AMOS
v0.1.0
Этот репозиторий содержит сценарии для тонкой настройки моделей Amos, предварительно проведенных на критериях Glue и Squad 2.0.
Бумага: предварительные текстовые кодеры с состязательной смесью генераторов обучения сигналов
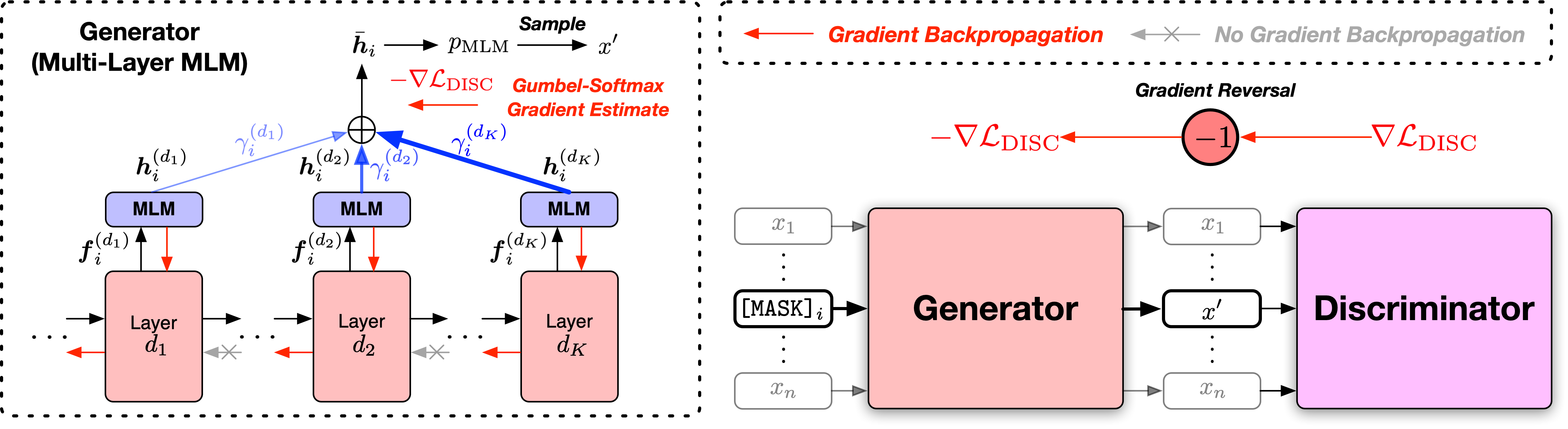
Мы предоставляем сценарии в двух версиях, основанных на двух широко используемых кодовых базах с открытым исходным кодом, библиотеки Fairseq и библиотеки Transformers HuggingFace. Две кодовые версии в основном эквивалентны функциональности, и вы можете использовать любой из них. Тем не менее, мы отмечаем, что версия Fairseq - это то, что мы использовали в наших экспериментах, и она лучше всего воспроизводит результаты в статье; Версия Huggingface реализована позже, чтобы обеспечить совместимость с библиотекой Trangingface Transformers, и может дать немного разные результаты.
Пожалуйста, следуйте файлам readme в соответствии с двумя каталогами для запуска кода.
Оценка общего языка (клей).
Glue Dev Установите результаты модели Amos Base ++ следующие (медиана из 5 различных случайных семян):
| Модель | Mnli-m/mm | QQP | Qnli | SST-2 | Кола | Rte | MRPC | STS-B | Ав |
|---|---|---|---|---|---|---|---|---|---|
| Amos Base ++ | 90,5/90,4 | 92.4 | 94.4 | 95,5 | 71.8 | 86.6 | 91.7 | 92.0 | 89.4 |
Результаты теста на клей результаты модели AMOS Base ++ следующие (без ансамбля, уловки для конкретных задач и т. Д.):
| Модель | Mnli-m/mm | QQP | Qnli | SST-2 | Кола | Rte | MRPC | STS-B | Ав |
|---|---|---|---|---|---|---|---|---|---|
| Amos Base ++ | 90,4/89,9 | 90.2 | 94.6 | 96.8 | 69,2 | 83,6 | 88.9 | 91.3 | 88.1 |
Стэнфордский набор данных ответа на вопрос (Squad) - это набор данных по пониманию прочитанного, состоящий из вопросов, заданных толщинами, на наборе статей Википедии, где ответ на каждый вопрос представляет собой сегмент текста или пролета, из соответствующего отрывка для чтения, или вопрос может быть без ответа.
Squad 2.0 Dev Set Результаты моделей Amos Base ++ и больших ++ следующие (медиана из 5 различных случайных семян):
| Модель | ЭМ | F1 |
|---|---|---|
| Amos Base ++ | 85,0 | 87.9 |
Если вы найдете код и модели, полезные для исследования, пожалуйста, укажите следующую статью:
@inproceedings{meng2022amos,
title={Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators},
author={Meng, Yu and Xiong, Chenyan and Bajaj, Payal and Tiwary, Saurabh and Bennett, Paul and Han, Jiawei and Song, Xia},
booktitle={International Conference on Learning Representations},
year={2022}
}
Этот проект приветствует вклады и предложения. Большинство взносов требуют, чтобы вы согласились с лицензионным соглашением о участнике (CLA), заявив, что вы имеете право и фактически предоставить нам права на использование вашего вклада. Для получения подробной информации, посетите https://cla.opensource.microsoft.com.
Когда вы отправляете запрос на привлечение, бот CLA автоматически определит, нужно ли вам предоставить CLA и правильно украсить PR (например, проверка состояния, комментарий). Просто следуйте инструкциям, предоставленным ботом. Вам нужно будет сделать это только один раз во всех репо, используя наш CLA.
Этот проект принял код поведения с открытым исходным кодом Microsoft. Для получения дополнительной информации см. Кодекс поведения FAQ или свяжитесь с [email protected] с любыми дополнительными вопросами или комментариями.


