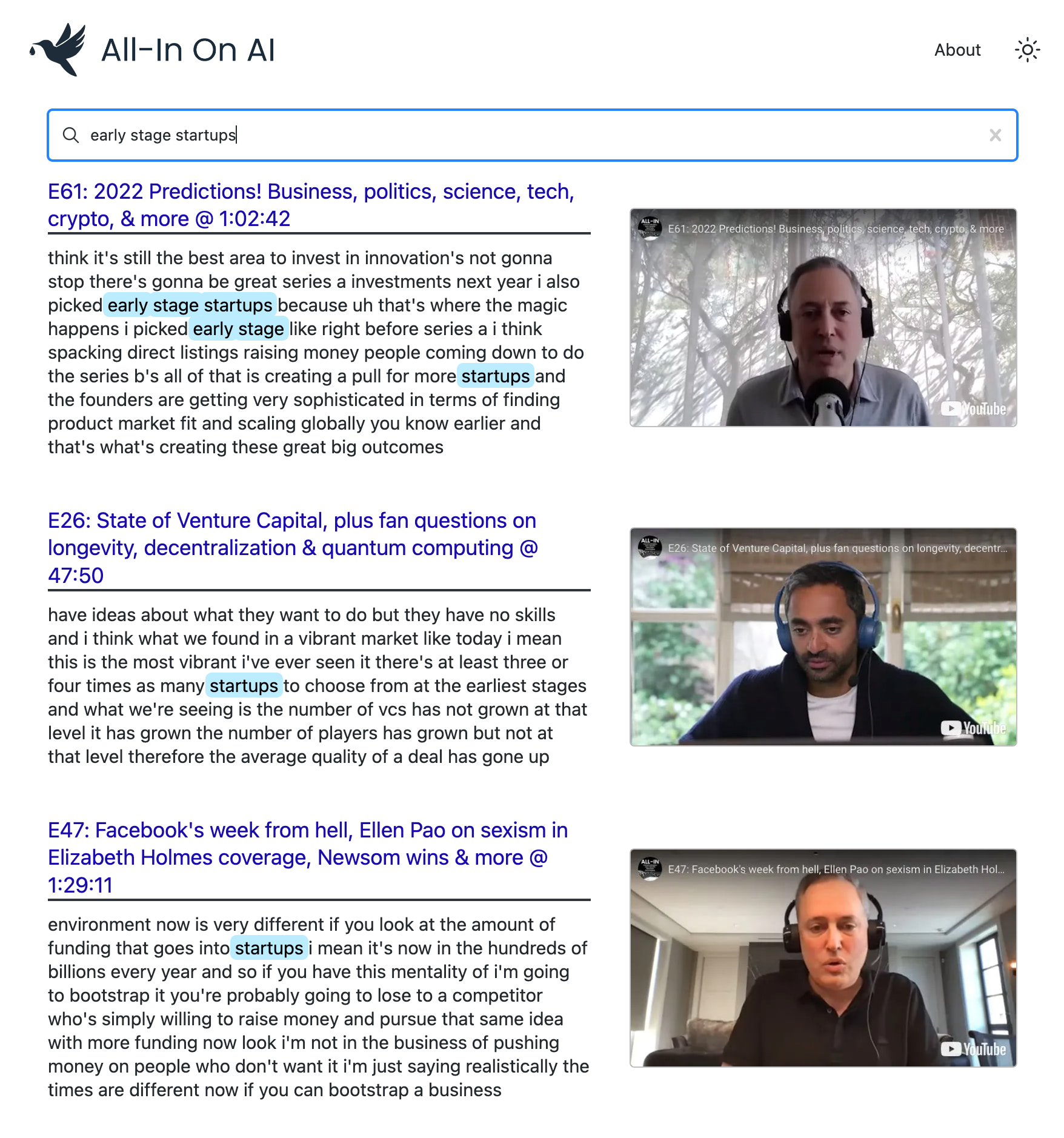
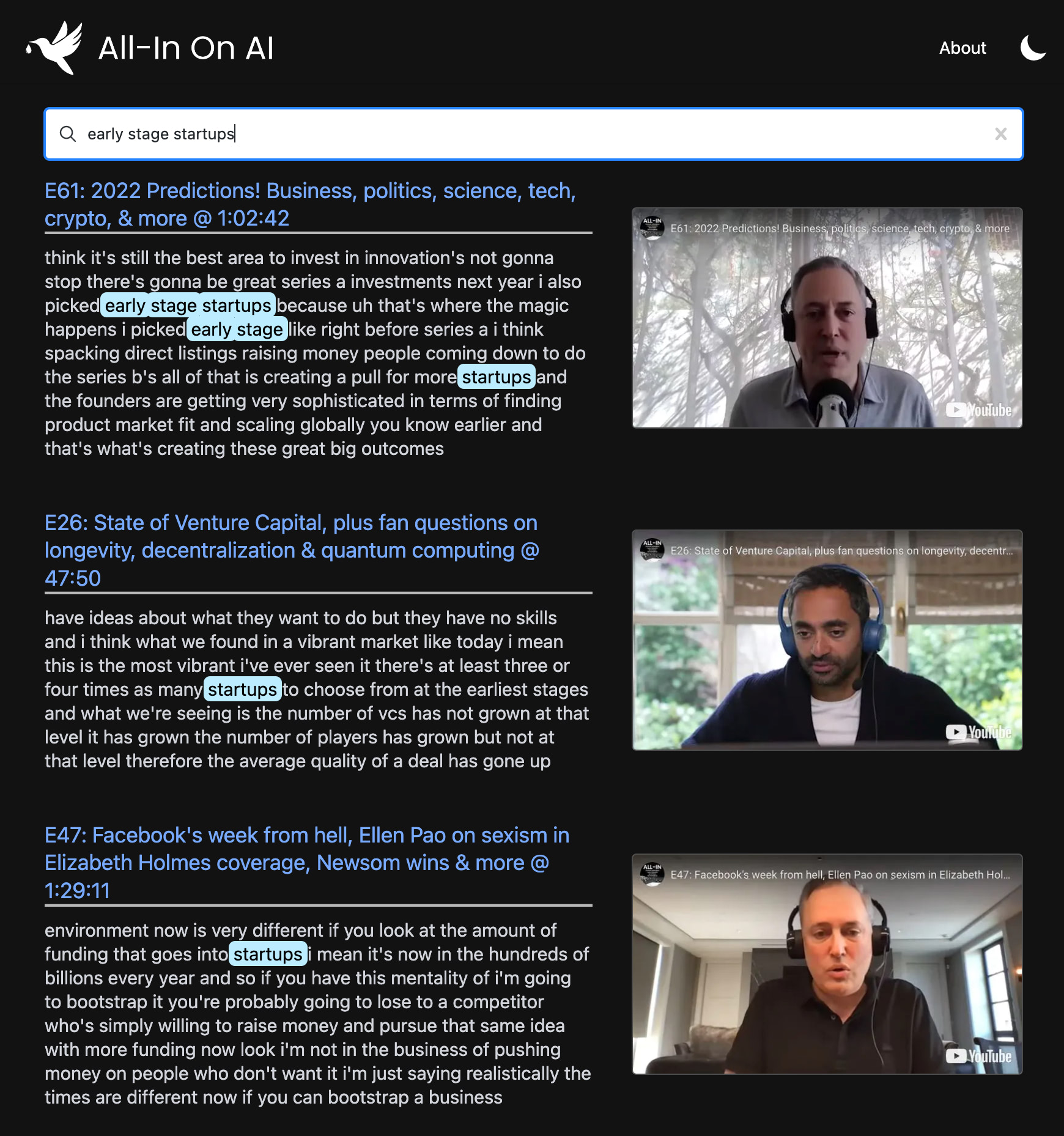
yt semantic search
1.0.0

Búsqueda semántica con energía Openai para cualquier lista de reproducción de YouTube: con el podcast All-in
Me encanta el podcast All-In. Pero la búsqueda y el descubrimiento con los podcasts pueden ser realmente desafiantes.
Construí este proyecto para resolver este problema ... y también quería jugar con cosas geniales de IA. ?
