yt semantic search
1.0.0

모든 YouTube 재생 목록에 대한 Openai-Powered Semantic 검색-All-In Podcast가 특징입니다.
나는 All-In Podcast를 좋아합니다. 그러나 팟 캐스트로 검색과 발견은 정말 어려울 수 있습니다.
이 문제를 해결하기 위해이 프로젝트를 구축했습니다. 그리고 나는 또한 멋진 AI와 함께 놀고 싶었습니다. ?
이 프로젝트는 OpenAI의 최신 모델을 사용하여 POD의 모든 에피소드에서 시맨틱 검색 지수를 구축합니다. 이를 통해 Google 레벨 정확도로 좋아하는 순간을 찾고 관심있는 정확한 클립을 다시 볼 수 있습니다.
이를 사용하여 YouTube 채널 또는 재생 목록 에서 고급 검색을 전원으로 전력을 공급할 수 있습니다. 데모는 내가 가장 좋아하는 팟 캐스트를 사용하지만 모든 재생 목록과 함께 작동하도록 설계되었습니다.
npm install 실행하십시오.npx tsx src/bin/resolve-yt-playlist.ts 실행하여 대상 재생 목록의 각 에피소드에 대한 영어 전사물을 다운로드하십시오 (이 경우 All-In Podcast 에피소드 재생 목록).npx tsx src/bin/process-yt-playlist.ts 실행하여 OpenAI에서 전사를 사전 프로세스하고 임베딩을 가져온 다음 Pinecone 검색 인덱스에 삽입하십시오.npx tsx src/bin/query.ts 명령을 실행하여 Pinecone 검색 인덱스를 쿼리 할 수 있습니다. (선택 사항) 명령 npx tsx src/bin/generate-thumbnails.ts 실행하여 재생 목록에서 각 비디오의 타임 스탬프 썸네일을 생성합니다. 