AMOS
v0.1.0
Dieses Repository enthält die Skripte für die fein abgestimmten AMOS-Modelle für Kleber- und Kader 2.0-Benchmarks.
Papier: Vorbereitungs -Text -Encoder mit kontroversem Gemisch von Trainingssignalgeneratoren
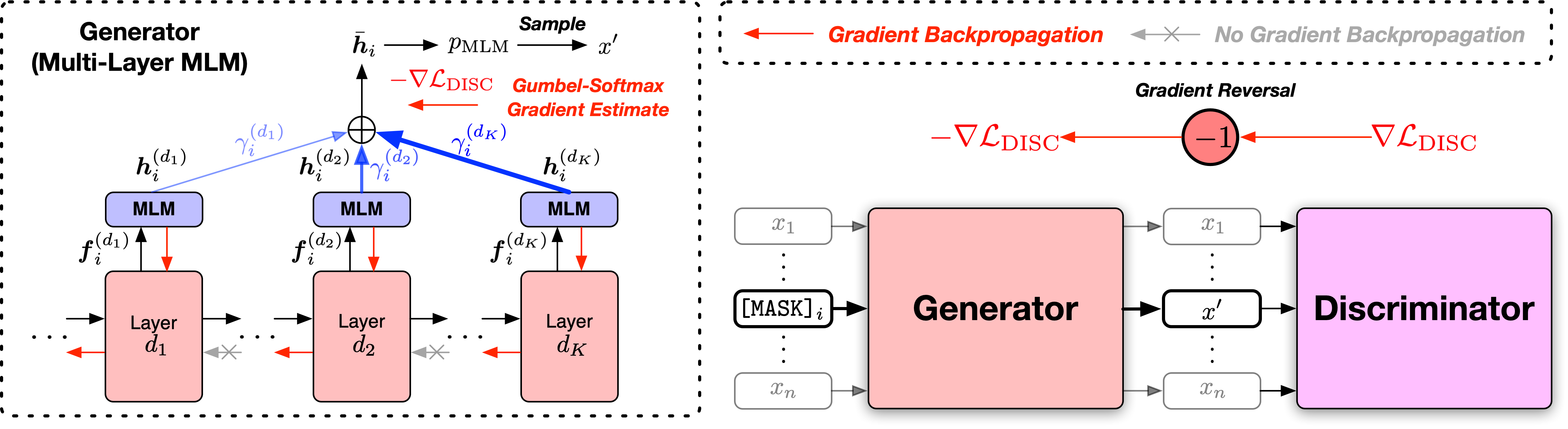
Wir stellen die Skripte in zwei Versionen an, basierend auf zwei weit verbreiteten Open-Source-Codebasen, der Fairseq-Bibliothek und der Bio-Bibliothek von Suggingface-Transformatoren. Die beiden Codeversionen entsprechen hauptsächlich in der Funktionalität, und Sie können einen von beiden verwenden. Wir stellen jedoch fest, dass die Fairseq -Version das ist, was wir in unseren Experimenten verwendet haben, und sie wird die Ergebnisse in der Arbeit am besten reproduzieren. Die Huggingface -Version wird später implementiert, um die Kompatibilität mit der Suggingface -Transformatoren -Bibliothek zu verleihen, und kann leicht unterschiedliche Ergebnisse liefern.
Bitte befolgen Sie die Readme -Dateien unter den beiden Verzeichnissen, um den Code auszuführen.
Die allgemeine Benchmark für die Bewertung des allgemeinen Sprachverständnisses ist eine Sammlung von Aufgaben zum Verständnis von Satz- oder Satzpaaren zur Bewertung und Analyse von Systemen für das Verständnis der natürlichen Sprache.
Die Ergebnisse des Amos -Basis ++ -Modells sind wie folgt (Median von 5 verschiedenen zufälligen Samen):
| Modell | Mnli-M/mm | QQP | Qnli | SST-2 | Cola | Rte | MRPC | STS-B | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Amos Base ++ | 90.5/90.4 | 92.4 | 94.4 | 95,5 | 71,8 | 86.6 | 91.7 | 92.0 | 89,4 |
Die Ergebnisse des Amos-Basis ++ -Modells sind wie folgt (kein Ensemble, aufgabenspezifische Tricks usw.):
| Modell | Mnli-M/mm | QQP | Qnli | SST-2 | Cola | Rte | MRPC | STS-B | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Amos Base ++ | 90.4/89.9 | 90.2 | 94.6 | 96,8 | 69.2 | 83.6 | 88,9 | 91.3 | 88.1 |
Stanford Question Beantwortung des Datensatzes (Squad) ist ein Leseverständnis -Datensatz, der aus Fragen von Crowdworkern auf einer Reihe von Wikipedia -Artikeln besteht, in denen die Antwort auf jede Frage ein Segment von Texten oder Spannweite aus der entsprechenden Lesepassage ist oder die Frage möglicherweise unanständig ist.
Squad 2.0 Dev Set -Ergebnisse von Amos Base ++ und Large ++ -Modellen sind wie folgt (Median von 5 verschiedenen zufälligen Samen):
| Modell | Em | F1 |
|---|---|---|
| Amos Base ++ | 85.0 | 87,9 |
Wenn Sie den Code und die Modelle finden, die für Ihre Forschung nützlich sind, geben Sie bitte das folgende Papier an:
@inproceedings{meng2022amos,
title={Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators},
author={Meng, Yu and Xiong, Chenyan and Bajaj, Payal and Tiwary, Saurabh and Bennett, Paul and Han, Jiawei and Song, Xia},
booktitle={International Conference on Learning Representations},
year={2022}
}
Dieses Projekt begrüßt Beiträge und Vorschläge. In den meisten Beiträgen müssen Sie einer Mitarbeiters Lizenzvereinbarung (CLA) zustimmen, in der Sie erklären, dass Sie das Recht haben und uns tatsächlich tun, um uns die Rechte zu gewähren, Ihren Beitrag zu verwenden. Weitere Informationen finden Sie unter https://cla.opensource.microsoft.com.
Wenn Sie eine Pull -Anfrage einreichen, bestimmt ein CLA -Bot automatisch, ob Sie einen CLA angeben und die PR angemessen dekorieren müssen (z. B. Statusprüfung, Kommentar). Befolgen Sie einfach die vom Bot bereitgestellten Anweisungen. Sie müssen dies nur einmal über alle Repos mit unserem CLA tun.
Dieses Projekt hat den Microsoft Open Source -Verhaltenscode übernommen. Weitere Informationen finden Sie im FAQ oder wenden Sie sich an [email protected] mit zusätzlichen Fragen oder Kommentaren.


