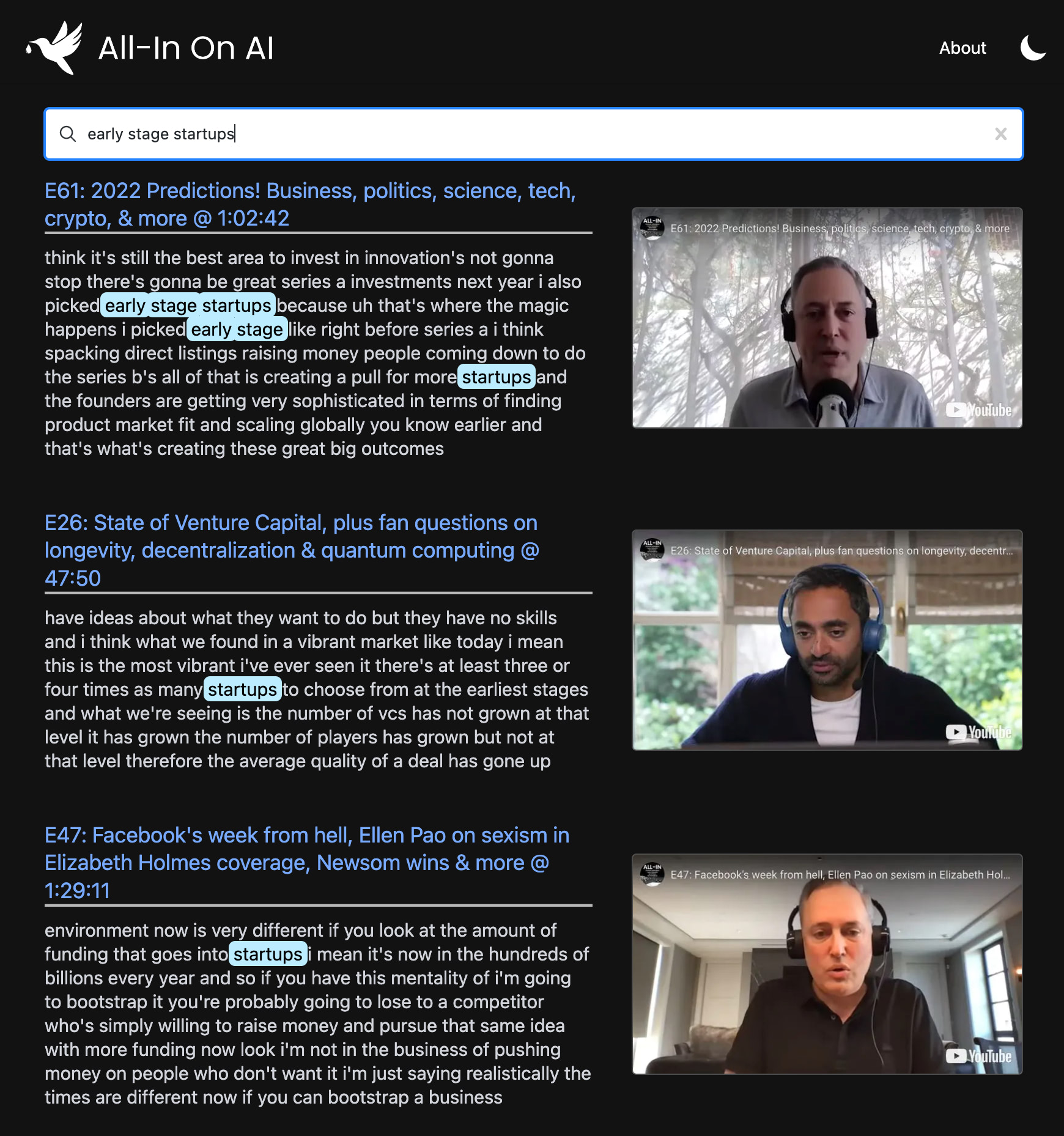
yt semantic search
1.0.0

OpenAi-Powered Semantic Search สำหรับเพลย์ลิสต์ YouTube ใด ๆ-มีพอดคาสต์ All-in
ฉันชอบพอดคาสต์ All-in แต่การค้นหาและการค้นพบด้วยพอดคาสต์อาจเป็นเรื่องที่ท้าทายจริงๆ
ฉันสร้างโครงการนี้เพื่อแก้ปัญหานี้ ... และฉันก็อยากจะเล่นกับสิ่งที่ยอดเยี่ยมของ AI -
โครงการนี้ใช้รุ่นล่าสุดจาก OpenAI เพื่อสร้างดัชนีการค้นหาความหมายในทุกตอนของ POD ช่วยให้คุณค้นหาช่วงเวลาที่คุณชื่นชอบด้วยความแม่นยำระดับ Google และดูคลิปที่แน่นอนที่คุณสนใจอีกครั้ง
คุณสามารถใช้มันเพื่อค้นหาการค้นหาขั้นสูงผ่าน ช่อง YouTube หรือเพลย์ลิสต์ใด ๆ การสาธิตใช้พอดคาสต์ All-in เพราะเป็นที่ชื่นชอบของฉัน แต่มันถูกออกแบบมาเพื่อทำงานกับเพลย์ลิสต์ใด ๆ
npm install เพื่อติดตั้งการพึ่งพาที่จำเป็นทั้งหมดnpx tsx src/bin/resolve-yt-playlist.ts เพื่อดาวน์โหลดการถอดเสียงภาษาอังกฤษสำหรับแต่ละตอนของเพลย์ลิสต์เป้าหมาย (ในกรณีนี้เพลย์ลิสต์พ็อดคาสต์ All-in)npx tsx src/bin/process-yt-playlist.ts เพื่อประมวลผลการถอดเสียงและดึงข้อมูลจาก OpenAI จากนั้นแทรกลงในดัชนีการค้นหา pineconenpx tsx src/bin/query.ts เพื่อสอบถามดัชนีการค้นหา PINECONE (ไม่บังคับ) เรียกใช้คำสั่ง npx tsx src/bin/generate-thumbnails.ts เพื่อสร้างภาพขนาดย่อที่มีการประทับเวลาของวิดีโอแต่ละรายการในเพลย์ลิสต์ ขั้นตอนนี้ใช้เวลา ~ 2 ชั่วโมงและต้องมีการเชื่อมต่ออินเทอร์เน็ตที่มั่นคงโปรดทราบว่าบางตอนอาจไม่มีการถอดความภาษาอังกฤษอัตโนมัติและโครงการใช้วิธีการขูด HTML แบบแฮ็คสำหรับสิ่งนี้ดังนั้นทางออกที่ดีกว่าคือการใช้ Whisper เพื่อถ่ายโอนเสียงของตอน นอกจากนี้โครงการสนับสนุนการเรียงลำดับโดยความสัมพันธ์กับความเกี่ยวข้อง
ภายใต้ประทุนมันใช้:
เราใช้ node.js และ YouTube API V3 เพื่อดึงวิดีโอของเพลย์ลิสต์เป้าหมายของเรา ในกรณีนี้เรามุ่งเน้นไปที่เพลย์ลิสต์ตอนพอดคาสต์ All-in ซึ่งมีวิดีโอ 108 รายการในขณะที่เขียน
