DCTTS (глубокие сверточные TTS) - внедрение Pytorch
Бумага: Эффективно обучаемая система текста в речь на основе глубоких сверточных сетей с руководством внимания
Условие
- Python 3.6
- Pytorch 1.0
- Librosa, Scipy, TQDM, Tensorboardx
Набор данных
- LJ Речь 1.1, Женский набор данных с одиночным динамиком.
- Я следую за репозицией Kyubyong Dctts с Tensorflow для предварительных обработок данных речевого сигнала. Это действительно работало хорошо.
Использование
Загрузите приведенный выше набор данных и измените путь в config.py. А затем запустите команду ниже. 1 -й Arg: сигнал Prefro, 2 -й Arg: метаданные (разделение поезда/теста)
DCTTS имеет две модели. Во -первых, вы должны тренировать модель Text2mel. Я думаю, что шаг 20K достаточно (всего час). Но вы должны тренировать модель все больше и больше с распадающейся потерей внимания.
python train.py 1 <gpu_id>
Во -вторых, тренировать SSRN. Выходы SSRN представляют собой много данных высокого разрешения. Таким образом, обучение SSRN медленнее, чем обучение Text2mel
python train.py 2 <gpu_id>
После обучения вы можете синтезировать речь из текста.
python synthesize.py <gpu_id>
Внимание
- В синтезе речи важен модуль внимания. Если модель обычно обучается, то вы можете увидеть монотонное внимание, как и следующие фигуры.
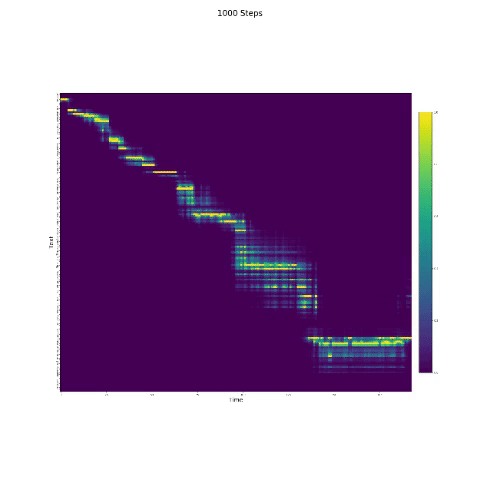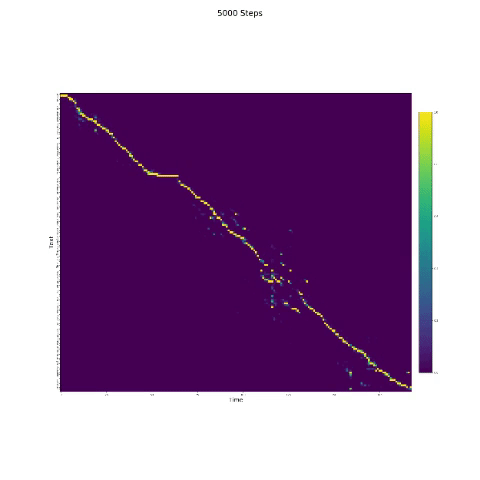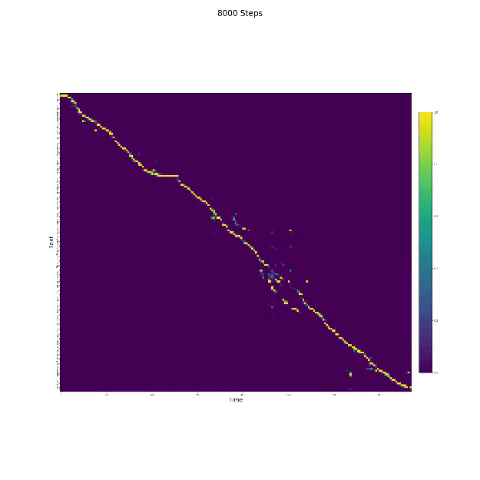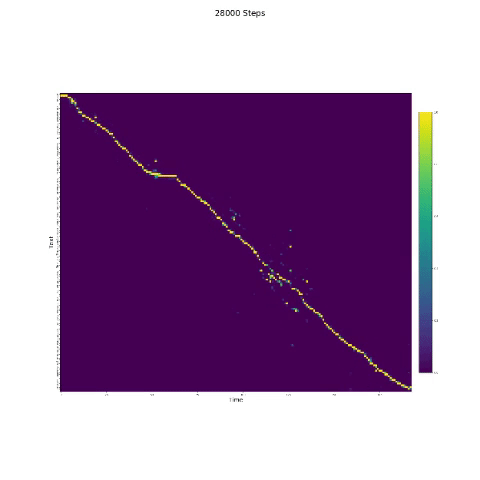
Примечания
- Сделать: предыдущее внимание к выводу.
- Сделать: облегчить переживание.
- В статье они не ссылались на нормализацию. Поэтому я использовал нормализацию веса, как DeepVoice3.
- Некоторые гиперпараметры разные.
- Если вы хотите улучшить производительность, вы должны использовать все данные. Для некоторых различных экспериментов я отделил учебный набор и набор проверки.
Другие коды
- Другая реализация питорха
- Реализация TensorFlow


