AMOS
v0.1.0
Este repositório contém os scripts para modelos AMOS de ajuste fino na cola e os benchmarks de cola 2.0.
Papel: codificadores de texto pré -treinamento com mistura adversária de geradores de sinal de treinamento
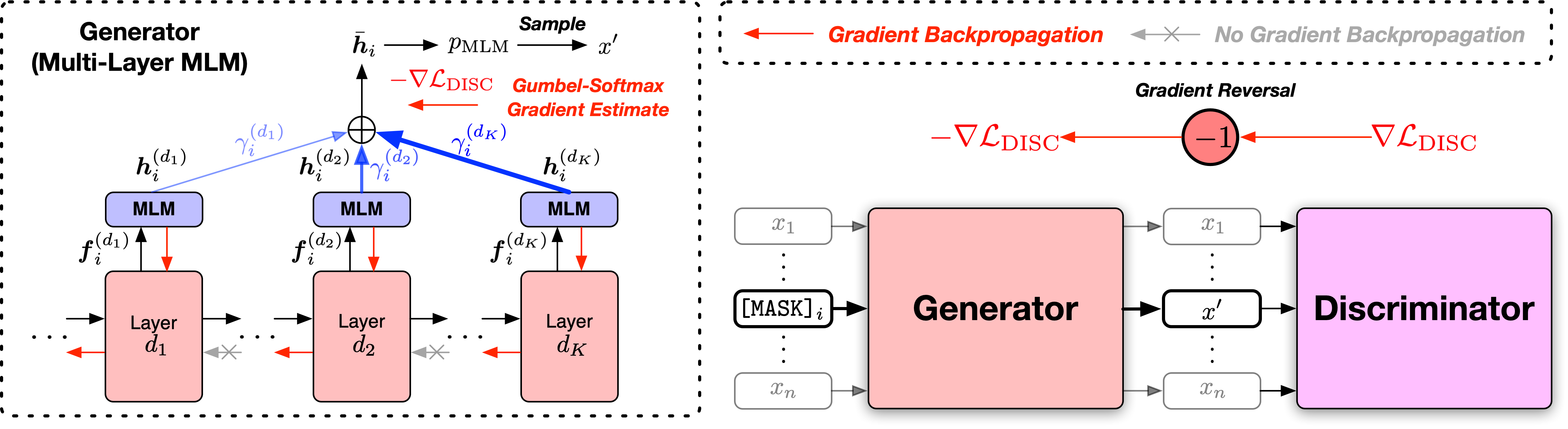
Fornecemos os scripts em duas versões, com base em duas bases de código de código aberto amplamente usadas, a Biblioteca Fairseq e a Biblioteca de Transformers do Huggingface. As duas versões de código são principalmente equivalentes em funcionalidade e você é livre para usar qualquer uma delas. No entanto, observamos que a versão Fairseq é o que usamos em nossos experimentos e melhor reproduzirá os resultados no artigo; A versão Huggingface é implementada posteriormente para fornecer compatibilidade com a Biblioteca de Transformers do Huggingface e pode produzir resultados ligeiramente diferentes.
Siga os arquivos ReadMe nos dois diretórios para executar o código.
O benchmark de avaliação de Entendendo a Linguagem Geral (CLUE) é uma coleção de tarefas de compreensão de idiomas de frases ou pares de frases para avaliar e analisar sistemas de compreensão de linguagem natural.
Glue Dev definido os resultados do modelo AMOS Base ++ são os seguintes (mediana de 5 sementes aleatórias diferentes):
| Modelo | Mnli-m/mm | Qqp | Qnli | SST-2 | Cola | Rte | Mrpc | STS-B | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Amos base ++ | 90.5/90.4 | 92.4 | 94.4 | 95.5 | 71.8 | 86.6 | 91.7 | 92.0 | 89.4 |
Os resultados do conjunto de testes de cola do modelo AMOS Base ++ são os seguintes (sem conjunto, truques específicos de tarefas, etc.):
| Modelo | Mnli-m/mm | Qqp | Qnli | SST-2 | Cola | Rte | Mrpc | STS-B | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Amos base ++ | 90.4/89.9 | 90.2 | 94.6 | 96.8 | 69.2 | 83.6 | 88.9 | 91.3 | 88.1 |
O conjunto de dados de resposta a Stanford para resposta a Stanford é um conjunto de dados de compreensão de leitura, consistindo em perguntas colocadas pelos trabalhadores de multidão em um conjunto de artigos da Wikipedia, onde a resposta para todas as perguntas é um segmento de texto ou extensão, da passagem de leitura correspondente, ou a pergunta pode ser insensível.
Esquadrão 2.0 Definir os resultados dos modelos AMOS Base ++ e Grande ++ são os seguintes (mediana de 5 sementes aleatórias diferentes):
| Modelo | Em | F1 |
|---|---|---|
| Amos base ++ | 85.0 | 87.9 |
Se você achar o código e os modelos úteis para sua pesquisa, cite o seguinte artigo:
@inproceedings{meng2022amos,
title={Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators},
author={Meng, Yu and Xiong, Chenyan and Bajaj, Payal and Tiwary, Saurabh and Bennett, Paul and Han, Jiawei and Song, Xia},
booktitle={International Conference on Learning Representations},
year={2022}
}
Este projeto recebe contribuições e sugestões. A maioria das contribuições exige que você concorde com um Contrato de Licença de Colaborador (CLA) declarando que você tem o direito e, na verdade, concede -nos os direitos de usar sua contribuição. Para detalhes, visite https://cla.opensource.microsoft.com.
Quando você envia uma solicitação de tração, um BOT do CLA determina automaticamente se você precisa fornecer um CLA e decorar o PR adequadamente (por exemplo, verificação de status, comentar). Simplesmente siga as instruções fornecidas pelo bot. Você só precisará fazer isso uma vez em todos os repositórios usando nosso CLA.
Este projeto adotou o Código de Conduta Open Microsoft. Para obter mais informações, consulte o Código de Conduta Perguntas frequentes ou entre em contato com [email protected] com quaisquer perguntas ou comentários adicionais.