Este proyecto utiliza los últimos modelos de OpenAI para construir un índice de búsqueda semántica en cada episodio de la cápsula. Le permite encontrar sus momentos favoritos con precisión a nivel de Google y volver a ver los clips exactos que le interesa.
Puede usarlo para alimentar la búsqueda avanzada en cualquier canal o lista de reproducción de YouTube . La demostración usa el podcast All-In porque es mi favorito?, Pero está diseñado para funcionar con cualquier lista de reproducción.
npm install para instalar todas las dependencias necesarias.npx tsx src/bin/resolve-yt-playlist.ts para descargar las transcripciones en inglés para cada episodio de la lista de reproducción de destino (en este caso, la lista de reproducción de episodios de podcast All-in).npx tsx src/bin/process-yt-playlist.ts para preprocesar las transcripciones y obtener incrustaciones de OpenAI, luego inserte en un índice de búsqueda de Pinecone.npx tsx src/bin/query.ts para consultar el índice de búsqueda de pinecone. (Opcional) Ejecute el comando npx tsx src/bin/generate-thumbnails.ts para generar miniaturas de tiempo de tiempo de cada video en la lista de reproducción. Este paso toma ~ 2 horas y requiere una conexión a Internet estable.Tenga en cuenta que algunos episodios pueden no tener transcripciones automatizadas en inglés disponibles, y que el proyecto utiliza una solución de raspado HTML hacky para esto, por lo que una mejor solución sería usar Whisper para transcribir el audio del episodio. Además, la clasificación del proyecto de soporte por recencia vs relevancia.
Debajo del capó, usa:
Usamos Node.js y el API V3 de YouTube para obtener los videos de nuestra lista de reproducción de destino. En este caso, estamos enfocados en la lista de reproducción de episodios de podcast All-In, que contiene 108 videos al momento de escribir.
npx tsx src/bin/resolve-yt-playlist.tsDescargamos las transcripciones en inglés para cada episodio utilizando una solución de raspado HTML Hacky, ya que la API de YouTube no permite el acceso que no es de acuerdo a los subtítulos. Tenga en cuenta que algunos episodios no tienen transcripciones automatizadas en inglés disponibles, por lo que solo las estamos omitiendo en este momento. Una mejor solución sería usar Whisper para transcribir el audio de cada episodio.
Una vez que tenemos todas las transcripciones y metadatos descargados localmente, preprocesamos las transcripciones de cada video, dividiéndolos en trozos de tamaño razonable de ~ 100 tokens y obtenemos su incrustación de texto-ADA-002 de OpenAi. Esto da como resultado ~ 200 incrustaciones por episodio.
Todos estos incrustaciones se elevan en un índice de búsqueda de Pinecone con una dimensionalidad de 1536. Hay ~ 17,575 incrustaciones en total en ~ 108 episodios del podcast All-in.
npx tsx src/bin/process-yt-playlist.tsUna vez que se configura nuestro índice de búsqueda de pinecone, podemos comenzar a consultarlo a través de la aplicación web o a través del ejemplo de CLI:
npx tsx src/bin/query.tsTambién apoyamos la generación de miniaturas basadas en la marca de tiempo de cada video de YouTube en la lista de reproducción. Las miniaturas se generan con titiros sin cabeza y se cargan en Google Cloud Storage. También tenemos el procesamiento posterior a cada miniatura con LQIP-modern para generar buenas imágenes de marcador de posición de vista previa.
Si desea generar miniaturas (opcionales), ejecute:
npx tsx src/bin/generate-thumbnails.tsTenga en cuenta que la generación de miniatura toma ~ 2 horas y requiere una conexión a Internet bastante estable.
El frontend es una aplicación web Next.js implementada en VERCEL que usa nuestro índice Pinecone como un almacén de datos primario.
¿Tiene una idea sobre cómo podría mejorarse esta webp? ¿Encuentra una consulta de búsqueda particularmente divertida?
No dude en enviarme comentarios, ya sea en Github o Twitter. ?
MIT © Travis Fischer
Si le pareció interesante este proyecto, considere patrocinarme o seguirme en Twitter
La API y los costos del servidor se suman con el tiempo, por lo que si puede ahorrarlo, es muy apreciado patrocinar en GitHub. ?


