yt semantic search
1.0.0

Recherche sémantique Openai pour toute liste de lecture YouTube - avec le podcast tout-in
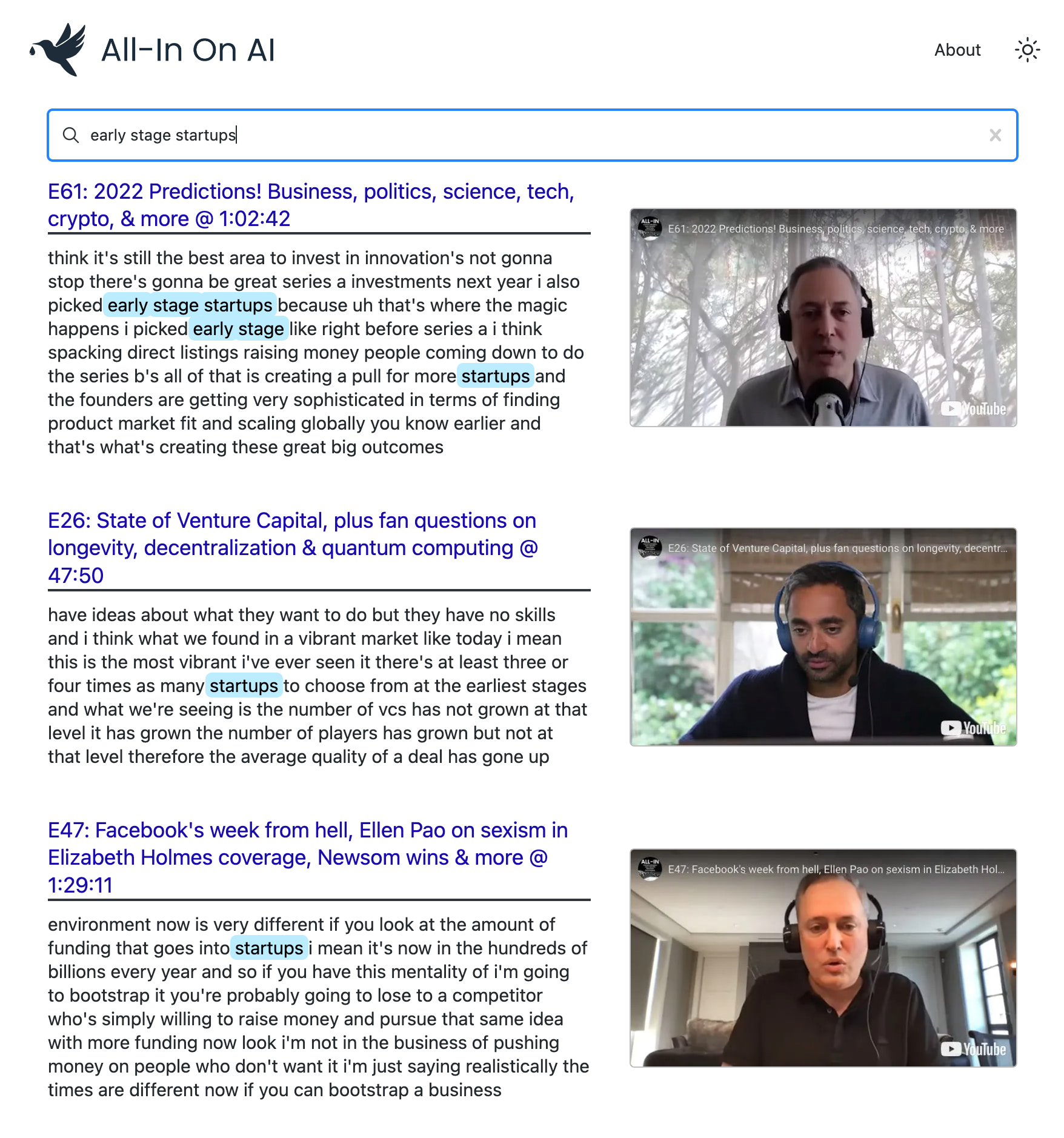
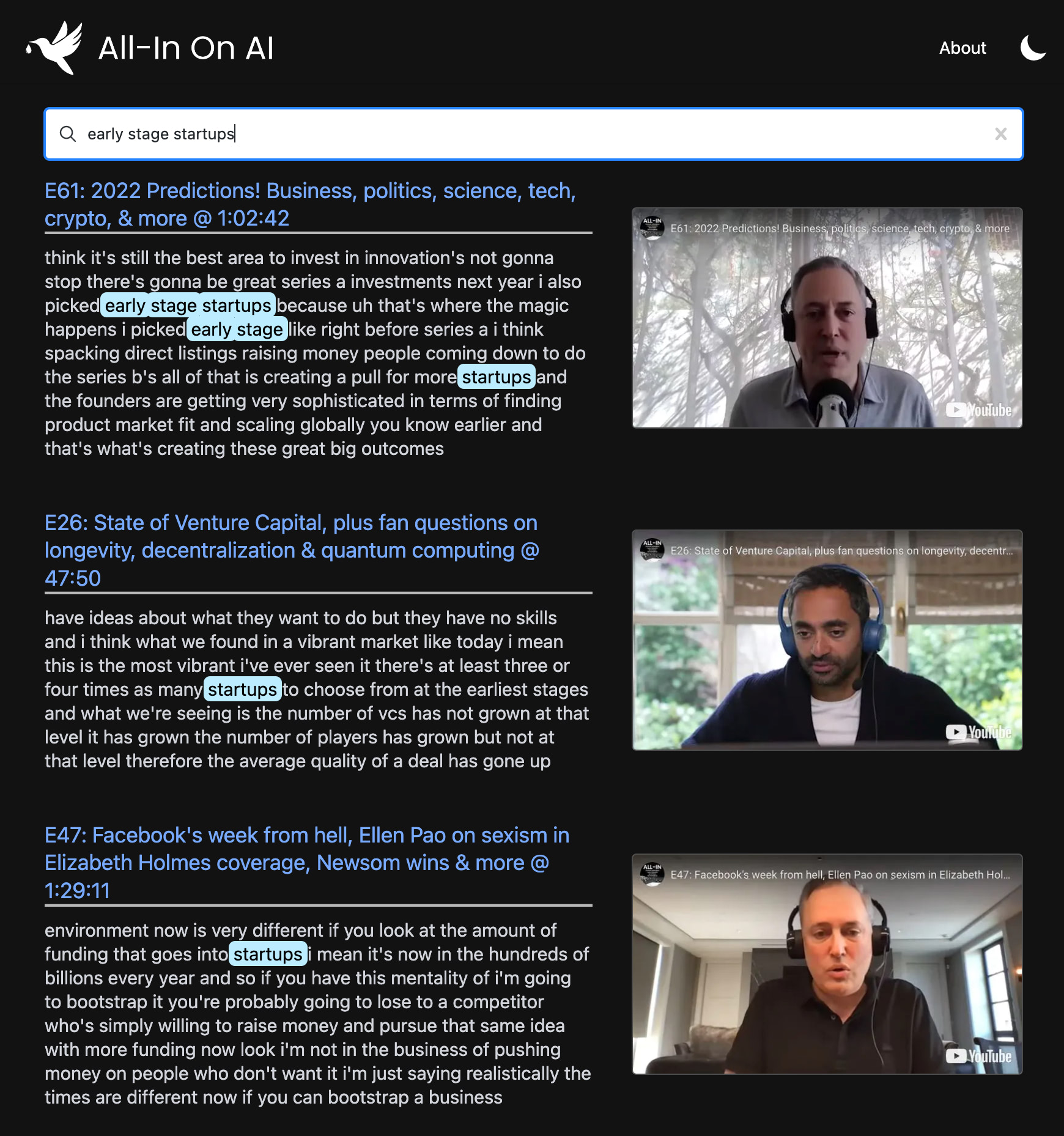
J'adore le podcast tout-in. Mais la recherche et la découverte avec des podcasts peuvent être vraiment difficiles.
J'ai construit ce projet pour résoudre ce problème ... et je voulais aussi jouer avec des trucs IA cool. ?
Ce projet utilise les derniers modèles d'OpenAI pour construire un index de recherche sémantique dans chaque épisode du pod. Il vous permet de trouver vos moments préférés avec une précision de niveau Google et de revoir les clips exacts qui vous intéressent.
