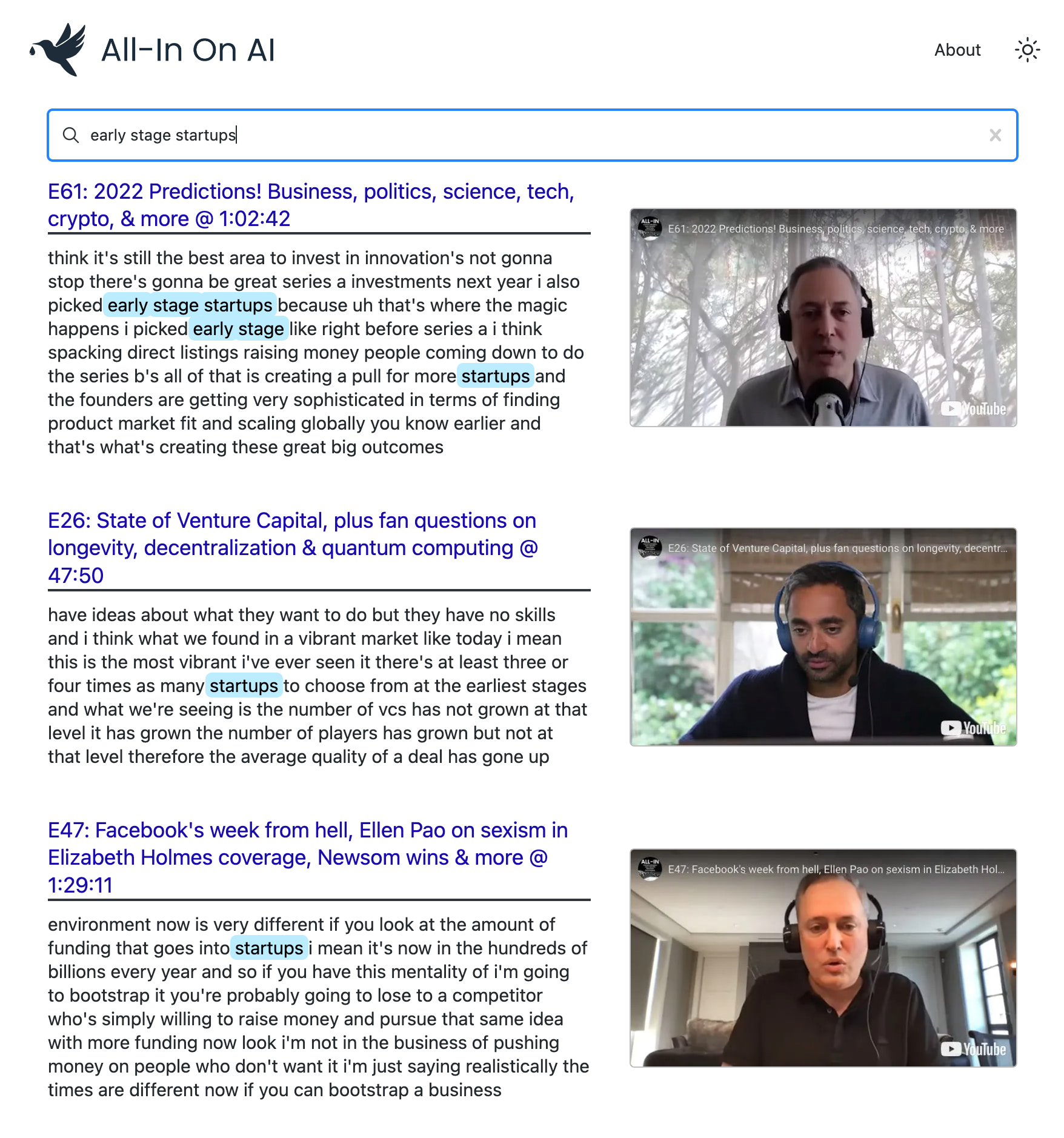
yt semantic search
1.0.0

Pesquisa semântica de OpenAI por qualquer lista de reprodução do YouTube-com o podcast All-In
Eu amo o podcast All-In. Mas a pesquisa e a descoberta com podcasts podem ser realmente desafiadores.