npx tsx src/bin/resolve-yt-playlist.tsเราดาวน์โหลดการถอดเสียงภาษาอังกฤษสำหรับแต่ละตอนโดยใช้โซลูชันการขูด HTML HACKY เนื่องจาก YouTube API ไม่อนุญาตให้เข้าถึงคำบรรยายใต้ภาพที่ไม่ได้ใช้ OAUTH โปรดทราบว่าบางตอนไม่มีการถอดความภาษาอังกฤษอัตโนมัติดังนั้นเราจึงข้ามไปในขณะนี้ ทางออกที่ดีกว่าคือการใช้ Whisper เพื่อคัดลอกเสียงของแต่ละตอน
เมื่อเรามีการถอดเสียงทั้งหมดและข้อมูลเมตาดาวน์โหลดในท้องถิ่นเราจะประมวลผลการถอดเสียงของวิดีโอแต่ละรายการก่อนที่จะแบ่งเป็นชิ้นขนาดพอสมควรของโทเค็น ~ 100 และดึงมันเป็น embedding-ADA-002 ที่ฝังตัวจาก Openai ส่งผลให้ ~ 200 embeddings ต่อตอน
การฝังตัวทั้งหมดเหล่านี้จะถูกยกเข้าไปในดัชนีการค้นหา pinecone ที่มีมิติของ 1536 มี ~ 17,575 embeddings รวมทั้งหมด ~ 108 ตอนของพอดคาสต์ All-in
npx tsx src/bin/process-yt-playlist.tsเมื่อตั้งค่าดัชนีการค้นหา pinecone ของเราแล้วเราสามารถเริ่มสอบถามได้ทั้งผ่าน WebApp หรือผ่านตัวอย่าง CLI:
npx tsx src/bin/query.tsนอกจากนี้เรายังสนับสนุนการสร้างภาพขนาดย่อตามเวลาของวิดีโอ YouTube ทุกรายการในเพลย์ลิสต์ รูปขนาดย่อถูกสร้างขึ้นโดยใช้ puppeteer แบบไม่มีส่วนร่วมและอัปโหลดไปยัง Google Cloud Storage นอกจากนี้เรายังโพสต์ประมวลผลภาพขนาดย่อแต่ละรูปแบบด้วย LQIP-Modern เพื่อสร้างภาพตัวยึดตัวอย่างที่ดี
หากคุณต้องการสร้างภาพขนาดย่อ (ไม่บังคับ) ให้เรียกใช้:
npx tsx src/bin/generate-thumbnails.tsโปรดทราบว่าการสร้างภาพขนาดย่อใช้เวลา ~ 2 ชั่วโมงและต้องใช้การเชื่อมต่ออินเทอร์เน็ตที่ค่อนข้างเสถียร
ส่วนหน้าเป็น next.js webapp ที่ปรับใช้กับ Vercel ที่ใช้ดัชนี Pinecone ของเราเป็นที่เก็บข้อมูลหลัก
มีความคิดเกี่ยวกับวิธีการปรับปรุง WebApp นี้หรือไม่? ค้นหาคำค้นหาที่สนุกสนานเป็นพิเศษ?
อย่าลังเลที่จะส่งข้อเสนอแนะให้ฉันไม่ว่าจะเป็น GitHub หรือ Twitter -
MIT © Travis Fischer
หากคุณพบว่าโครงการนี้น่าสนใจโปรดพิจารณาสนับสนุนฉันหรือติดตามฉันทาง Twitter
ค่าใช้จ่าย API และเซิร์ฟเวอร์เพิ่มขึ้นเมื่อเวลาผ่านไปดังนั้นหากคุณสามารถสำรองไว้ได้การสนับสนุนจาก GitHub จะได้รับการชื่นชมอย่างมาก -