Vous pouvez l'utiliser pour alimenter la recherche avancée sur n'importe quelle chaîne ou playlist YouTube . La démo utilise le podcast tout-in parce que c'est mon préféré?, Mais il est conçu pour fonctionner avec n'importe quelle liste de lecture.
npm install pour installer toutes les dépendances nécessaires.npx tsx src/bin/resolve-yt-playlist.ts pour télécharger les transcriptions anglaises pour chaque épisode de la liste de lecture cible (dans ce cas, la playlist des épisodes du podcast tout-in).npx tsx src/bin/process-yt-playlist.ts pour prétraiter les transcriptions et récupérer les incorporations d'OpenAI, puis les insérer dans un index de recherche de pinone.npx tsx src/bin/query.ts pour interroger l'index de recherche de pignon. (Facultatif) Exécutez la commande npx tsx src/bin/generate-thumbnails.ts pour générer des miniatures horodatrices de chaque vidéo de la playlist. Cette étape prend ~ 2 heures et nécessite une connexion Internet stable.Notez que quelques épisodes peuvent ne pas avoir des transcriptions d'anglais automatisées disponibles et que le projet utilise une solution de grattage HTML Hacky pour cela, donc une meilleure solution serait d'utiliser Whisper pour transcrire l'audio de l'épisode. En outre, le tri du projet de tri par récence vs pertinence.
Sous le capot, il utilise:
Nous utilisons Node.js et l'API YouTube V3 pour récupérer les vidéos de notre liste de lecture cible. Dans ce cas, nous sommes concentrés sur la playlist des épisodes du podcast tout-in, qui contient 108 vidéos au moment de la rédaction.
npx tsx src/bin/resolve-yt-playlist.tsNous téléchargeons les transcriptions anglaises pour chaque épisode à l'aide d'une solution de grattage HTML Hacky, car l'API YouTube n'autorise pas l'accès non à l'auteur aux légendes. Notez que quelques épisodes n'ont pas de transcriptions anglaises automatisées disponibles, nous les sautons donc en ce moment. Une meilleure solution serait d'utiliser Whisper pour transcrire l'audio de chaque épisode.
Une fois que nous avons téléchargé tous les transcriptions et métadonnées localement, nous pré-traitons les transcriptions de chaque vidéo, les décomposant en morceaux de taille raisonnable de ~ 100 jetons et récupérez son intégration de texte en termes de texte ADA-002 d'Openai. Il en résulte environ 200 intégres par épisode.
Tous ces intérêts sont ensuite renversés dans un index de recherche de pèce avec une dimensionnalité de 1536. Il y a ~ 17 575 intégres au total dans ~ 108 épisodes du podcast tout-in.
npx tsx src/bin/process-yt-playlist.tsUne fois notre index de recherche de pignon est configuré, nous pouvons commencer à les interroger via le WebApp ou via l'exemple CLI:
npx tsx src/bin/query.tsNous prenons également en charge la génération de vignettes basées sur les horodat de chaque vidéo YouTube dans la playlist. Les vignettes sont générées à l'aide de marionnettiste sans tête et téléchargées sur Google Cloud Storage. Nous post-processus chaque miniature avec LQIP-modern pour générer de belles images d'aperçu d'aperçu.
Si vous souhaitez générer des vignettes (facultatif), exécutez:
npx tsx src/bin/generate-thumbnails.tsNotez que la génération de vignettes prend ~ 2 heures et nécessite une connexion Internet assez stable.
Le frontend est un webApp Next.js déployé sur Vercel qui utilise notre index de pince comme un magasin de données principal.
Vous avez une idée de la façon dont ce WebApp pourrait être amélioré? Vous trouverez une requête de recherche particulièrement amusante?
N'hésitez pas à m'envoyer des commentaires, soit sur GitHub ou Twitter. ?
MIT © Travis Fischer
Si vous avez trouvé ce projet intéressant, envisagez de me parrainer ou de me suivre sur Twitter
L'API et les coûts de serveur s'additionnent au fil du temps, donc si vous pouvez l'épargner, le parrainage sur GitHub est grandement apprécié. ?


