DCTTS (TTS convolucional profundo) - Implementación de Pytorch
Documento: sistema de texto a voz eficiente basado en redes convolucionales profundas con atención guiada
Requisito previo
- Python 3.6
- Pytorch 1.0
- Librosa, Scipy, TQDM, TensorBoardX
Conjunto de datos
- Discurso LJ 1.1, conjunto de datos de altavoces individuales femeninos.
- Sigo el repositorio DCTTS de Kyubyong con TensorFlow para preprocesar datos de señal de voz. En realidad funcionó bien.
Uso
Descargue el conjunto de datos anterior y modifique la ruta en config.py. Y luego ejecute el siguiente comando. 1st Arg: Signal Prepro, 2º Arg: metadatos (división de tren/prueba)
DCTTS tiene dos modelos. En primer lugar, debe entrenar el modelo Text2Mel. Creo que el paso de 20k es suficiente (solo una hora). Pero debe entrenar el modelo cada vez más con la pérdida de atención guiada en descomposición.
python train.py 1 <gpu_id>
En segundo lugar, entrena el SSRN. Las salidas de SSRN son muchos datos de alta resolución. Entonces el entrenamiento SSRN es más lento que el texto de entrenamiento2mel
python train.py 2 <gpu_id>
Después de la capacitación, puede sintetizar algún discurso del texto.
python synthesize.py <gpu_id>
Atención
- En la síntesis del habla, el módulo de atención es importante. Si el modelo normalmente está entrenado, entonces puede ver la atención monotónica como las figuras siguientes.
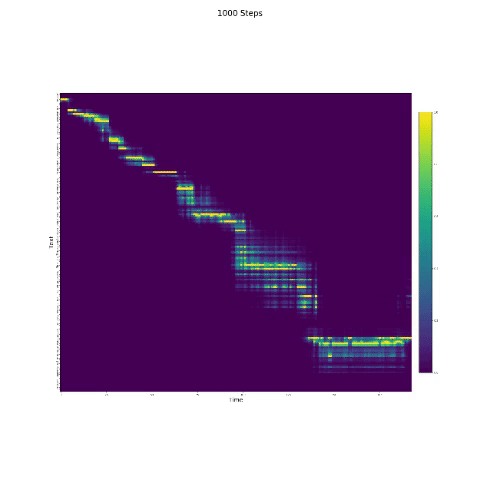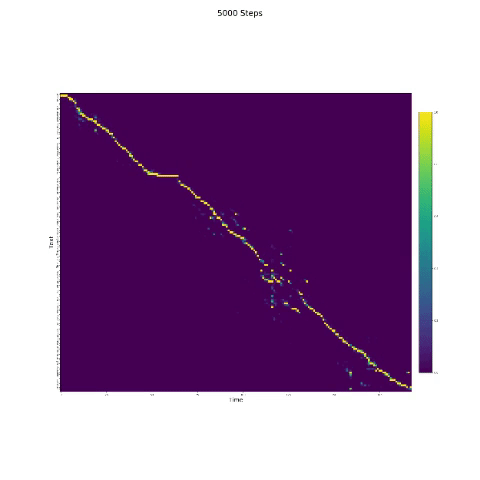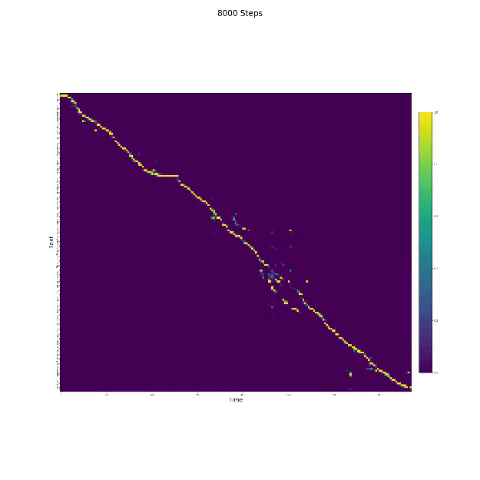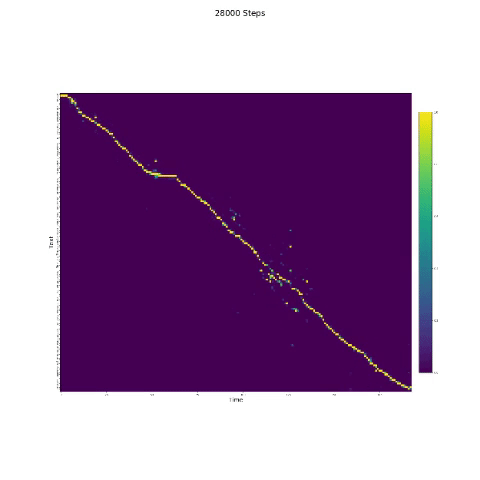
Notas
- Para hacer: atención previa por inferencia.
- Para hacer: aliviar el sobreajuste.
- En el documento, no refirieron la normalización. Entonces usé la normalización de peso como DeepVoice3.
- Algunos hiperparámetros son diferentes.
- Si desea mejorar el rendimiento, debe usar todos los datos. Para algunos experimentos, separé el conjunto de entrenamiento y el conjunto de validación.
Otros códigos
- Otra implementación de Pytorch
- Implementación de TensorFlow


