DCTTS (Deep Figolational TTS) - Pytorch -Implementierung
Papier: Effizient trainierbares Text-zu-Sprach-System basierend auf tiefen Faltungsnetzen mit geführter Aufmerksamkeit
Voraussetzung
- Python 3.6
- Pytorch 1.0
- Librosa, Scipy, TQDM, Tensorboardx
Datensatz
- LJ Speech 1.1, weiblicher Einzelsprecher -Datensatz.
- Ich folge Kyubyongs DCTTS -Repo mit Tensorflow für die Vorverarbeitung Sprachsignaldaten. Es hat tatsächlich gut funktioniert.
Verwendung
Laden Sie den obigen Datensatz herunter und ändern Sie den Pfad in config.py. Und dann den folgenden Befehl ausführen. 1. ARG: Signalprepro, 2. Arg: Metadaten (Zug/Testsplit)
DCTTS hat zwei Modelle. Zunächst sollten Sie das Modell Text2mel trainieren. Ich denke, dieser 20k -Schritt ist ausreichend (nur eine Stunde). Aber Sie sollten das Modell immer mehr mit verfallener geführter Aufmerksamkeitsverlust trainieren.
python train.py 1 <gpu_id>
Zweitens trainieren Sie die SSRN. Die Ausgänge von SSRN sind viele hochauflösende Daten. Das Training von SSRN ist also langsamer als Training Text2Mel
python train.py 2 <gpu_id>
Nach dem Training können Sie eine Sprache aus dem Text synthetisieren.
python synthesize.py <gpu_id>
Aufmerksamkeit
- In der Sprachsynthese ist das Aufmerksamkeitsmodul wichtig. Wenn das Modell normalerweise trainiert ist, können Sie die monotonische Aufmerksamkeit wie die folgenden Zahlen sehen.
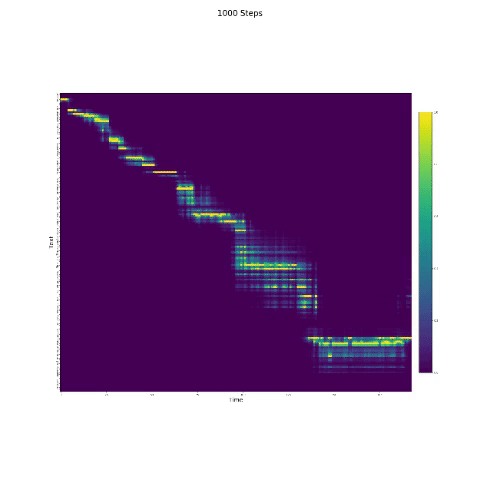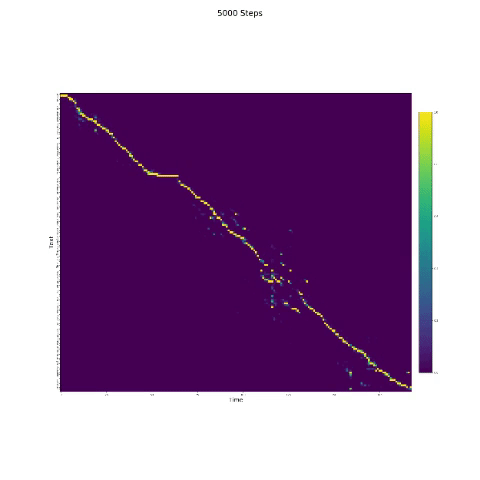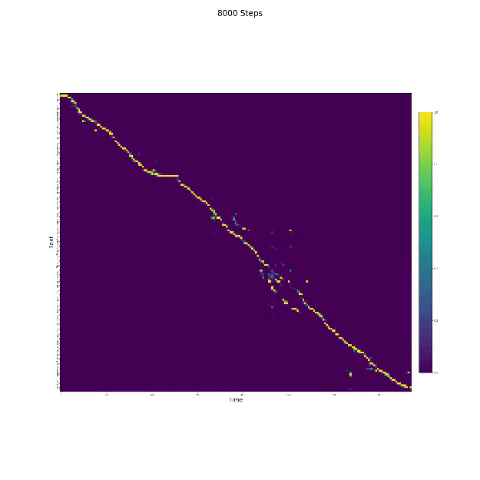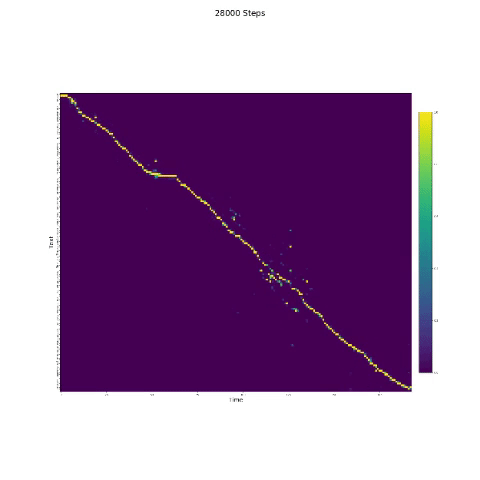
Notizen
- Zu tun: vorherige Aufmerksamkeit für Inferenz.
- Zu tun: die Überanpassung lindern.
- In der Arbeit haben sie keine Normalisierung bezogen. Also habe ich Gewichtnormalisierung wie DeepVoice3 verwendet.
- Einige Hyperparameter sind unterschiedlich.
- Wenn Sie die Leistung verbessern möchten, sollten Sie alle Daten verwenden. Für einige verschiedene Experimente habe ich den Trainingssatz und den Validierungssatz getrennt.
Andere Codes
- Eine weitere Pytorch -Implementierung
- Tensorflow -Implementierung


