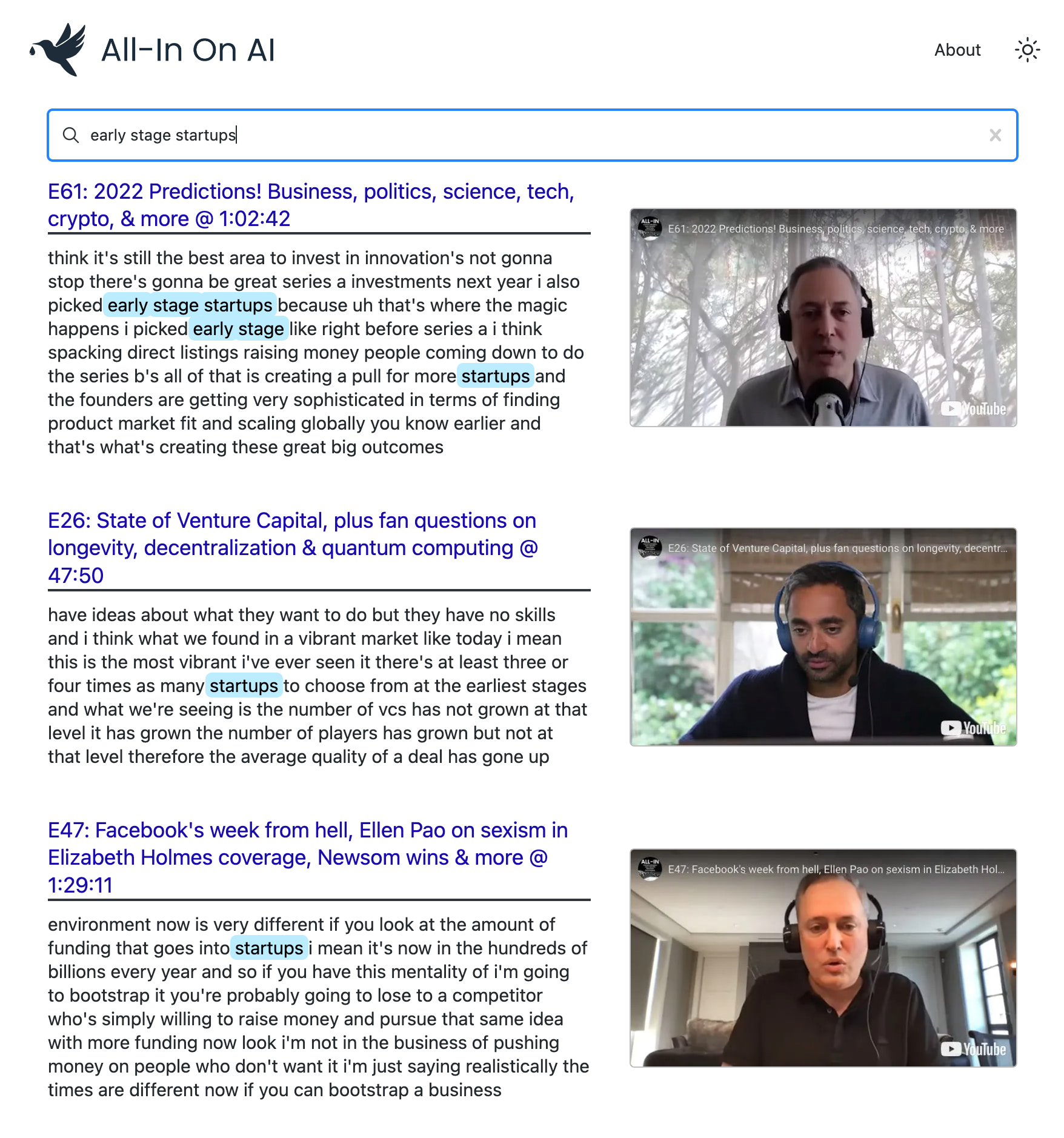
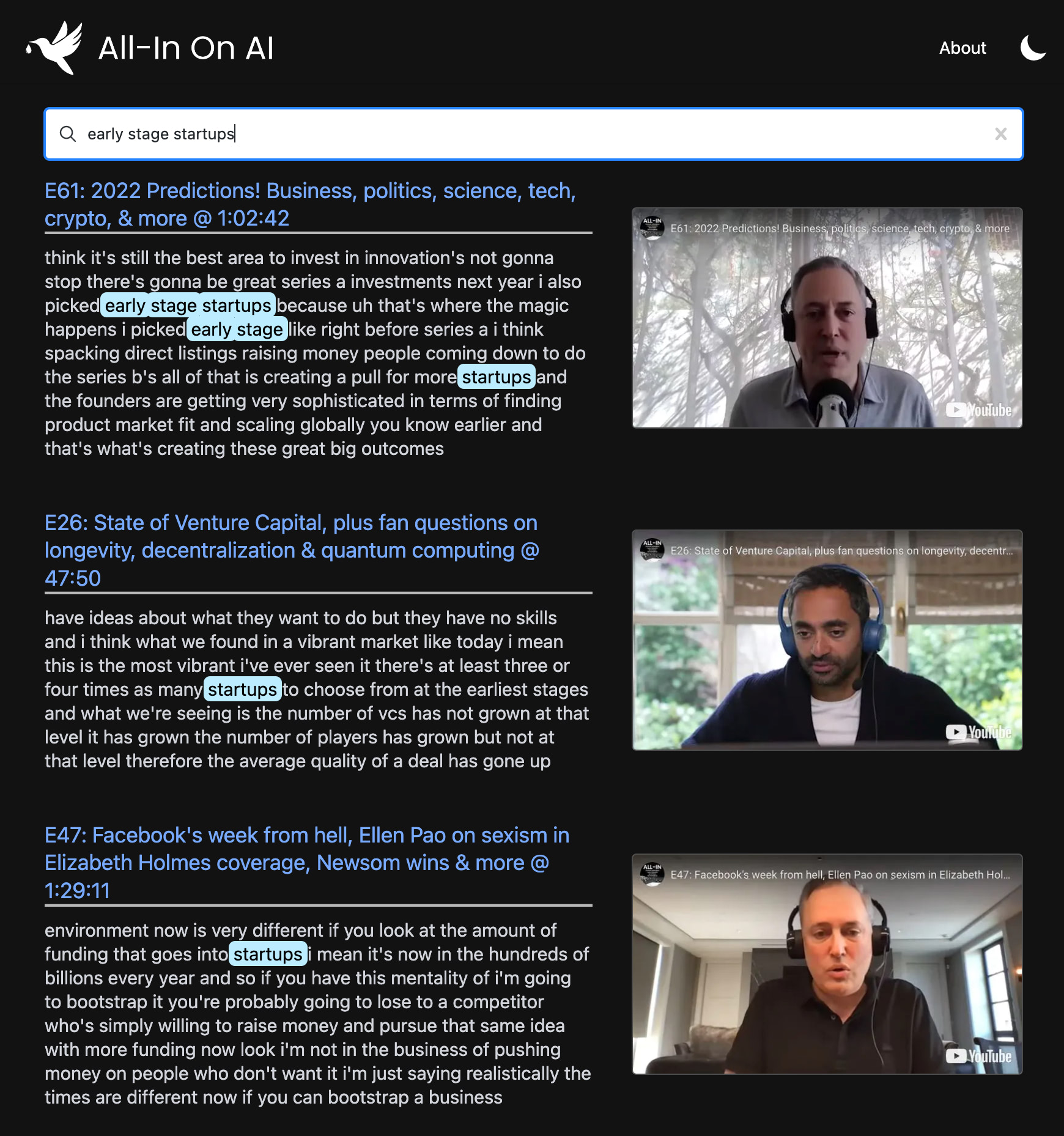
yt semantic search
1.0.0

البحث الدلالي الذي يعمل بنفط Openai عن أي قائمة تشغيل على YouTube-يتميز ببودكاست الكل في
أنا أحب البودكاست الكل في. لكن البحث والاكتشاف مع البودكاست يمكن أن يكون تحديا حقا.
لقد قمت ببناء هذا المشروع لحل هذه المشكلة ... وأردت أيضًا أن ألعب مع أشياء Cool AI. ؟
يستخدم هذا المشروع أحدث النماذج من Openai لإنشاء فهرس البحث الدلالي عبر كل حلقة من POD. يتيح لك العثور على لحظاتك المفضلة بدقة مستوى Google وإعادة مشاهدة المقاطع الدقيقة التي تهتم بها.
