AMOS
v0.1.0
يحتوي هذا المستودع على البرامج النصية لضبط نماذج Amos التمهيدية على معايير الغراء و Squad 2.0.
الورق: ترميز النص المسبق مع مزيج عدواني من مولدات إشارة التدريب
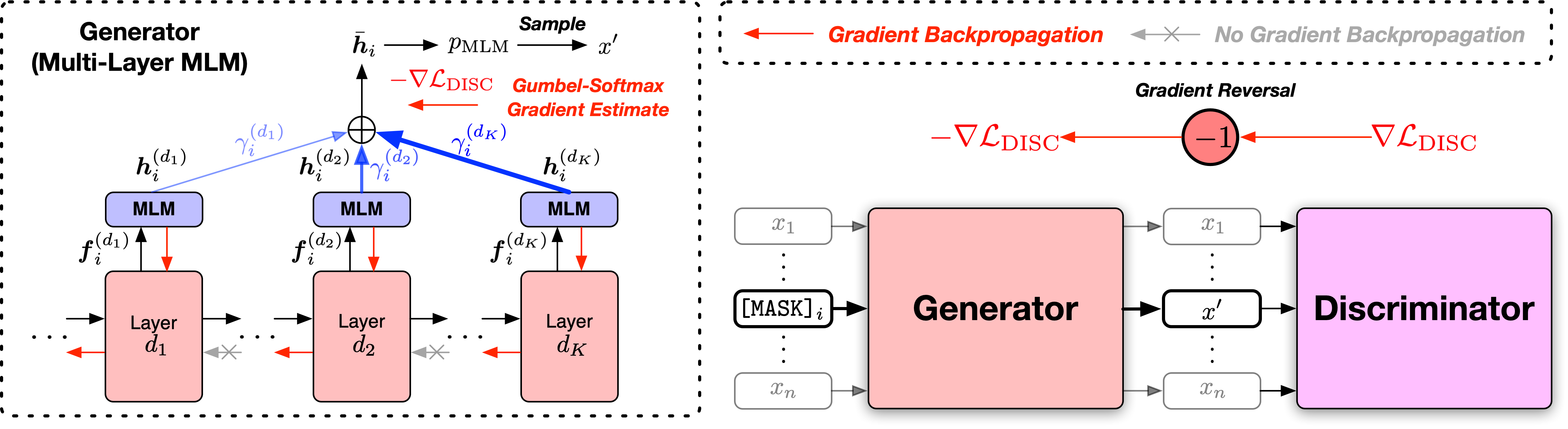
نحن نقدم البرامج النصية في نسختين ، استنادًا إلى اثنين من قواعد الكود مفتوحة المصدر المستخدمة على نطاق واسع ، ومكتبة Fairseq ومكتبة Huggingface Transformers. نسختان من الكود مكافئ في الغالب في الوظائف ، وأنت حر في استخدام أي منهما. ومع ذلك ، نلاحظ أن إصدار FairSeq هو ما استخدمناه في تجاربنا ، وسيؤدي إلى إعادة إنتاج النتائج في الورقة بشكل أفضل ؛ يتم تنفيذ إصدار HuggingFace لاحقًا لتوفير التوافق مع مكتبة HuggingFace Transformers ، وقد تسفر عن نتائج مختلفة قليلاً.
يرجى اتباع ملفات ReadMe ضمن الدليلين لتشغيل الرمز.
إن تقييم فهم اللغة العامة (GLUE) هو مجموعة من مهام فهم لغة الجملة أو الجملة من الجملة لتقييم أنظمة فهم اللغة الطبيعية وتحليلها.
Glue Dev Set نتائج نموذج AMOS BASE ++ هي كما يلي (متوسط 5 بذور عشوائية مختلفة):
| نموذج | mnli-m/mm | QQP | qnli | SST-2 | كولا | RTE | MRPC | STS-B | متوسط |
|---|---|---|---|---|---|---|---|---|---|
| Amos Base ++ | 90.5/90.4 | 92.4 | 94.4 | 95.5 | 71.8 | 86.6 | 91.7 | 92.0 | 89.4 |
نتائج اختبار Glue Test لنموذج AMOS BASE ++ هي كما يلي (بدون مجموعة ، حيل خاصة بالمهمة ، إلخ):
| نموذج | mnli-m/mm | QQP | qnli | SST-2 | كولا | RTE | MRPC | STS-B | متوسط |
|---|---|---|---|---|---|---|---|---|---|
| Amos Base ++ | 90.4/89.9 | 90.2 | 94.6 | 96.8 | 69.2 | 83.6 | 88.9 | 91.3 | 88.1 |
Stanford Question Repling DataSet (Squad) هي مجموعة بيانات فهم للقراءة ، تتكون من أسئلة طرحها عمال الحشد على مجموعة من مقالات ويكيبيديا ، حيث قد تكون الإجابة على كل سؤال عبارة عن جزء من النص ، أو تمتد ، من مقطع القراءة المقابل ، أو قد يكون السؤال غير قابل للإجابة.
Squad 2.0 DEV SET نتائج AMOS BASE ++ ونماذج ++ كبيرة هي كما يلي (متوسط من 5 بذور عشوائية مختلفة):
| نموذج | م | F1 |
|---|---|---|
| Amos Base ++ | 85.0 | 87.9 |
إذا وجدت الرمز والنماذج مفيدة لبحثك ، فيرجى الاستشهاد بالورقة التالية:
@inproceedings{meng2022amos,
title={Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators},
author={Meng, Yu and Xiong, Chenyan and Bajaj, Payal and Tiwary, Saurabh and Bennett, Paul and Han, Jiawei and Song, Xia},
booktitle={International Conference on Learning Representations},
year={2022}
}
يرحب هذا المشروع بالمساهمات والاقتراحات. تطلب منك معظم المساهمات الموافقة على اتفاقية ترخيص المساهم (CLA) مع إعلان أن لديك الحق في ذلك في الواقع ، ويفعلنا في الواقع حقوق استخدام مساهمتك. لمزيد من التفاصيل ، تفضل بزيارة https://cla.opensource.microsoft.com.
عند إرسال طلب سحب ، سيحدد CLA Bot تلقائيًا ما إذا كنت بحاجة إلى توفير CLA وتزيين العلاقات العامة بشكل مناسب (على سبيل المثال ، فحص الحالة ، التعليق). ببساطة اتبع الإرشادات التي يقدمها الروبوت. ستحتاج فقط إلى القيام بذلك مرة واحدة عبر جميع عمليات إعادة الشراء باستخدام CLA لدينا.
اعتمد هذا المشروع رمز سلوك المصدر المفتوح Microsoft. لمزيد من المعلومات ، راجع مدونة الشهادة الأسئلة الشائعة أو الاتصال بـ [email protected] مع أي أسئلة أو تعليقات إضافية.