이 단계에는 ~ 2 시간이 걸리며 안정적인 인터넷 연결이 필요합니다.몇 가지 에피소드에는 자동화 된 영어 전사가 없을 수 있으며이 프로젝트는이를 위해 해킹 HTML 스크래핑 솔루션을 사용하므로 더 나은 솔루션은 Whisper를 사용하여 에피소드의 오디오를 전사하는 것입니다. 또한, 프로젝트는 Recency vs 관련성에 의한 정렬을 지원합니다.
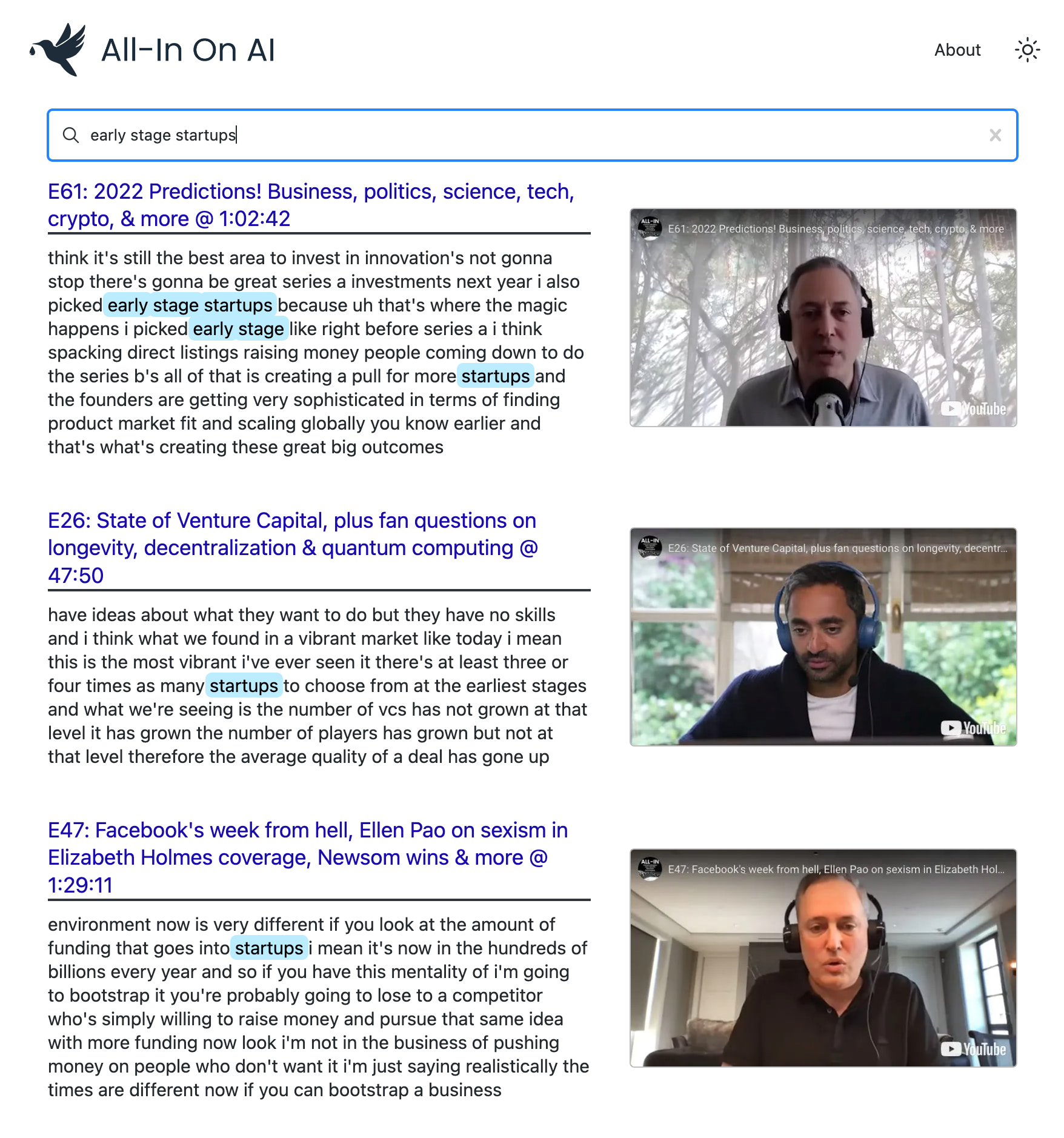
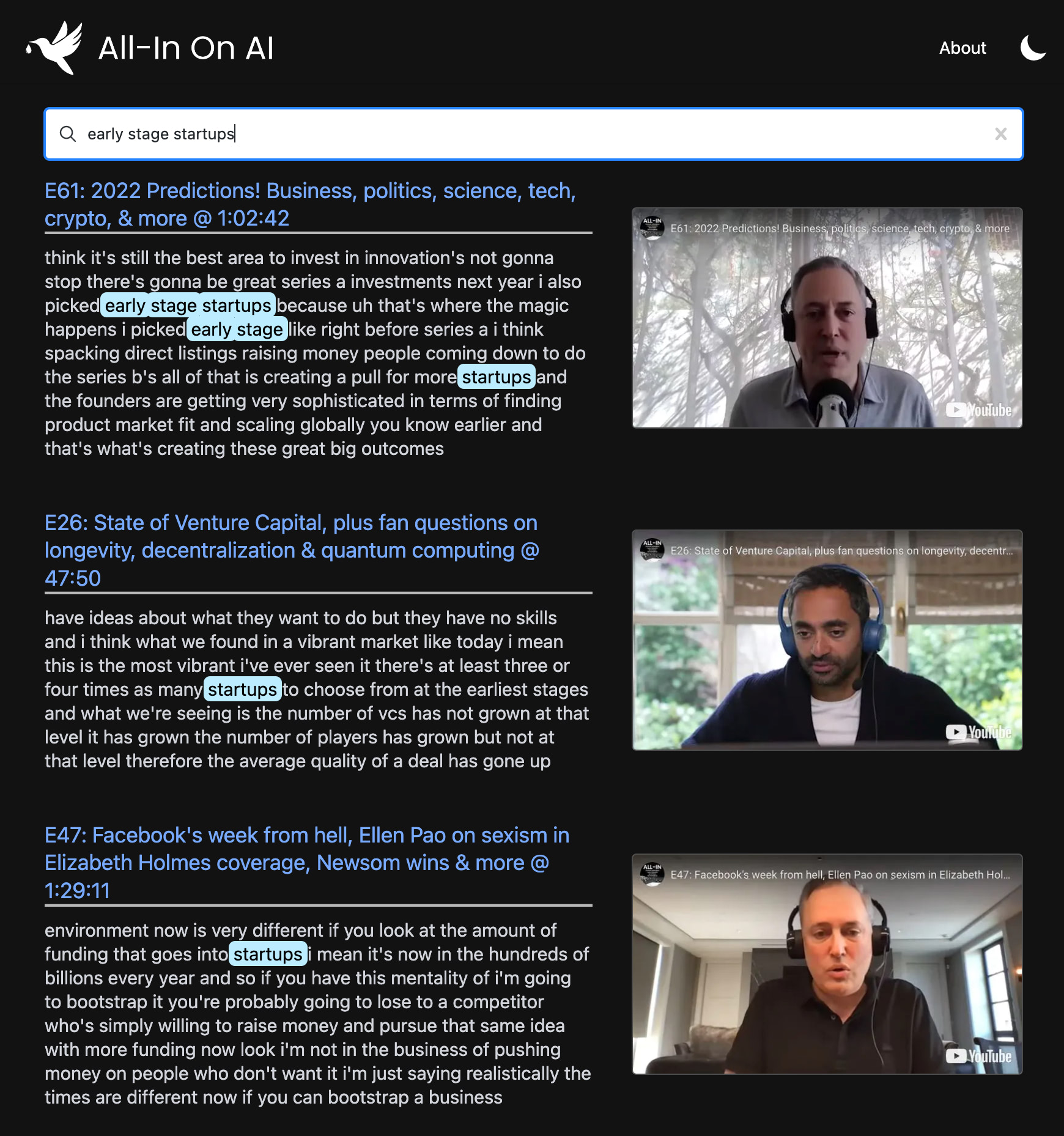
후드 아래에서 사용합니다.
우리는 Node.js와 YouTube API v3을 사용하여 대상 재생 목록의 비디오를 가져옵니다. 이 경우 글을 쓰는 시점에 108 개의 비디오가 포함 된 All-In Podcast 에피소드 재생 목록에 중점을 둡니다.
npx tsx src/bin/resolve-yt-playlist.tsYouTube API는 캡션에 대한 비 OAUTH 액세스를 허용하지 않기 때문에 Hacky HTML 스크래핑 솔루션을 사용하여 각 에피소드에 대한 영어 사본을 다운로드합니다. 몇 가지 에피소드에는 자동화 된 영어 전사가 없으므로 현재까지 건너 뛰고 있습니다. 더 나은 솔루션은 Whisper를 사용하여 각 에피소드의 오디오를 전사하는 것입니다.
모든 전사와 메타 데이터를 로컬로 다운로드 한 후에는 각 비디오의 전사를 사전 처리하여 ~ 100 개의 토큰의 합리적인 크기의 덩어리로 나누고 OpenAI에서 텍스트에 포함 된 텍스트에 포함됩니다. 이로 인해 에피소드 당 ~ 200 개의 임베드가 발생합니다.
