AMOS
v0.1.0
このリポジトリには、接着剤および分隊2.0ベンチマーク上のAMOS事前処理されたモデルを微調整するためのスクリプトが含まれています。
論文:トレーニング信号ジェネレーターの敵対的な混合物を備えた事前削除テキストエンコーダー
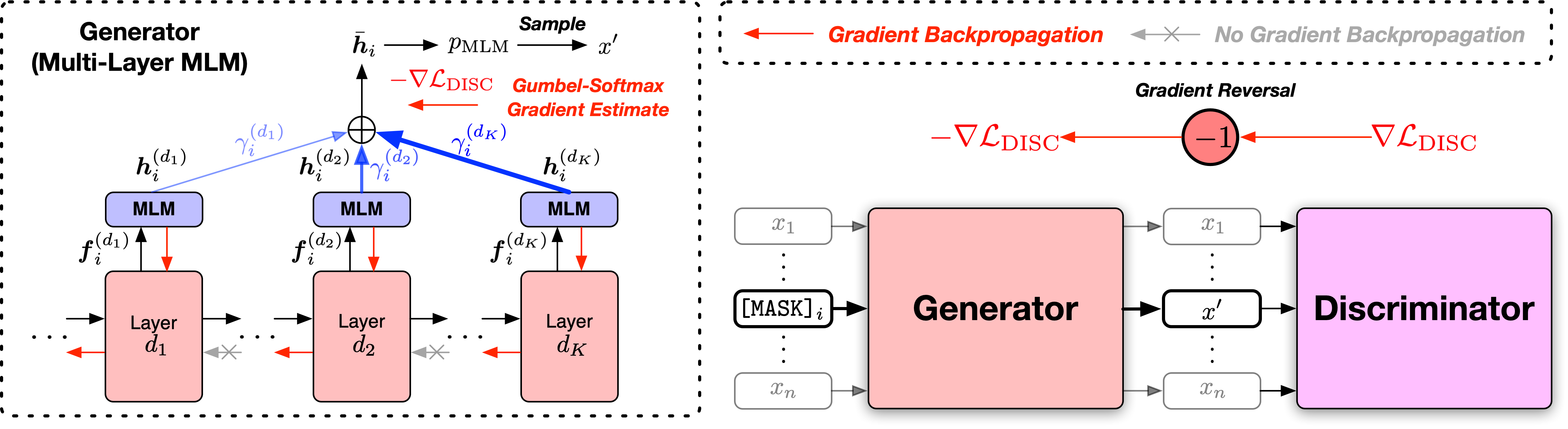
2つの広く使用されているオープンソースコードベース、FairSeqライブラリとHuggingface Transformersライブラリに基づいて、2つのバージョンでスクリプトを提供します。 2つのコードバージョンは機能がほとんど同等であり、それらのいずれかを自由に使用できます。ただし、FairSeqバージョンは実験で使用したものであり、その結果を論文で再現するのが最適であることに注意してください。 Huggingfaceバージョンは後で実装され、Huggingface Transformersライブラリとの互換性を提供し、わずかに異なる結果が得られる場合があります。
コードを実行するために、2つのディレクトリの下のReadMeファイルに従ってください。
一般的な言語理解評価(接着剤)ベンチマークは、自然言語理解システムを評価および分析するための文または文のペア理解タスクのコレクションです。
接着剤DEVセットAMOSベース++モデルの結果は次のとおりです(5つの異なるランダムシードの中央値):
| モデル | mnli-m/mm | QQP | Qnli | SST-2 | コーラ | rte | MRPC | sts-b | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| AMOSベース++ | 90.5/90.4 | 92.4 | 94.4 | 95.5 | 71.8 | 86.6 | 91.7 | 92.0 | 89.4 |
接着剤テストセットAMOSベース++モデルの結果は次のとおりです(アンサンブル、タスク固有のトリックなど):
| モデル | mnli-m/mm | QQP | Qnli | SST-2 | コーラ | rte | MRPC | sts-b | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| AMOSベース++ | 90.4/89.9 | 90.2 | 94.6 | 96.8 | 69.2 | 83.6 | 88.9 | 91.3 | 88.1 |
Stanfordの質問Dataset(Squad)は読解データセットであり、Wikipediaの記事のセットで群衆労働者が提起した質問で構成されています。すべての質問に対する答えは、対応する読み取りの文章からのテキストまたはスパンのセグメントであるか、質問が答えられない場合があります。
Squad 2.0 DEV DEV SET AMOS BASE ++および大規模++モデルの結果は次のとおりです(5つの異なるランダムシードの中央値):
| モデル | em | F1 |
|---|---|---|
| AMOSベース++ | 85.0 | 87.9 |
コードとモデルが研究に役立つ場合は、次の論文を引用してください。
@inproceedings{meng2022amos,
title={Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators},
author={Meng, Yu and Xiong, Chenyan and Bajaj, Payal and Tiwary, Saurabh and Bennett, Paul and Han, Jiawei and Song, Xia},
booktitle={International Conference on Learning Representations},
year={2022}
}
このプロジェクトは、貢献と提案を歓迎します。ほとんどの貢献では、貢献者ライセンス契約(CLA)に同意する必要があります。詳細については、https://cla.opensource.microsoft.comをご覧ください。
プルリクエストを送信すると、CLAボットはCLAを提供し、PRを適切に飾る必要があるかどうかを自動的に決定します(たとえば、ステータスチェック、コメント)。ボットが提供する指示に従うだけです。 CLAを使用して、すべてのレポでこれを1回だけ行う必要があります。
このプロジェクトは、Microsoftのオープンソース行動規範を採用しています。詳細については、FAQのコードを参照するか、追加の質問やコメントについては[email protected]にお問い合わせください。