Eu construí este projeto para resolver esse problema ... e também queria brincar com coisas legais de IA. ?
Este projeto usa os modelos mais recentes do OpenAI para criar um índice de pesquisa semântica em todos os episódios do POD. Ele permite que você encontre seus momentos favoritos com precisão no nível do Google e revesse os clipes exatos em que você está interessado.
Você pode usá -lo para alimentar a pesquisa avançada em qualquer canal ou lista de reprodução do YouTube . A demonstração usa o podcast All-In porque é o meu favorito?, Mas foi projetado para funcionar com qualquer lista de reprodução.
npm install para instalar todas as dependências necessárias.npx tsx src/bin/resolve-yt-playlist.ts para baixar as transcrições em inglês para cada episódio da lista de reprodução de destino (neste caso, a lista de reprodução de episódios de podcast All-in).npx tsx src/bin/process-yt-playlist.ts para pré-processo as transcrições e buscar incorporações do OpenAI e insira-as em um índice de pesquisa de pinecone.npx tsx src/bin/query.ts para consultar o índice de pesquisa do Pinecone. (Opcional) Execute o comando npx tsx src/bin/generate-thumbnails.ts para gerar miniaturas de registro de data e hora de cada vídeo na lista de reprodução. Esta etapa leva ~ 2 horas e requer uma conexão estável à Internet.Observe que alguns episódios podem não ter transcrições automatizadas em inglês disponíveis e que o projeto usa uma solução de raspagem HTML hacky para isso, portanto, uma solução melhor seria usar o Whisper para transcrever o áudio do episódio. Além disso, o suporte de suporte do projeto por Recência versus relevância.
Sob o capô, ele usa:
Usamos o Node.js e a API V3 do YouTube para buscar os vídeos da nossa lista de reprodução de destino. Nesse caso, estamos focados na lista de reprodução de episódios de podcast All-in, que contém 108 vídeos no momento da redação.
npx tsx src/bin/resolve-yt-playlist.tsFazemos o download das transcrições em inglês para cada episódio usando uma solução de raspagem HTML Hacky, pois a API do YouTube não permite acesso a não OAuth às legendas. Observe que alguns episódios não têm transcrições automatizadas em inglês disponíveis, então estamos apenas pulando -os no momento. Uma solução melhor seria usar o Whisper para transcrever o áudio de cada episódio.
Depois que todas as transcrições e metadados baixados localmente, pré-processamos as transcrições de cada vídeo, dividindo-as em pedaços de tamanho razoavelmente de ~ 100 tokens e buscando sua incorporação de texto-Ada-002 do OpenAi. Isso resulta em ~ 200 incorporações por episódio.
Todas essas incorporações são posteriores a um índice de pesquisa de Pinecone com uma dimensionalidade de 1536. Existem ~ 17.575 incorporações no total em ~ 108 episódios do podcast All-In.
npx tsx src/bin/process-yt-playlist.tsDepois que nosso Índice de Pesquisa Pinecone estiver configurado, podemos começar a consultá -lo através do WebApp ou através do exemplo da CLI:
npx tsx src/bin/query.tsTambém apoiamos a geração de miniaturas baseadas em registro de data e hora de todos os vídeos do YouTube na lista de reprodução. As miniaturas são geradas usando marionetas sem cabeça e são carregadas no Google Cloud Storage. Também pós-processo de cada miniatura com o LQIP-Modern para gerar imagens de espaço reservado para visualização agradável.
Se você deseja gerar miniaturas (opcional), execute:
npx tsx src/bin/generate-thumbnails.tsObserve que a geração de miniaturas leva ~ 2 horas e requer uma conexão de internet bastante estável.
O Frontend é um Afffort.js WebApp implantado no VERCEL que usa nosso índice Pinecone como um armazenamento de dados primário.
Tem uma idéia de como esse webApp poderia ser melhorado? Encontrar uma consulta de pesquisa particularmente divertida?
Sinta -se à vontade para me enviar feedback, no Github ou no Twitter. ?
MIT © Travis Fischer
Se você achou este projeto interessante, considere me patrocinar ou me seguir no Twitter
Os custos da API e do servidor aumentam com o tempo; portanto, se você pode poupar, patrocinar no Github será muito apreciado. ?