그런 다음이 모든 임베딩은 1536 년의 치수가 1536의 파인 콘 검색 인덱스로 화를냅니다. All-in Podcast의 ~ 108 에피소드에 걸쳐 총 17,575 개의 임베드가 있습니다.
npx tsx src/bin/process-yt-playlist.tsPinecone 검색 색인이 설정되면 WebApp 또는 예제 CLI를 통해 쿼리를 시작할 수 있습니다.
npx tsx src/bin/query.ts또한 재생 목록에서 모든 YouTube 비디오의 타임 스탬프 기반 썸네일 생성을 지원합니다. 썸네일은 헤드리스 인형극을 사용하여 생성되며 Google Cloud Storage에 업로드됩니다. 우리는 또한 LQIP- 모더니즘으로 각 썸네일을 사후 처리하여 멋진 미리보기 자리 표시 자 이미지를 생성합니다.
썸네일 (선택 사항)을 생성하려면 실행하십시오.
npx tsx src/bin/generate-thumbnails.ts썸네일 생성에는 ~ 2 시간이 걸리며 매우 안정적인 인터넷 연결이 필요합니다.
Frontend는 Pinecone Index를 기본 데이터 저장소로 사용하는 Vercel에 배포 된 Next.js WebApp입니다.
이 WebApp이 어떻게 개선 될 수 있는지에 대한 아이디어가 있습니까? 특히 재미있는 검색 쿼리를 찾으십니까?
Github 또는 Twitter에서 의견을 보내 주시기 바랍니다. ?
MIT © Travis Fischer
이 프로젝트가 흥미로워지면 저를 후원하거나 트위터에서 나를 팔로우하십시오.
API 및 서버 비용은 시간이 지남에 따라 추가되므로 여유가 있으면 GitHub의 후원에 큰 감사를 표합니다. ?