يمكنك استخدامه لتطوير البحث المتقدم عبر أي قناة أو قائمة تشغيل على YouTube . يستخدم العرض التوضيحي البودكاست الكل لأنه المفضل لدي؟ ، لكنه مصمم للعمل مع أي قائمة تشغيل.
npm install لتثبيت جميع التبعيات اللازمة.npx tsx src/bin/resolve-yt-playlist.ts لتنزيل النصوص الإنجليزية لكل حلقة من قائمة التشغيل الهدف (في هذه الحالة ، قائمة تشغيل حلقات البودكاست).npx tsx src/bin/process-yt-playlist.ts للمعالجة المسبقة للنصوص وجلب التضمينات من Openai ، ثم أدخلها في فهرس البحث pinecone.npx tsx src/bin/query.ts للاستعلام عن فهرس البحث Pinecone. (اختياري) قم بتشغيل الأمر npx tsx src/bin/generate-thumbnails.ts لإنشاء صور مصغرة من كل مقطع فيديو في قائمة التشغيل. تستغرق هذه الخطوة ~ ساعتين وتتطلب اتصال إنترنت مستقر.لاحظ أن بعض الحلقات قد لا تحتوي على نسخ آلية للإنجليزية ، وأن المشروع يستخدم حل كشط HTML المتسلل لهذا ، وبالتالي فإن الحل الأفضل هو استخدام Whisper لنسخ صوت الحلقة. أيضا ، دعم المشروع فرز حسب الحداثة مقابل الصلة.
تحت الغطاء ، يستخدم:
نستخدم Node.js و youtube API V3 لجلب مقاطع الفيديو الخاصة بقائمة التشغيل المستهدفة الخاصة بنا. في هذه الحالة ، نركز على قائمة تشغيل حلقات البودكاست ، والتي تحتوي على 108 مقطع فيديو في وقت كتابة هذا التقرير.
npx tsx src/bin/resolve-yt-playlist.tsنقوم بتنزيل النصوص الإنجليزية لكل حلقة باستخدام حل Drassing HTML HTML ، نظرًا لأن واجهة برمجة تطبيقات YouTube لا تسمح بالوصول إلى التسميات التوضيحية. لاحظ أن بعض الحلقات لا تتوفر نسخًا آلية للإنجليزية ، لذلك نحن فقط نتخطىها في الوقت الحالي. سيكون الحل الأفضل هو استخدام Whisper لنسخ صوت كل حلقة.
بمجرد أن يتم تنزيل جميع النصوص والبيانات الوصفية محليًا ، نقوم بتجهيز نسخ كل فيديو مسبقًا ، ونقسمها إلى قطع بحجم معقولة من ~ 100 رمز ونحضر التضمين Embedding-ADA-002 من Openai. وهذا يؤدي إلى ~ 200 تضمين لكل حلقة.
ثم يتم تناقض كل هذه التضمينات في مؤشر بحث بينيكون مع أبعاد قدره 1536. هناك حوالي 17575 تدمير في المجموع عبر 108 حلقات من البودكاست الكل.
npx tsx src/bin/process-yt-playlist.tsبمجرد إعداد فهرس البحث Pinecone الخاص بنا ، يمكننا البدء في الاستعلام عنه إما عبر WebApp أو عبر مثال CLI:
npx tsx src/bin/query.tsنحن ندعم أيضًا توليد الصور المصغرة المستندة إلى الطابع الزمني لكل فيديو على YouTube في قائمة التشغيل. يتم إنشاء Thumbnails باستخدام Puppeteer مقطوعة الرأس ويتم تحميلها على تخزين السحابة Google. نحن أيضًا نتعامل مع كل صورة مصغرة مع LQIP-Modeter لإنشاء صور نائبة معاينة لطيفة.
إذا كنت ترغب في إنشاء صور مصغرة (اختيارية) ، قم بتشغيل:
npx tsx src/bin/generate-thumbnails.tsلاحظ أن توليد الصورة المصغرة يستغرق حوالي ساعتين ويتطلب اتصال إنترنت مستقر للغاية.
الواجهة الأمامية هي webapp next.js تم نشرها في Vercel والتي تستخدم فهرس Pinecone الخاص بنا كمخزن بيانات أساسي.
هل لديك فكرة عن كيفية تحسين هذا webapp؟ هل تجد استعلام بحث ممتع بشكل خاص؟
لا تتردد في إرسال ملاحظات لي ، إما على Github أو Twitter. ؟
MIT © Travis Fischer
إذا وجدت هذا المشروع مثيرًا للاهتمام ، فيرجى التفكير في رعايتي أو متابعتي على Twitter
تضيف تكاليف API وتكاليف الخادم مع مرور الوقت ، لذلك إذا كنت تستطيع تجنيبها ، فإن الرعاية على Github موضع تقدير كبير. ؟


